Command Palette
Search for a command to run...
Das Team Der Zhejiang-Universität Veröffentlicht Eine Neue Methode Zur 3D-Ansichtssynthese, Die Weitaus Besser Ist Als NeRF Und NV
Mit nur wenigen Videos aus unterschiedlichen Perspektiven lässt sich das gesamte 360°-Bild des menschlichen Körpers ohne blinde Flecken erstellen. Man muss sagen, dass die Vorstellungskraft der KI immer größer wird. Solche Tools könnten in Zukunft zu neuen Durchbrüchen in der Film- und Fernsehbranche, bei der Präsentation von Sportprogrammen usw. führen.
Die Art und Weise, wie wir Filme, Fußballspiele, Konzerte usw. ansehen, könnte sich in Zukunft durch „Free-Viewpoint-Video“ völlig verändern.
Sie wissen vielleicht nicht, was „Free Viewpoint Video“ ist, aber Sie sollten schon VR- und AR-Videos erlebt oder 3D-Spiele gespielt haben. Diese fallen alle in die Kategorie der kostenlosen Viewpoint-Videos und ihre Merkmale sind:Es kann aus jedem Winkel betrachtet werden und bietet ein vollkommen immersives Erlebnis.

Wie kann ein solches Video gedreht werden? Im Allgemeinen erfordert die herkömmliche Methode mehrere Kameras, die aus unterschiedlichen Winkeln aufnehmen und dann die Videos aus allen Winkeln zusammenfügen.

Allerdings erfordert diese Methode mehrere Kameras, was nicht nur teuer ist, sondern auch durch die Umgebung des Aufnahmeorts eingeschränkt ist.
Es gibt eine andere Möglichkeit, diese Einschränkungen zu beseitigen.Durch die einfache Eingabe einiger Aufnahmen des menschlichen Körpers aus verschiedenen Winkeln kann eine neue 360°-3D-Ansicht des menschlichen Körpers synthetisiert werden.Dies ist das neueste Ergebnis, das kürzlich von Forschern der Zhejiang-Universität veröffentlicht wurde.
Ende Dezember veröffentlichte das Team ein neues Paper auf arxiv„Neural Body: Implizite neuronale Repräsentationen mit strukturierten latenten Codes für die neuartige Sichtsynthese dynamischer Menschen“, schlug eine neue Darstellung des menschlichen Körpers vor: Neural Body, bei der mithilfe von spärlichen Multi-View-Videos neue Ansichten dynamischer 3D-Körper des Menschen synthetisiert werden. Die experimentelle Überprüfung zeigt, dass diese Methode anderen bisherigen Methoden überlegen ist.
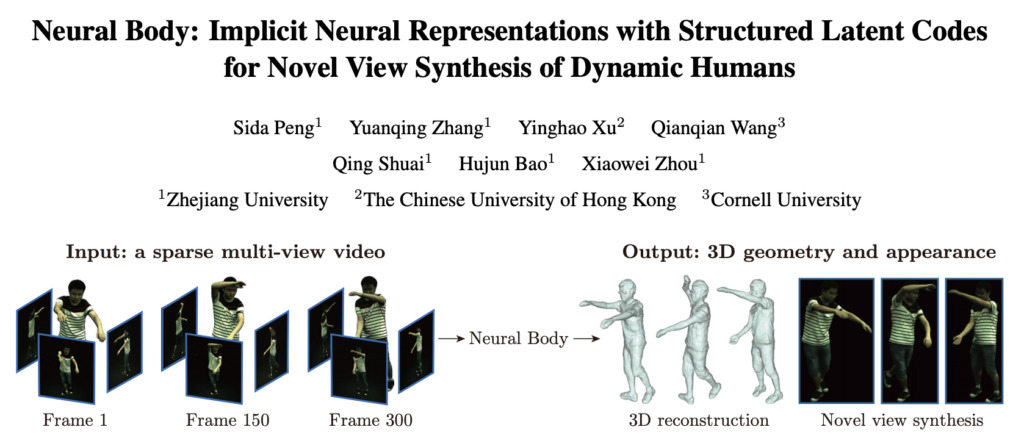
Adresse des Artikels: https://arxiv.org/pdf/2012.15838.pdf
Es ist erwähnenswert, dass die sieben Autoren des Artikels alle an der Zhejiang-Universität studiert oder ihren Abschluss gemacht haben und vom State Key Laboratory of Computer-Aided Design and Graphics der Zhejiang-Universität stammen.Unter ihnen sind Hujun Bao und Xiaowei Zhou beide Professoren des Labors. Nach Abschluss ihres Grundstudiums promovierten Yinghao Xu und Qianqian Wang an der Chinese University of Hong Kong bzw. der Cornell University.
Auch mit wenig Material lassen sich hochwertige 3D-Ansichten erstellen
Egal ob es sich um einen Film, ein Fernsehprogramm oder ein Sportereignis handelt, was wir derzeit sehen, sind Bilder, die von einer einzigen Kamera aufgenommen wurden. Wenn Sie ein „kostenloses Perspektivvideo“ erhalten und sehen können, was Sie möchten, wird es auf jeden Fall eine Erfahrung sein, als hätten Sie die Perspektive Gottes.
Tatsächlich hat sich auch die KI in den letzten Jahren mit diesem Problem befasst und Lösungen zur Ansichtssynthese wie NeRF und Neural Volumes (kurz NV) hervorgebracht.
Bestehende Studien haben jedoch gezeigt, dass durch das Lernen impliziter neuronaler Darstellungen von 3D-Szenen unter dichten Eingabeansichtsbedingungen eine gute Ansichtssynthesequalität erreicht werden kann. Wenn die Ansichten jedoch sehr spärlich sind, ist das Lernen der Repräsentation schlecht gestellt.

Um dieses schwierige Problem zu lösen, schlug ein Forschungsteam der Zhejiang-Universität, der Chinesischen Universität Hongkong und der Cornell-Universität die Schlüsselidee vor, Beobachtungsergebnisse in Videobilder zu integrieren.
Das neueste Forschungsergebnis des Teams schlägt den Neural Body vor.Dies ist eine neue Darstellung des menschlichen Körpers, die davon ausgeht, dass neuronale Darstellungen, die über verschiedene Frames gelernt wurden, denselben Satz latenter Codes gemeinsam haben, die auf einem verformbaren Gitter verankert sind, sodass Beobachtungen über Frames hinweg auf natürliche Weise integriert werden können.Das verformbare Netz bietet dem Netzwerk außerdem eine geometrische Anleitung, um 3D-Darstellungen effektiver zu erlernen.

Die Forscher führten Experimente mit einem neu gesammelten Multi-View-Datensatz durch und zeigten, dass ihre Methode im Hinblick auf die Qualität der Ansichtssynthese einen großen Vorteil gegenüber früheren Methoden hat.
In einer Demo demonstrierte das Team die Fähigkeit seiner Methode, bewegte Figuren aus monokularen Videos von Menschen zu rekonstruieren, die verschiedene Aktionen ausführen.

Diese Methode reduziert die Kosten der Free-Viewpoint-Videosynthese erheblich, spart zumindest die Kosten für die Kamera und hat daher eine breitere Anwendbarkeit.
Holen Sie sich Neural Body in 5 Schritten
1. Strukturierter latenter Code
Um die räumliche Position und die menschliche Haltung der latenten Codes zu kontrollieren, verankerte das Team diese latenten Codes an einem verformbaren menschlichen Modell (SMPL). SMPL ist ein auf Skin-Vertex basierendes Modell, das als Formparameter, Pose-Parameter und Starrkörper-Transformationsfunktionen relativ zum SMPL-Koordinatensystem definiert ist.
Der latente Code wird zusammen mit einem neuronalen Netzwerk verwendet, um die lokale Geometrie und das Erscheinungsbild einer Person darzustellen. Durch die Verankerung dieser Codes auf einem verformbaren Modell kann eine dynamische Person dargestellt werden. Mithilfe der dynamischen Personendarstellung erstellte das Team ein latentes Variablenmodell, das denselben Satz latenter Codes über mehrere Frames hinweg in implizite Dichte- und Farbbereiche abbildet und Beobachtungen auf natürliche Weise integriert.
2. Code-Verbreitung
Da die strukturierten latenten Codes im 3D-Raum spärlich sind, führt die direkte Interpolation der latenten Codes für die meisten 3D-Punkte zu Nullvektoren. Um dieses Problem zu lösen, verteilte das Team den auf der Oberfläche definierten latenten Code in den nahegelegenen dreidimensionalen Raum.
Da die Verbreitung des Codes nicht durch die Position und Orientierung der Person im Weltkoordinatensystem beeinflusst werden soll, transformieren sie die Position des Codes in das SMPL-Koordinatensystem.
Bei der Codediffusion werden außerdem die globalen und lokalen Informationen strukturierter latenter Codes aggregiert, was dabei hilft, den impliziten Bereich zu erlernen.
3. Dichte- und Farbregression
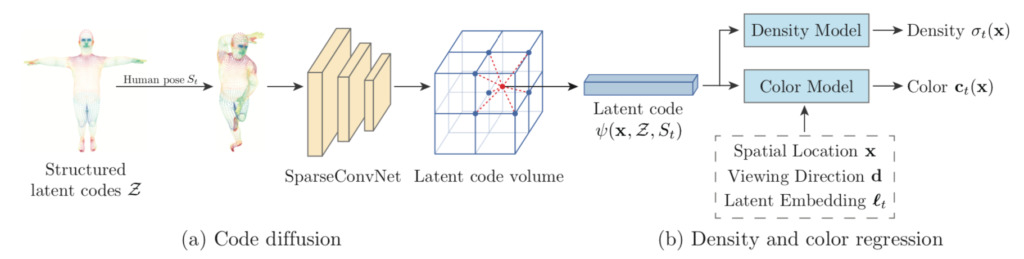
Das Forschungsteam fand heraus, dass zeitabhängige Faktoren das Erscheinungsbild des menschlichen Körpers beeinflussen, wie etwa Sekundärbeleuchtung und Eigenschatten. Inspiriert durch den automatischen Decoder hat das Team jedem Videobild ein latentes Einbettungsbild t zugewiesen, um die Faktoren der zeitlichen Variation zu kodieren.
4. Volumen-Rendering
Unter einem bestimmten Blickwinkel verwendete das Team die klassische Volumenrendering-Technologie (auch als Stereorendering bekannt), um den Neural Body in ein zweidimensionales Bild zu rendern.
Anschließend werden die Szenengrenzen basierend auf dem SMPL-Modell geschätzt und Neural Body sagt die Volumendichte und Farbe dieser Punkte voraus.
Basierend auf dem Volumen-Rendering wird das Modell durch Vergleich des gerenderten Bildes mit dem beobachteten Bild optimiert.
5. Schulung
Im Vergleich zu rahmenbasierten Rekonstruktionsmethoden nutzt diese Methode alle Bilder im Video zur Optimierung des Modells und verfügt über mehr Informationen zur Wiederherstellung der 3D-Struktur.
Darüber hinaus nutzte das Team den Adam-Optimierer, um Neural Body zu trainieren. Das Training wurde auf vier 2080 Ti GPUs durchgeführt. Für ein Vier-Ansichten-Video mit insgesamt 300 Einzelbildern dauert das Training normalerweise etwa 14 Stunden.
Nach den oben genannten fünf Schritten kann Neural Body eine Videosynthese mit freiem Blickwinkel basierend auf einer kleinen Anzahl von Ansichten durchführen, und im Vergleich zu anderen Methoden ist der Effekt deutlich besser als bei der ersten.
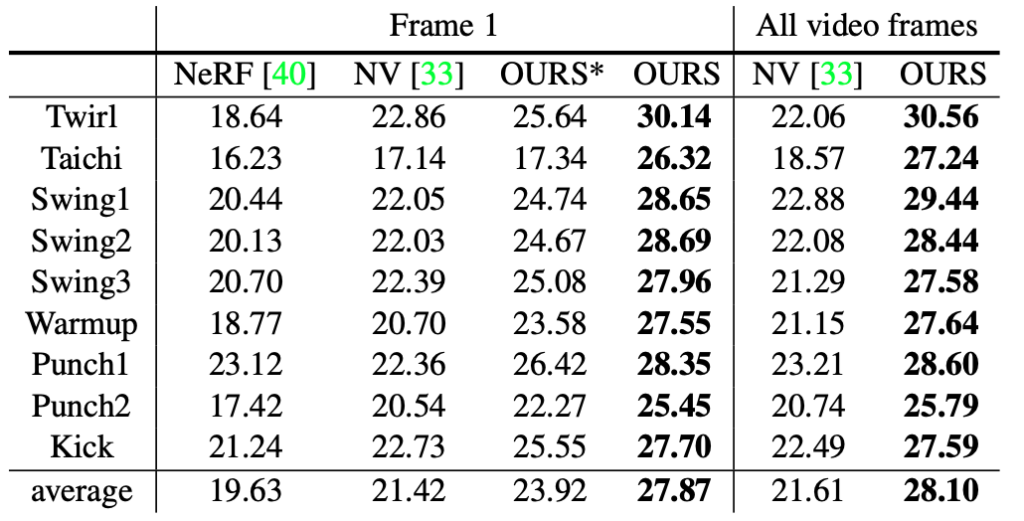
Hinweis: „OURS*“ und „OURS“ stellen die Ergebnisse des Trainings mit nur einem Videobild bzw. mit vier Videobildern dar.)
Die Gehirnfülltechnologie der KI erleichtert das Erzielen von 3D-Effekten und ihre Anwendungen sind nicht auf die Film- und Fernsehbranche sowie Live-Sportveranstaltungen beschränkt. Für Spieleentwickler, Fitnesstrainer, 3D-Werbeanbieter usw. ist es ein Tool, das die Arbeitseffizienz und -effektivität erheblich verbessern kann.

Projekthomepage:








