Command Palette
Search for a command to run...
Nach Der Lektüre Des DALL-E-Papiers Stellten Wir Fest, Dass Große Datensätze Auch Alternative Versionen Haben

Das neue Modell DALL-E des OpenAI-Teams war überall auf dem Bildschirm zu sehen. Dieses neue neuronale Netzwerk verwendet 12 Milliarden Parameter und wurde „speziell trainiert“. Es kann nach jeder beschreibenden Texteingabe entsprechende Bilder generieren. Jetzt hat das Team das Dokument des Projekts und einige Modulcodes als Open Source freigegeben, sodass wir die Prinzipien hinter diesem Artefakt verstehen können.
Anfang des Jahres veröffentlichte OpenAI das Bildgenerierungsmodell DALL-E, das die Dimensionswand zwischen natürlicher Sprache und Bildern vollständig durchbrach.
Egal wie übertrieben oder unrealistisch die Textbeschreibung ist, sobald sie in DALL-E eingegeben wird, kann sie ein entsprechendes Bild erzeugen, und die Wirkung hat den gesamten Technologiekreis in Erstaunen versetzt.

Großer Aufwand bewirkt Wunder: Die Kostenobergrenze der Alchemie-Industrie
Rechenleistung: 1024 Blöcke V 100
Als das Modell herauskam, spekulierten die Entwickler über den Implementierungsprozess hinter dem Modell und warteten gespannt auf das offizielle Dokument. Vor Kurzem wurden das Dokument von DALL-E und einige Implementierungscodes endlich veröffentlicht:

Adresse des Artikels: https://arxiv.org/abs/2102.12092
Wie erwartet hat OpenAI erneut seine starke „Geldmacht“ unter Beweis gestellt, wie einige Entwickler bereits zuvor vermutet hatten.Aus dem Dokument geht hervor, dass während des gesamten Trainings insgesamt 1024 NVIDIA V100-GPUs mit 16 GB verwendet wurden.
Was den Code betrifft, öffnet die offizielle Version derzeit nur das dVAE-Modul zur Bildrekonstruktion.Der Zweck dieses Moduls besteht darin, den Speicherverbrauch des für die Text-Bild-Generierungsaufgabe trainierten Transformers zu reduzieren. Der Transformer-Codeteil wurde noch nicht veröffentlicht, daher können wir nur auf spätere Updates warten. Allerdings ist selbst mit dem Code nicht jeder in der Lage, diese GPU-Nutzung zu reproduzieren.
Datensatz: 250 Millionen Bild-Text-Paare + 12 Milliarden Parameter
In dem Artikel stellte das OpenAI-Team vor, dass die Forschung zur Verwendung von Synthesemethoden des maschinellen Lernens zur Konvertierung von Text in Bild im Jahr 2015 begann.
Obwohl die in diesen früheren Studien vorgeschlagenen Modelle in der Lage waren, Text in Bilder umzuwandeln, sind ihre Generierungsergebnisse immer noch mit vielen Problemen behaftet, wie etwa Objektverformungen, unsinnige Objektplatzierungen oder eine unnatürliche Mischung von Vordergrund- und Hintergrundelementen.

Nach Recherchen stellte das Team fest, dass frühere Studien normalerweise anhand kleinerer Datensätze (wie MS-COCO und CUB-200) ausgewertet wurden. Darauf aufbauend schlug das Team folgende Idee vor:Ist es möglich, dass die Datensatzgröße und die Modellgröße begrenzende Faktoren für aktuelle Methoden sind?
Daher nutzte das Team dies als Durchbruchwurde ein Datensatz von 250 Millionen Bild-Text-Paaren aus dem Internet gesammelt,Anhand dieses Datensatzes wird ein autoregressiver Transformer mit 12 Milliarden Parametern trainiert.
Darüber hinaus führt das Papier ein, dass das Training des dVAE-Modells verwendet 64 16 GB NVIDIA V100 GPUs,Das Diskriminanzmodell CLIP verwendet 256 GPUs trainiert für 14 Himmel.
Nach intensivem Training erhielt das Team schließlich DALL-E, ein flexibles und realistisches Bildgenerierungsmodell, das durch natürliche Sprache gesteuert werden kann.
Das Team verglich und bewertete die vom DALL-E-Modell generierten Ergebnisse mit denen anderer Modelle. Die Ergebnisse waren:Im Fall von 90% sind die von DALL-E generierten Ergebnisse günstiger als die früherer Studien.

Der Bild- und Textdatensatz ist ein flacher Ersatz, wirklich gut
Der Erfolg des DALL-E-Modells beweist auch, wie wichtig umfangreiche Trainingsdaten für ein Modell sind.
Für gewöhnliche Alchemisten mag es schwierig sein, denselben Datensatz wie DALL-E zu erhalten, aber die großen Marken haben alle Ersatzversionen (erschwingliche Alternativversionen).
Obwohl OpenAI erklärt hat, dass ihr Trainingsdatensatz noch nicht veröffentlicht wird,Sie gaben jedoch bekannt, dass der Datensatz den von Google veröffentlichten Conceptual Captions-Datensatz enthält.
Mini-Alternative für groß angelegte Bild-Text-Datensätze
Der Conceptual Captions-Datensatz wurde von Google in dem in ACL 2018 veröffentlichten Dokument „Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning“ vorgeschlagen.

Dieses Papier leistet Beiträge sowohl zur Daten- als auch zur Modellklassifizierung. Erste,Das Team schlug einen neuen Datensatz mit Bildunterschriftenanmerkungen vor, „Conceptual Captions“, der um eine Größenordnung mehr Bilder enthält als der MS-COCO-Datensatz, darunter insgesamt etwa 3,3 Millionen Bild- und Beschreibungspaare.
Konzeptionelle Bildunterschriften(Konzeptioneller Titel) Datensatzdetails
Datenquelle:Google AI
Veröffentlichungszeit:2018
Enthaltene Menge:3,3 Millionen Bild-Text-Paare
Datenformat:.tsv Datengröße:1,7 GB
Downloadadresse:https://orion.hyper.ai/datasets/14682
Verwenden von ResNet+RNN+Transformer zum Erstellen eines umgekehrten DALL-E
In Bezug auf die Modellierung, basierend auf früheren Forschungsergebnissen,Das Team verwendete Inception-ResNet-v2, um Bildmerkmale zu extrahieren, und verwendete dann ein auf RNN und Transformer basierendes Modell, um Bildunterschriften zu generieren (DALL-E generiert Bilder aus Textbeschreibungen und Conceptual Captions generiert Textanmerkungen aus Bildern).
Um den Datensatz zu generieren, begann das Team mit einer Flume-Pipeline, die etwa eine Milliarde Internet-Webseiten parallel verarbeitete, indem sie mögliche Bild- und Beschriftungspaare aus diesen Seiten extrahierte, filterte und verarbeitete und diejenigen beibehielt, die mehrere Filter bestanden.
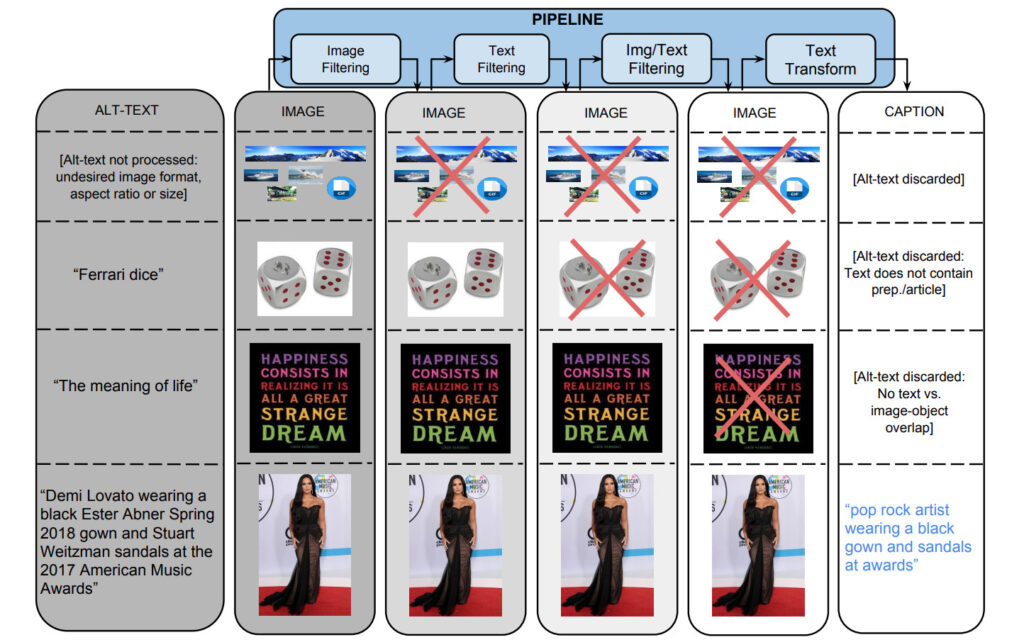
1: Bildbasierte Filterung
Algorithmen filtern Bilder basierend auf Kodierungsformat, Größe, Seitenverhältnis und anstößigem Inhalt. Es werden nur JPEG-Bilder gespeichert, die in beiden Dimensionen größer als 400 Pixel sind und bei denen das Verhältnis der Größendimensionen 2 nicht überschreitet. Bilder, die eine Erkennung von Pornografie oder obszönen Ausdrücken auslösen, werden nicht gespeichert. Letztendlich eliminierten diese Filter mehr als 651 TP3T-Kandidatendaten.
2. Textbasierte Filterung
Der Algorithmus ruft beschreibenden Text (Alt-Text) von HTML-Webseiten ab, entfernt Titel mit nicht beschreibendem Text (wie SEO-Tags oder Hashtags) und filtert Anmerkungen anhand voreingestellter Indikatoren heraus, wie etwa solche, die Pornografie, Schimpfwörter, Obszönitäten, Profilfotos usw. enthalten. Schließlich haben nur 31 TP3T-Kandidatentexte die Prüfung bestanden.
Neben der getrennten Filterung nach Bild- und Textinhalten werden auch Daten herausgefiltert, bei denen sich keine Zuordnung der Text-Tags zu Bildinhalten herstellen lässt.
Weisen Sie Bildern mithilfe von Klassifizierern, die über die Google Cloud Vision-APIs bereitgestellt werden, Klassenbezeichnungen zu.
3. Textkonvertierung und Hyperlexikalisierung
Während des Datensatzerfassungsprozesses wurden mehr als 5 Milliarden Bilder von etwa 1 Milliarde englischsprachigen Webseiten verarbeitet. Unter dem hochpräzisen Filterstandard haben nur 0,2% der Bild- und Titelpaare die Prüfung bestanden, und die verbleibenden Titel wurden häufig ausgeschlossen, weil sie Eigennamen (Personen, Orte, Standorte usw.) enthielten.
Die Autoren haben ein RNN-basiertes Untertitelmodell anhand nicht hypersynchronisierter Alt-Textdaten trainiert und geben in der folgenden Abbildung ein Ausgabebeispiel an.

Beschreibung der Modellausgabe: Sänger Justin Bieber tritt bei den Billboard Music Awards im MGM auf
Mithilfe der Google Cloud Natural Language API erhielt das Team benannte Entitäts- und grammatikalische Abhängigkeitsanmerkungen. Anschließend wird die Such-API des Google Knowledge Graph (KG) verwendet, um benannte Entitäten mit KG-Einträgen abzugleichen und verwandte Hyperonym-Begriffe zu nutzen.
Beispielsweise werden „Harrison Ford“ und „Calista Flockhart“ beide als benannte Entitäten identifiziert und daher mit den entsprechenden KG-Einträgen abgeglichen. Diese KG-Einträge haben „Akteur“ als Konjunktion und ersetzen dann die ursprünglichen Oberflächen-Token durch diese Konjunktion.
Ergebnisauswertung
Das Team nahm den Testsatz des Datensatzes undEine Stichprobe von 4000 Beispielen wurde zufällig ausgewählt und manuell ausgewertet. Unter den 3 Anmerkungen erhielten die Anmerkungen über 90% die meisten guten Bewertungen.
Das Team verglich die Unterschiede zwischen dem auf COCO trainierten Modell und dem auf Conceptual trainierten Modell.
In,Der erste Unterschied besteht darin, dass die auf Conceptual basierenden Trainingsergebnisse sozialer sind als die Trainingsergebnisse von COCO, die auf natürlichen Bildern basieren.
Beispielsweise verwendet das COCO-trainierte Modell im Bild ganz links unten „Gruppe von Männern“, um sich auf die Personen im Bild zu beziehen, während das konzeptionell trainierte Modell den passenderen und informativeren Begriff „Absolventen“ verwendet.

Der zweite Unterschied besteht darin, dass mit COCO trainierte Modelle oft scheinbar „von selbst assoziieren“ und einige Beschreibungen aus dem Nichts „erfinden“.Beispielsweise hatte man im ersten Bild die Halluzination, man stehe „vor einem Gebäude“. die Halluzination, im zweiten Bild „eine Uhr und zwei Türen“ zu sein; und die Halluzination, „eine Geburtstagstorte“ zu sein, für das dritte Bild. Im Gegensatz dazu wurde dieses Problem im Modell des Teams nicht festgestellt.
Der dritte Unterschied besteht in den Arten der Bilder, die verwendet werden können.Da COCO nur natürliche Bilder enthält, verursachen Cartoon-Bilder wie das vierte in der obigen Abbildung „assoziative“ Interferenzen mit dem von COCO trainierten Modell, wie z. B. „Plüschtier“, „Fisch“, „Autoseite“ und andere nicht vorhandene Dinge. Im Gegensatz dazu kann das konzeptionell trainierte Modell diese Bilder problemlos verarbeiten.
Die Einführung des DALL-E-Modells hat auch viele Forscher auf diesem Gebiet zum Aufatmen gebracht: Daten sind tatsächlich der Eckpfeiler der KI. Wollen auch Sie versuchen, mit großer Kraft Wunder geschehen zu lassen? Beginnen wir mit dem Conceptual Captions-Datensatz!
Zugang https://orion.hyper.ai/datasets Oder klicken Sie aufLesen Sie den Originalartikel, und erhalten Sie weitere Datensätze!
Nachrichtenquelle:
https://openai.com/blog/dall-e/
DALL-E-Papieradresse:
https://arxiv.org/abs/2102.12092
GitHub-Adresse des DALL-E-Projekts:
https://github.com/openai/dall-e
Adresse des Dokuments „Conceptual Captions“:








