Command Palette
Search for a command to run...
Keine Zeit, Filme Oder Fernsehserien Anzusehen, KI Verwandelt Filme Und Fernsehserien Mit Einem Klick in Comics

Was für eine magische Operation ist es, aus einem Film oder einer Fernsehserie einen Comic zu machen? Ein Team der Dalian University of Technology und der City University of Hong Kong hat kürzlich ein KI-Framework vorgeschlagen, das Filme und Fernsehserien automatisch in Comics umwandeln kann. Ab sofort gibt es eine weitere Möglichkeit, Filme und Fernsehserien anzusehen.
Heutzutage sind Filme, Fernsehserien und verschiedene Videos zu einem unverzichtbaren Teil unseres Lebens geworden. Berichten zufolge würde ein Mensch mehr als 82 Jahre brauchen, um die Gesamtlänge aller täglich auf YouTube hochgeladenen Videos anzusehen.
Um beim Ansehen von Fernsehserien Zeit zu sparen, ist die Wiedergabe mit doppelter Geschwindigkeit zum Standard für das Binge-Watching von Fernsehserien geworden.Außer dem ruckelfreien Anschauen mit doppelter Geschwindigkeit und dem Anhören von Kommentaren der Filmkritiker gibt es noch eine weitere Möglichkeit, Fernsehserien schnell nachzuholen: die Serie in Comics umzuwandeln.
Kürzlich veröffentlichten Forscher der Technischen Universität Dalian und der City University of Hong Kong eine interessante Studie, die Bilder aus Fernsehserien, Filmen oder anderen Videos automatisch in Comicform umwandeln und mit Textblasen versehen kann.

„Verglichen mit den modernsten Comic-Generierungssystemen kann unser System ausdrucksstärkere und attraktivere Comics synthetisieren“, sagten die Forscher in dem Artikel. „In Zukunft soll diese Technologie erweitert werden, um Comics anhand von Textinformationen zu generieren.“
Ich habe Comic-Adaptionen gesehen, aber haben Sie schon einmal „adaptierte Comics“ gesehen?
Zuvor gab es in der Branche bereits einige ähnliche Forschungsergebnisse, die automatisierte Systeme zur Konvertierung von Videos in Comics vorschlugen. Allerdings besteht hinsichtlich Automatisierung, visueller Effekte, Lesbarkeit usw. noch Verbesserungsbedarf. Daher ist diese Forschungsrichtung noch immer voller Herausforderungen.
Ein Team der Dalian University of Technology und der City University of Hong Kong hat kürzlich eine Arbeit veröffentlicht„Automatische Comic-Generierung mit stilistischen Mehrseiten-Layouts und emotionsgesteuerter Textblasen-Generierung“Eine bessere Methode wird in vorgeschlagen.

Adresse des Artikels: https://arxiv.org/abs/2101.11111
Das Papier schlägt ein vollautomatisches System zur Comic-Generierung vor.Keine NotwendigkeitDurch manuelle Anpassungen durch den Benutzer können aus beliebigen Videos (Fernsehserien, Filme, Zeichentrickfilme) hochwertige Comicseiten generiert und die Dialoge der Charaktere in Sprechblasentexte umgewandelt werden.Darüber hinaus verfügen die vom System generierten Comics über reichhaltige visuelle Effekte und sind sehr gut lesbar.
Drei Module, die Film- und Fernsehdramen in Comics verwandeln
Die in diesem Papier vorgeschlagene Kernidee besteht darin, dassEntwerfen Sie Systeme vollautomatisch ohne manuell angegebene Parameter oder Einschränkungen.Gleichzeitig führte das Team gezielt Benutzerinteraktionen ein, um das Design persönlicher und vielfältiger zu gestalten.
Im Allgemeinen besteht das System aus drei Hauptmodulen:Keyframe-Auswahl und Comic-Stilisierung, Generierung mehrseitiger Layouts, Generierung und Platzierung von Textblasen.
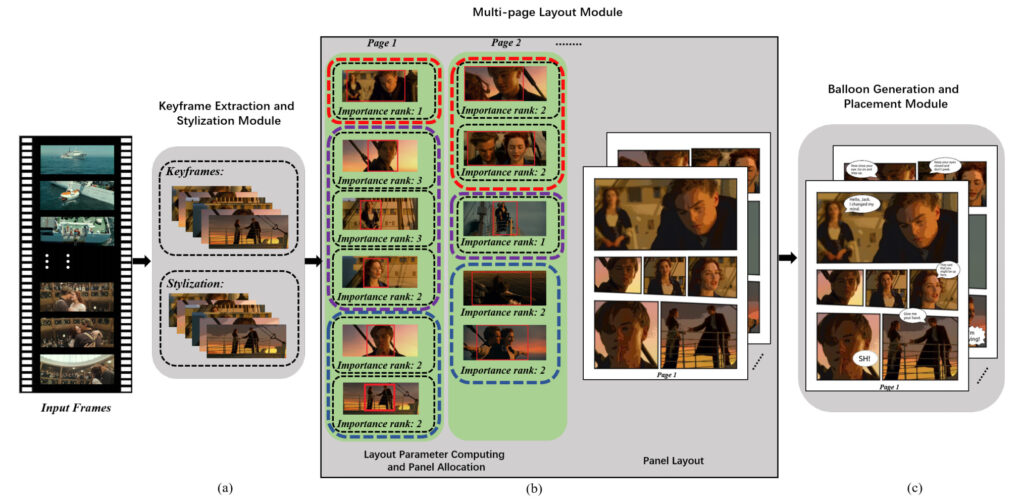
Modul 1: Keyframe-Extraktion und Stilisierung
Die Eingabe des Systems ist ein Video und seine Untertitel, die Dialoge und entsprechende Start- und Endzeitstempelinformationen enthalten.
Sie wählten zunächst alle 0,5 Sekunden ein Bild aus dem Originalvideo aus und nutzten dann die zeitlichen Informationen in den Untertiteln und die Ähnlichkeit zwischen zwei aufeinanderfolgenden Bildern, um aussagekräftige Schlüsselbilder auszuwählen. Abschließend werden die Keyframes stilisiert, das heißt, die gewöhnlichen Bilder werden in Bilder im Comic-Stil umgewandelt.
Keyframe-Extraktion
Die Auswahl der Schlüsselbilder ist eine besonders wichtige und schwierige Aufgabe. Zur Auswahl greift das Team vor allem auf Zeitinformationen zurück.

Wie in der Abbildung oben gezeigt, hat das Team zunächst die Start- und Endzeit jedes Untertitels verwendet, um das Video in mehrere Aufnahmen aufzuteilen. Diese Aufnahmen werden in zwei Typen unterteilt: Dialogaufnahmen (Aufnahmen mit Untertiteln) und Nicht-Dialogaufnahmen (Aufnahmen ohne Untertitel).
Für Dialogaufnahmen:Das System berechnet die GIST-Ähnlichkeit zwischen zwei zuvor erhaltenen aufeinanderfolgenden Frames (wenn die GIST-Ähnlichkeit gering ist, ist der Unterschied zwischen den beiden Frames groß).
Wenn während der Ausführung die Ähnlichkeit geringer ist als der voreingestellte Schwellenwert ?1, wird das nächste Bild als Schlüsselbild ausgewählt.Wenn keines der einer Untertitelgruppe entsprechenden Bilder ausgewählt ist, wird das mittlere Bild als Schlüsselbild ausgewählt.
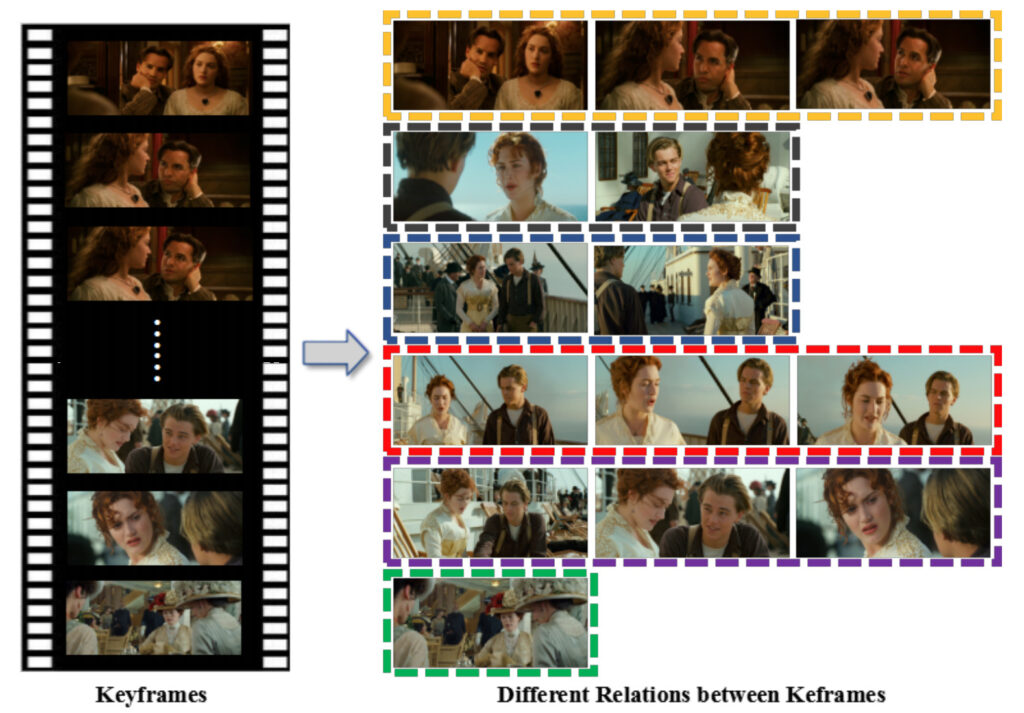
Unter Berücksichtigung der Tatsache, dass ein fortlaufender Dialog und dieselbe Szene mehreren Untertiteln entsprechen können, berechnete das Team die GIST-Ähnlichkeit zwischen den zuvor erhaltenen aufeinanderfolgenden Schlüsselbildern. Wenn die Ähnlichkeit größer als der eingestellte Schwellenwert ?2 ist, wird davon ausgegangen, dass sie zur selben Szene gehören. Behalten Sie dann einfach einen der Keyframes und fügen Sie die Untertitel zusammen.
Darüber hinaus kann das System im selben Satz von Untertiteln mehrere Schlüsselbilder auswählen, da sich nach der Berechnung herausstellen kann, dass diese Schlüsselbilder semantische Beziehungen aufweisen und diese Schlüsselbilder für das mehrseitige Layout verwendet werden.
Für Aufnahmen ohne Dialoge:Zuerst werden die Frames ausgewählt, die mit den Frames in der aktuellen Aufnahme am wenigsten identisch sind. Um die Redundanz ausgewählter Frames zu reduzieren, berechnet das System die GIST-Ähnlichkeit zwischen dieser Aufnahme und dem zuvor ausgewählten Schlüsselframe. Nur wenn es kleiner als der zuvor festgelegte Schwellenwert ist, wird es als Schlüsselbild ausgewählt.
Abschließend werden die Untertitelsätze durch Vergleich der Startzeitstempel und der Zeitstempel der Keyframes gruppiert. Alle Untertitel, die innerhalb des Start- und Endzeitstempelbereichs eines Keyframes liegen, werden zusammen erfasst.
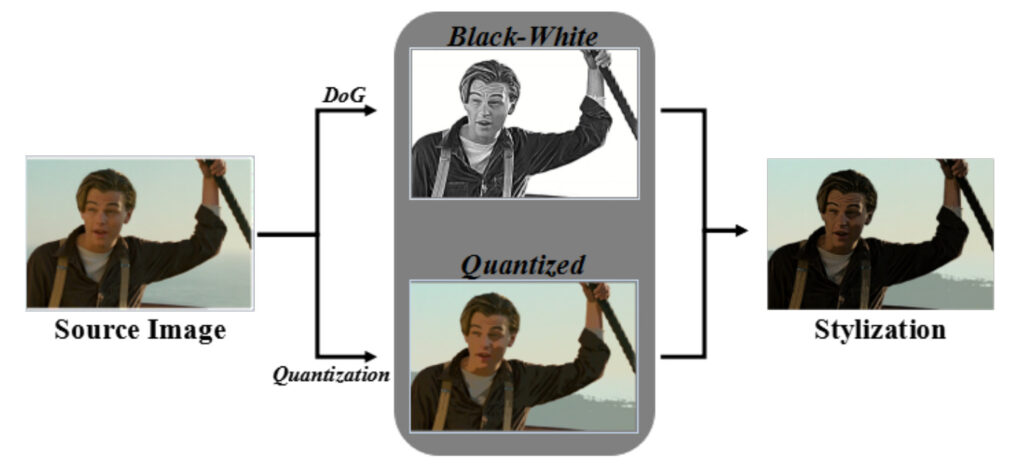
Stilisiertes Bild
Das Team verwendete eine erweiterte Differenzmethode der Gaußschen Verteilung, um die Quellbilder in Schwarzweiß umzuwandeln. Nach dem Essen wird eine 128-stufige Farbquantisierung durchgeführt, um das quantisierte Bild zu erhalten und eine Farbstilisierung zu erreichen. So ist es, eine Reihe realer Filmaufnahmen, die im Comic-Stil umgesetzt wurden.
Modul 2: Mehrseitiges Layout
Das Team schlug ein mehrseitiges Layout-Framework vor, um Seitenlayouts automatisch zuzuweisen und zu organisieren und gleichzeitig reichhaltigere visuelle Effekte zu präsentieren.
In diesem Modul müssen wir zunächst vier Schlüsselfaktoren berechnen, um die Generierung mehrseitiger Layouts zu steuern, darunter: den Interessenbereich (ROI) der Keyframes, die Wichtigkeitsstufe der Keyframes, die semantische Beziehung zwischen den Keyframes und die Anzahl der Panels auf einer Seite.
Anschließend schlug das Team eine auf Optimierung basierende Panelzuweisungsmethode vor, um einer Seitensequenz Schlüsselbilder zuzuweisen, und verwendete eine datengesteuerte Methode zur Comic-Layoutsynthese, um das Layout jeder Seite zu generieren.
Freunde, die Comics verfolgen, wissen, dass die Anzahl der Bilder auf jeder Seite eines Comicbuchs nicht festgelegt ist. Um den Lesern ein besseres Leseerlebnis zu bieten, ordnen die Cartoonisten die Anzahl der Bilder der Handlung entsprechend an.
In dieser Studie behandelte das Team dieses Problem als ein globales Optimierungsproblem, um die Zuordnung jeder Aufnahme auf der Comicseite abzuschließen.
Modul 3: Erstellung und Platzierung von Textblasen
Textblasen generieren
Normalerweise wählt der Autor in Comics unterschiedliche Blasenformen für Dialoge in unterschiedlichen Situationen und Emotionen, was für den Ausdruck des Comic-Inhalts sehr wichtig ist. Allerdings verwenden bestehende Studien hierzu im Allgemeinen nur einfache elliptische Blasenformen, die für den emotionalen Ausdruck nicht aussagekräftig genug sind.
Ein wichtiges Ergebnis, das in diesem Artikel vorgeschlagen wird, ist eine Methode zur Blasengenerierung auf Grundlage der Emotionswahrnehmung, die Video-, Audio- und Untertitelinformationen mit Emotionen nutzen kann, um für diese geeignete Textblasenformen zu generieren.

In diesem System hat der Autor drei gängige Blasenformen übernommen: ovale Blasen, Gedankenblasen und gezackte Blasen. Die drei Blasenarten eignen sich für folgende Emotionen: ruhige Emotionen, Gedanken (unausgesprochen) und starke Emotionen.
Für das Training des Blasenklassifizierers verwendete das Team hauptsächlich einige Anime-Videos und entsprechende Comics, um Daten zu Audio-Emotionen, Untertitel-Emotionen und Blasentypen zu sammeln.
Positionierung und Platzierung der Blasen
Ähnlich wie bei der vorherigen Methode werden auch in diesem Dokument Sprechererkennung und Lippenbewegungserkennung verwendet, um die Position der sprechenden Person in einem Rahmen zu ermitteln und den Ballon dann in der Nähe der Person zu platzieren, zu der er gehört.
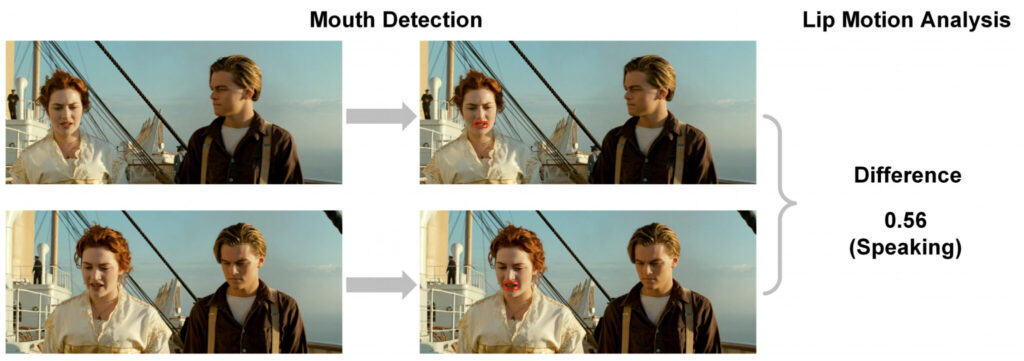
Der konkrete Ausführungsprozess ist wie folgt:
- Verwenden Sie zunächst die Python-Bibliothek zur Gesichtserkennung „Dlib“, um den Mund jeder Figur in einem Frame zu erkennen.
- Anschließend wird mittels Lippenbewegungsanalyse die mittlere quadratische Differenz der Pixelwerte des Mundbereichs zwischen zwei aufeinanderfolgenden Frames berechnet. Die Differenz wird im Suchbereich um den Mundbereich im aktuellen Frame berechnet, um festzustellen, ob sich die Lippen bewegen.
- Legen Sie abschließend einen Schwellenwert fest, um festzustellen, ob eine Figur spricht.
Wenn Sie den Standort des Sprechers ermittelt haben, platzieren Sie die Sprechblase in seiner Nähe, wobei das Ende der Blase in Richtung des Mundes des Sprechers zeigen muss.
Anhand von vier Filmklassikern die Systemwirkung bewerten
Um das Modell zu testen, hat das Team 16 Clips aus vier verschiedenen Filmen eingegeben: Titanic, The Message, Friends und Up in the Air.
Die Dauer der Eingabevideos variierte zwischen 2 und 6 Minuten und jeder Clip enthielt einen Abschnitt mit Dialog.
Für jeden Clip zeichnete das Team auf, wie lange es dauerte, mit dem System ein Comicbuch zu erstellen, und berechnete die durchschnittliche Zeit, die zur Bewertung der Systemleistung benötigt wurde.

Die Autoren kamen zu dem Schluss, dass die Methode dieser Studie anderen Methoden im Vergleich zu früheren Methoden überlegen ist. Dies spiegelt sich hauptsächlich in den folgenden drei Aspekten wider:
- Erstens kann das System umfangreichere Sprechblasenformen für Gespräche generieren, während bestehende Methoden nur einfache elliptische Sprechblasen verwenden.
- Zweitens werden mithilfe der Textzusammenfassungsmethode einige verwandte Untertitel zusammengeführt, wodurch sichergestellt werden kann, dass die Sätze in den Textblasen nicht zu lang sind und die Lesbarkeit verbessert wird.
- Drittens wird durch die automatische Ermittlung von vier wichtigen Parametern ein vollautomatisches Layout für mehrere Seiten erreicht (frühere Methoden waren größtenteils halbautomatisch und erforderten manuelle Eingriffe) und die Layoutergebnisse sind angemessen und umfangreich.

Um Störungen durch subjektive Faktoren zu vermeiden, rekrutierte das Team außerdem 40 Freiwillige über Amazon Mechanical Turk, um die vom Team generierten Ergebnisse mit denen anderer ähnlicher Systeme zu vergleichen.
Die Freiwilligen sahen sich zunächst das Originalvideo an, lasen dann die mit unterschiedlichen Methoden erstellten Comics und bewerteten die Wirkung. Um subjektive Voreingenommenheit zu vermeiden, wurden die Videos und die dazugehörigen Cartoons nach dem Zufallsprinzip angeordnet.
Das Endergebnis war, dass das System bessere Bewertungen erhielt als andere Methoden, unabhängig davon, ob die Freiwilligen die Videos zuvor gesehen hatten.
Comics mit einem Klick erstellen, was kann man sonst noch tun?
Obwohl es von den Benutzern positive Bewertungen erhalten hat, ist das System sicherlich nicht perfekt und es müssen noch einige Probleme gelöst werden.
Beispielsweise kann es bei der Auswahl von Keyframes immer noch zu einer Situation kommen, in der die Ähnlichkeit zu hoch ist, was zu Redundanz im Bild führt.
Wenn das Eingabevideo keine Untertitel hat, muss das System außerdem zunächst die Zeilen durch Spracherkennung extrahieren, bevor die Comics generiert werden. Allerdings sind die Ergebnisse der Spracherkennung häufig fehleranfällig, sodass auch dies eine Herausforderung für das System darstellt. Das Team ist jedoch davon überzeugt, dass dieses Problem mit der kontinuierlichen Weiterentwicklung der Spracherkennungstechnologie in Zukunft gelöst werden kann.
Wenn diese Technologie in Zukunft ausgereift genug ist, wird es für viele Videoarbeiten eine zusätzliche Möglichkeit zum Öffnen geben. Das „Anschauen“ eines Films in Form eines Comics kann den Lesern mehr Raum für ihre Fantasie geben.

Darüber hinaus können auch normale Menschen ohne Malkenntnisse problemlos Videos in Comics umwandeln. Dies könnte ein neues Massenunterhaltungstool werden, genau wie die Prisma-App, die Fotos in gemäldeartige Bilder umwandeln kann.
Das Team plant außerdem, diese Methode im nächsten Schritt zu erweitern, um Comics anhand von Textinformationen zu generieren. Mit anderen Worten: Solange das Comic-Skript vorliegt, kann das System automatisch Comics erstellen, was den Cartoonisten viel Zeit spart.

