Command Palette
Search for a command to run...
Ressourcen Zur Fernerkundung (Teil 1): Verwendung Von Open-Source-Code Zum Trainieren Von Landklassifizierungsmodellen
Die Landklassifizierung ist eines der wichtigsten Anwendungsszenarien von Fernerkundungsbildern. Dieser Artikel stellt mehrere gängige Methoden der Landklassifizierung vor und verwendet Open-Source-Code zur semantischen Segmentierung, um ein Landklassifizierungsmodell zu erstellen.
Fernerkundungsbilder sind wichtige Daten für die Vermessungs- und Kartierungsarbeit im Bereich der Geoinformationsverarbeitung. Sie sind von großer Bedeutung für die Überwachung der geografischen Bedingungen auf nationaler Ebene und die Aktualisierung geografischer Informationsdatenbanken und spielen in den Bereichen Militär, Handel und Lebensunterhalt der Bevölkerung eine immer wichtigere Rolle.
In den letzten Jahren hat sich mit der Verbesserung der Möglichkeiten des Landes zur Erfassung von Satellitenbildern die Effizienz der Fernerkundungsbilddatenerfassung erheblich verbessert. Dabei ist ein Muster entstanden, bei dem mehrere Sensoren, etwa mit niedriger räumlicher Auflösung, hoher räumlicher Auflösung, großem Betrachtungswinkel, Mehrfachwinkel, Radar usw., nebeneinander existieren.

Eine vollständige Palette von Sensoren, um den Anforderungen der Erdbeobachtung für verschiedene Zwecke gerecht zu werden.Allerdings verursachte dies auch Probleme wie inkonsistente Datenformate für Fernerkundungsbilder und den Verbrauch großer Mengen an Speicherplatz.Im Bildverarbeitungsprozess gibt es oft große Herausforderungen.
Am Beispiel der Landklassifizierung wurden in der Vergangenheit Fernerkundungsbilder zur Klassifizierung von Land verwendet.Oftmals ist ein hoher Personalaufwand für die Kennzeichnung und Statistik erforderlich,Es dauert mehrere Monate oder sogar ein Jahr; Angesichts der Komplexität und Vielfalt der Landtypen sind menschliche statistische Fehler unvermeidlich.
Mit der Entwicklung der künstlichen Intelligenz sind die Erfassung, Verarbeitung und Analyse von Fernerkundungsbildern intelligenter und effizienter geworden.
Gemeinsame Landklassifizierungsmethoden
Die üblicherweise verwendeten Methoden zur Bodenklassifizierung lassen sich grundsätzlich in drei Kategorien unterteilen:Traditionelle Klassifizierungsmethoden auf Basis von GIS, Klassifizierungsmethoden auf Basis von Algorithmen des maschinellen Lernens und Klassifizierungsmethoden unter Verwendung der semantischen Segmentierung neuronaler Netzwerke.
Traditionelle Methode: Verwendung der GIS-Klassifizierung
GIS ist ein häufig verwendetes Werkzeug bei der Verarbeitung von Fernerkundungsbildern. Der vollständige Name lautet Geographic Information System, auch bekannt als geografisches Informationssystem.Es integriert fortschrittliche Technologien wie relationales Datenbankmanagement, effiziente Graphenalgorithmen, Interpolation, Zonierung und Netzwerkanalyse.Machen Sie räumliche Analysen einfach und leicht.

Mithilfe der GIS-RaumanalysetechnologieEs können Informationen über die räumliche Lage, Verteilung, Morphologie, Entstehung und Entwicklung des entsprechenden Landtyps gewonnen werden.Identifizieren Sie Geländemerkmale und treffen Sie Urteile.
Maschinelles Lernen: Algorithmen zur Klassifizierung verwenden
Zu den traditionellen Methoden der Landklassifizierung gehören die überwachte und die unüberwachte Klassifizierung.
Die überwachte Klassifizierung wird auch als Trainingsklassifizierung bezeichnet.Es bezieht sich auf das Vergleichen und Identifizieren von Pixeln unbekannter Kategorien mit Pixeln von Trainingsbeispielen bestätigter Kategorien.Vervollständigen Sie dann die Klassifizierung des gesamten Landtyps.
Wenn bei der überwachten Klassifizierung die Trainingsbeispiele nicht genau genug sind, wird der Trainingsbereich normalerweise neu ausgewählt oder manuell visuell geändert, um die Genauigkeit der Trainingsbeispielpixel sicherzustellen.

Bei der unbeaufsichtigten Klassifizierung ist es nicht erforderlich, im Voraus a priori Kategoriestandards zu ermitteln, sondern die statistische Klassifizierung erfolgt vollständig gemäß den spektralen Eigenschaften der Pixel im Fernerkundungsbild.Diese Methode weist einen hohen Automatisierungsgrad auf und erfordert nur wenig menschliches Eingreifen.
Mithilfe von Algorithmen des maschinellen Lernens wie Support Vector Machines und Maximum-Likelihood-Methoden können die Effizienz und Genauigkeit der überwachten und unüberwachten Klassifizierung erheblich verbessert werden.
Neuronale Netze: Semantische Segmentierung zur Klassifizierung nutzen
Bei der semantischen Segmentierung handelt es sich um eine durchgängige Klassifizierungsmethode auf Pixelebene, die das maschinelle Verständnis von Umgebungsszenen verbessern kann und in Bereichen wie autonomem Fahren und Landplanung weit verbreitet ist.
Bei Klassifizierungsaufgaben auf Pixelebene ist die Leistung der auf tiefen neuronalen Netzwerken basierenden semantischen Segmentierungstechnologie besser als bei herkömmlichen Methoden des maschinellen Lernens.

Fernerkundungsbilder mit hoher Auflösung weisen komplexe Szenen und viele Details auf und die spektralen Unterschiede zwischen Objekten sind unsicher, was leicht zu einer geringen Segmentierungsgenauigkeit oder sogar zu einer ungültigen Segmentierung führen kann.
Verwendung semantischer Segmentierung zur Verarbeitung hochauflösender und ultrahochauflösender Fernerkundungsbilder,Die Pixelmerkmale des Bildes können genauer extrahiert und bestimmte Landtypen schnell und genau identifiziert werden, wodurch die Verarbeitungsgeschwindigkeit von Fernerkundungsbildern verbessert wird.
Häufig verwendete Open-Source-Modelle zur semantischen Segmentierung
Zu den häufig verwendeten Open-Source-Modellen zur semantischen Segmentierung auf Pixelebene gehören FCN, SegNet und DeepLab.
1. Vollständig gefaltetes Netzwerk (FCN)
Merkmal:End-to-End-semantische Segmentierung
Vorteil:Keine Einschränkungen bei der Bildgröße, universell und effizient
Mangel:Echtzeit-Schlussfolgerungen können nicht schnell durchgeführt werden, die Verarbeitungsergebnisse sind nicht fein genug und reagieren nicht empfindlich auf Bilddetails
2. SegNet
Merkmal:Verschieben Sie den Max-Pooling-Index zum Decoder, um die Segmentierungsauflösung zu verbessern
Vorteil:Schnelle Trainingsgeschwindigkeit, hohe Effizienz und geringer Speicherverbrauch
Mangel:Der Test ist nicht feed-forward und muss optimiert werden, um das MAP-Label zu bestimmen
3. DeepLab
DeepLab wurde von Google AI veröffentlicht.Befürworten Sie die Verwendung von DCNN zur Lösung semantischer Segmentierungsaufgaben.Es gibt insgesamt vier Versionen: v1, v2, v3 und v3+.
DeepLab-v1 löst das Problem des durch Pooling verursachten Informationsverlusts.Es wird die Methode der erweiterten Faltung vorgeschlagen.Das rezeptive Feld wird vergrößert, ohne die Anzahl der Parameter zu erhöhen, wobei gleichzeitig sichergestellt wird, dass keine Informationen verloren gehen.

DeepLab-v2 basiert auf v1.Multiskalen-Parallelität hinzugefügt,Das Problem der gleichzeitigen Segmentierung von Objekten unterschiedlicher Größe ist gelöst.
DeepLab-v3 Die Lochfaltung wird auf das Kaskadenmodul angewendet.Und das ASPP-Modul wurde verbessert.
DeepLab-v3+ Das SPP-Modul wird in der Encoder-Decoder-Struktur verwendet.Feine Objektkanten können wiederhergestellt werden. Verfeinern Sie die Segmentierungsergebnisse.
Vorbereitung des Modelltrainings
Zweck: Basierend auf DeepLab-v3+, Entwicklung eines 7-Klassifizierungsmodells für die Landklassifizierung
Daten:304 Fernerkundungsbilder einer Region von Google Earth. Zusätzlich zum Originalbild enthält es auch professionell kommentierte unterstützende 7-Kategorie-Bilder, 7-Kategorie-Masken, 25-Kategorie-Bilder und 25-Kategorie-Maskenbilder. Die Bildauflösung beträgt 560*560 und die räumliche Zuordnungsrate beträgt 1,2 m.

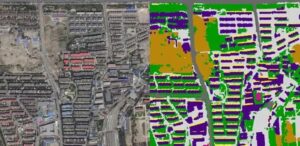
Der obere Teil ist das Originalbild und der untere Teil ist das 7-Klassifizierungsbild
Der Parameteranpassungscode lautet wie folgt:
net = DeepLabV3Plus(backbone = 'xception')criterion = CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=0.05, momentum=0.9,weight_decay=0.00001)lr_fc=lambda iteration: (1-iteration/400000)**0.9exp_lr_scheduler = lr_scheduler.LambdaLR(optimizer,lr_fc,-1)
Trainingsdetails
Hashrate-Auswahl:NVIDIA T4
Ausbildungsrahmen:PyTorch V1.2
Iterationen:600 Epoche
Trainingsdauer:Etwa 50 Stunden
Schuldverschreibung:0,8285 (Trainingsdaten)
Klimaanlage:0,7838 (Trainingsdaten)
Datensatzlink: https://openbayes.com/console/openbayes/datasets/qiBDWcROayo
Direktlink zum detaillierten Trainingsprozess: https://openbayes.com/console/openbayes/containers/dOPqM4QBeM6

Tutorial-Nutzung
Die Beispielanzeigedatei im Tutorial ist predict.ipynb. Durch Ausführen dieser Datei wird die Umgebung installiert und der Erkennungseffekt des vorhandenen Modells angezeigt.
Projektpfad
– Testbildpfad:
semantic_pytorch/out/result/pic3
– Maskenbildpfad:
semantic_pytorch/out/result/label
– Bildpfad vorhersagen:
semantic_pytorch/out/result/predict
– Trainingsdatenliste:Zug.csv
– Testdatenliste:test.csv
Anweisungen
Das Trainingsmodell gelangt in semantic_pytorch und das trainierte Modell wird in model/new_deeplabv3_cc.pt gespeichert.
Das Modell verwendet DeepLabV3plus und in den Trainingsparametern verwendet Loss binäre Kreuzentropie. Die Epochennummer beträgt 600 und die anfängliche Lernrate beträgt 0,05.
Trainingsanleitung:
python main.pyWenn Sie das von uns trainierte Modell verwenden, speichern Sie es im Modellordner fix_deeplab_v3_cc.pt und rufen Sie es direkt in predict.py auf.
Prädiktive Anweisungen:
python predict.pyAdresse des Tutorials:https://openbayes.com/console/openbayes/containers/dOPqM4QBeM6
Modellautor:
Wang Yanxin, ein Software-Engineering-Student im zweiten Jahr an der Heilongjiang-Universität, derzeit Praktikant bei OpenBayes.
Frage 1: Welche Kanäle haben Sie genutzt und welche Informationen haben Sie konsultiert, um dieses Modell zu entwickeln?
Wang Yanxin:Ich habe hauptsächlich über technische Communities, GitHub und andere Kanäle einige DeepLab-v3+-Dokumente und zugehörige Projektfälle geprüft, im Voraus gelernt, welche Fallstricke es gibt und wie man sie überwindet, und ausreichende Vorbereitungen getroffen, um jederzeit Fragen stellen und Probleme lösen zu können, wenn im nachfolgenden Modellentwicklungsprozess Probleme auftreten.
Frage 2: Auf welche Hindernisse sind Sie während des Prozesses gestoßen? Wie haben Sie es überwunden?
Wang Yanxin:Die Datenmenge reicht nicht aus, was zu einer durchschnittlichen Leistung von IoU und AC führt. Beim nächsten Mal können Sie versuchen, einen öffentlichen Fernerkundungsdatensatz mit umfangreicheren Daten zu verwenden.
Frage 3: Welche weiteren Richtungen möchten Sie im Bereich Fernerkundung ausprobieren?
Wang Yanxin:Dieses Mal klassifiziere ich Land. Als Nächstes möchte ich eine Kombination aus maschinellem Lernen und Fernerkundungstechnologie verwenden, um Meereslandschaften und Meereselemente zu analysieren, oder akustische Technologie kombinieren, um zu versuchen, die Topographie des Meeresbodens zu identifizieren und zu beurteilen.
Die in diesem Training verwendete Datenmenge ist relativ gering und die IoU- und AC-Leistung des Trainingssatzes ist durchschnittlich. Sie können auch versuchen, vorhandene öffentliche Fernerkundungsdatensätze für das Modelltraining zu verwenden. Generell gilt: Je gründlicher das Training und je umfangreicher die Trainingsdaten, desto besser die Modellleistung.
Im nächsten Artikel dieser ReiheWir haben 11 gängige öffentliche Fernerkundungsdatensätze zusammengestellt und klassifiziert.Sie können entsprechend Ihren Anforderungen auswählen und basierend auf den in diesem Artikel bereitgestellten Trainingsideen ein umfassenderes Modell trainieren.
siehe:
http://tb.sinomaps.com/CN/0494-0911/home.shtml
file:///Users/antonia0912/Downloads/2018-6A-50.pdf
https://zhuanlan.zhihu.com/p/75333140
http://www.mnr.gov.cn/zt/zh/zljc/201106/t20110619_2037196.html








