Command Palette
Search for a command to run...
Comic-Übersetzung, Einbettung Von KI, Beiträge Der Universität Tokio in AAAI‘21 Enthalten

Kürzlich sorgte eine Studie zur automatischen Übersetzung von Comic-Texten für hitzige Diskussionen. Das Mantra-Team, bestehend aus zwei Doktoranden der Universität Tokio, hat ein Papier veröffentlicht, das in AAAI 2021 aufgenommen wurde. Das Mantra-Projekt zielt darauf ab, automatisierte maschinelle Übersetzungstools für japanische Comics bereitzustellen.
Kürzlich erschien eine gemeinsame Veröffentlichung des Mantra-Teams der Universität Tokio, Yahoo (Japan) und anderer Institutionen „Auf dem Weg zur vollautomatischen Manga-Übersetzung“(Adresse des Artikels: https://arxiv.org/abs/2012.14271)Das Papier hat die Aufmerksamkeit der Wissenschaft und der zweidimensionalen Gemeinschaft erregt.

Das Mantra-Team hat erfolgreichDie Dialoge, Stimmungswörter, Beschriftungen und sonstigen Texte in den Comics werden automatisch erkannt, die Charaktere unterschieden und der Kontext verknüpft. Abschließend wird der übersetzte Text präzise ersetzt und in den Sprechblasenbereich eingebettet.
Mit diesem magischen Übersetzungstool dürften das Übersetzerteam und die Comic-Fans sehr zufrieden sein.
Veröffentlichen Sie Artikel, veröffentlichen Sie Datensätze und kommerzialisieren Sie
In Bezug auf die wissenschaftliche Forschung wurde das Papier von der AAAI 2021 angenommen. Das Forschungsteam hat außerdem einen Datensatz zur Übersetzungsbewertung geöffnet, der aus fünf Comics unterschiedlicher Stile (Fantasy, Romantik, Kampf, Spannung und Leben) besteht.
OpenMantra-Datensatz zur Auswertung von Comic-Übersetzungen
Papieradresse:https://arxiv.org/abs/2012.14271
Datenformat: kommentierte JSON-Dateien und Rohbilder
Dateninhalt:1593 Sätze, 848 Szenen, 214 Comicseiten
Datengröße: 36,8 MB
Aktualisiert: 7. Dezember 2020
Downloadadresse:https://orion.hyper.ai/datasets/14137
Im Hinblick auf die ProduktisierungMantra plant die Einführung einer vorgefertigten automatischen ÜbersetzungsmaschineEs bietet nicht nur automatisierte Comic-Übersetzungs- und Vertriebsdienste für Verlage, sondern veröffentlicht auch Dienste für einzelne Benutzer.
Nachfolgend finden Sie einige der Übersetzungen des japanischen Mangas „Surrounding Men“, die vom offiziellen Twitter-Konto von Mantra ausgewählt wurden.Dieser Comic mit mehreren Bildern und leichtem Danmei-Stil ist voller Freude und fröhlicher Liebe und hat den anthropomorphen Hintergrund der im Leben häufig verwendeten digitalen Geräte.:
gleitenSehen Sie sich die japanische Originalversion von „Nearby Man“ an
und automatische maschinelle Übersetzung der chinesischen und englischen Versionen
Erkennung, Übersetzung und Einbettung sind wichtige Schritte
Die konkreten Implementierungsschritte werden vom Mantra-Forschungsteam im Artikel „Towards Fully Automated Manga Translation“ ausführlich erläutert.
Der erste Schritt besteht darin, den Text zu lokalisieren
Der erste Schritt zur automatischen Comic-Übersetzung besteht darin, den Textbereich zu extrahieren.
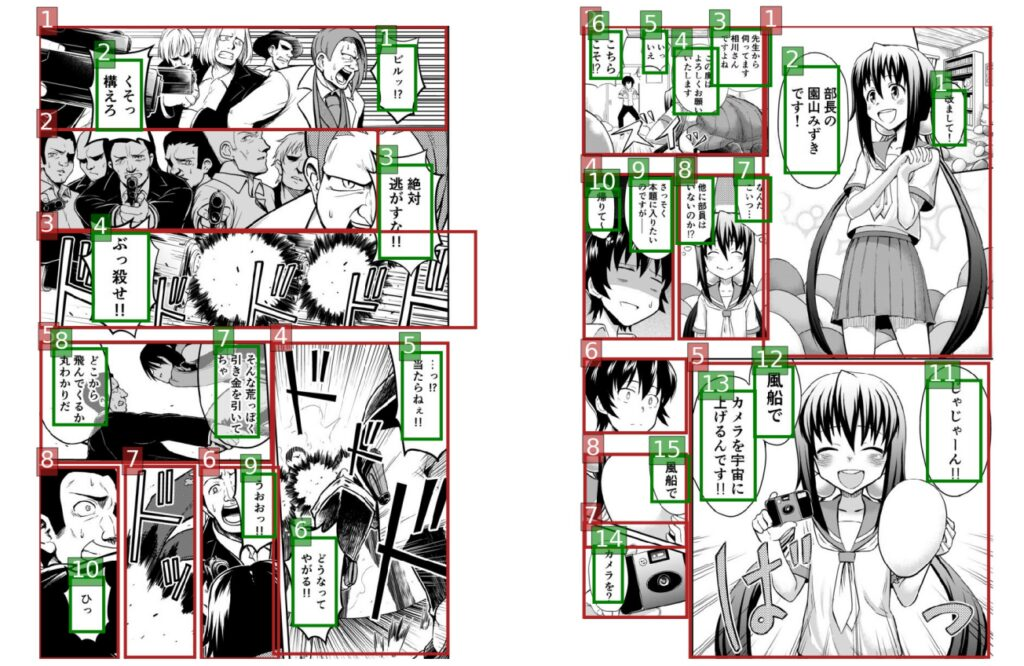
Aufgrund der Besonderheit von Comics werden jedoch Dialoge verschiedener Charaktere, Onomatopoesie, Textanmerkungen usw. alle in einem Comicbild angezeigt. Cartoonisten verwenden Sprechblasen, verschiedene Schriftarten und übertriebene Schriftarten, um Texte mit unterschiedlichen Effekten darzustellen.
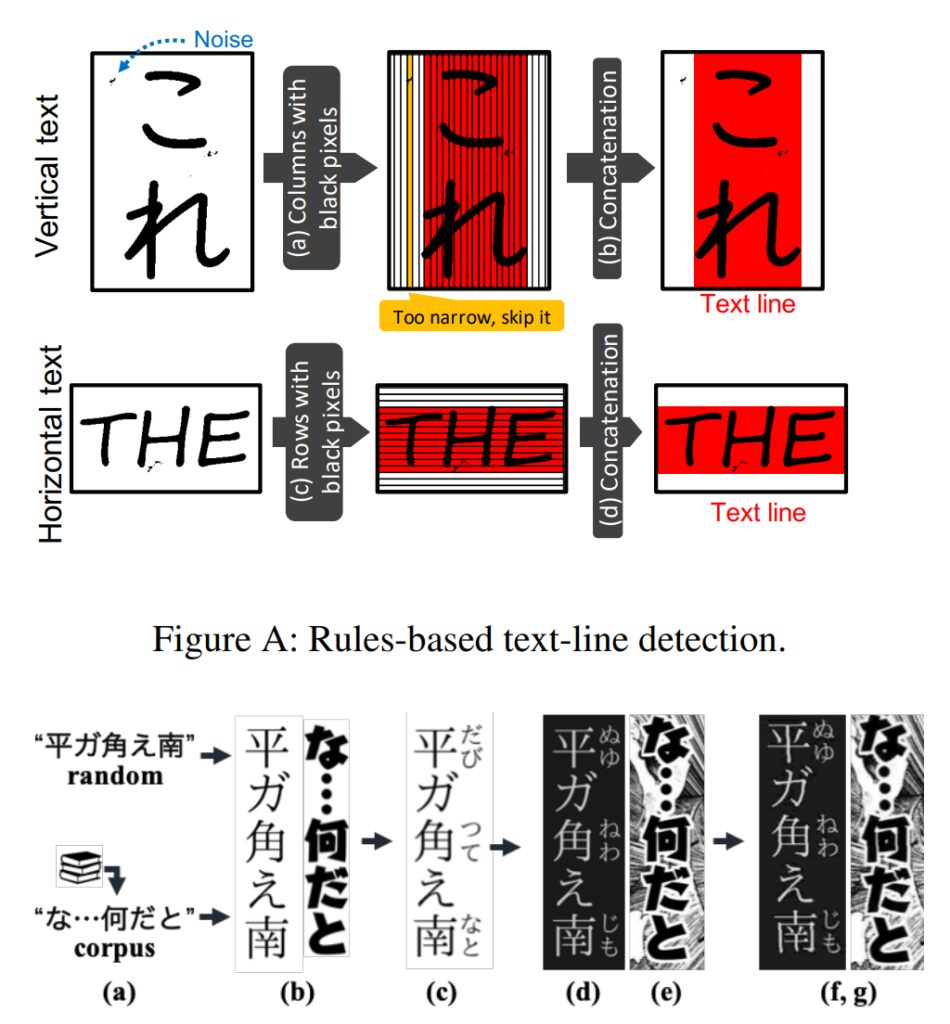
Das Forschungsteam stellte fest, dass aufgrund der verschiedenen Schriftarten und handgezeichneten Stile in Comics selbst die fortschrittlichsten OCR-Systeme (wie etwa die Google Cloud Vision API) bei Comictexten schlechte Ergebnisse erzielen.
Daher entwickelte das Team ein für Comics optimiertes Texterkennungsmodul, das Sonderzeichen erkennen kann, indem es Textzeilen erkennt und die Zeichen jeder Textzeile identifiziert.
Schritt 2: Inhaltsidentifizierung
In Comics ist der Dialog zwischen den Figuren der häufigste Text, und die Dialogblasen werden in mehrere Teile zerschnitten.
Dies erfordert, dass die automatisierte maschinelle Übersetzung die Rollen genau unterscheidet, auf die Zusammenhänge zwischen den Themen achtet und Wiederholungen im Kontext vermeidet, was höhere Anforderungen an die maschinelle Übersetzung stellt.
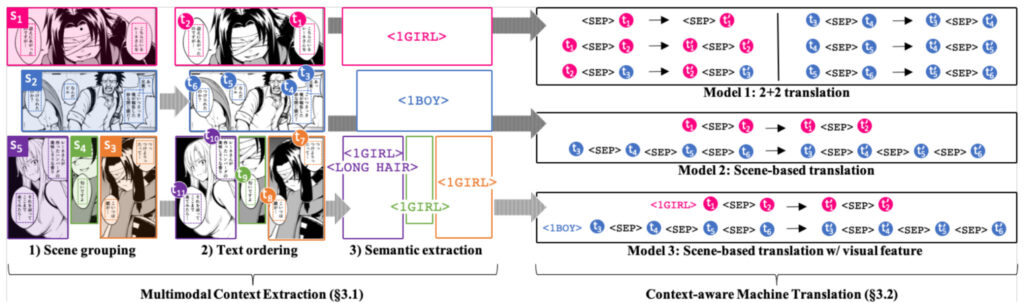
In diesem Schritt ist es notwendig, dies durch Kontextbewusstsein, Emotionserkennung und andere Methoden zu erreichen. Zur Kontextsensitivität verwendete das Mantra-Team drei Methoden: Textgruppierung, Textlesereihe und Extraktion visueller Semantik, um eine multimodale Kontextsensitivität zu erreichen.
Schritt 3 Automatisches Einbetten
Die automatisierte Engine von Mantra kann nicht nur zwischen Zeichen unterscheiden und im Kontext präzise übersetzen, sondern auch den zeit- und arbeitsintensivsten Teil der Comic-Übersetzung lösen – das Einbetten von Zeichen.

Beim Einbettungsvorgang müssen Sie zuerst den eingebetteten Bereich löschen und dann die Zeichen einbetten. Da sich die Formen, Schreibweisen, Kombinationen und Lesarten japanischer, chinesischer und englischer Schriftzeichen unterscheiden, ist dieser Prozess besonders schwierig.
In diesem Schritt müssen Sie Folgendes tun: Seitenabgleich → Textfelderkennung → Pixelzählung von Textblasen → Aufteilen verbundener Blasen → Ausrichtung zwischen Sprachen → Texterkennung → Kontextextraktion.
Experiment: Datensatz- und Modelltests
Im experimentellen Teil des Papiers erwähnte das Mantra-Team, dass es derzeit keinen Comic-Datensatz gibt, der mehrere Sprachen umfasst, also erstellten sie die Datensätze OpenMantra (Open Source) und PubManga, die OpenMantra dient der Auswertung maschineller Übersetzungen und enthält 1.593 Sätze, 848 Szenen und 214 Seiten Comics. Das Mantra-Team hat professionelle Übersetzer gebeten, den Datensatz ins Englische und Chinesische zu übersetzen.

Der PubManga-Datensatz wird zur Auswertung des erstellten Korpus verwendet, der Anmerkungen zu folgenden Punkten enthält: 1) Begrenzungsrahmen für Text und Rahmen; 2) Text (Zeichenfolgen) auf Japanisch und Englisch; und 3) Lesereihefolge von Frames und Text.
Um das Modell zu trainieren, bereitete das Team 842.097 Paare von Comicseiten auf Japanisch und Englisch mit insgesamt 3.979.205 Paaren japanisch-englischer Sätze.Die genaue Methode finden Sie im Dokument. Die endgültige Bewertung der Modelleffekte erfolgt manuell. Das Mantra-Team lud einFünf professionelle Japanisch-Englisch-Übersetzer, bewerten Sie die Sätze mit einem professionellen Übersetzungsbewertungsprogramm.
Hinter dem Projekt: Interessante Seelen lernen gemeinsam
Derzeit ist dieses Dokument in AAAI 2021 aufgenommen und auch die Produktisierungsarbeiten schreiten stetig voran. Auf dem Twitter des Mantra-Teams können wir sehen, dass viele Comics Mantra erfolgreich für die automatische maschinelle Übersetzung verwendet haben.
Ein solches Schatzprojekt wurde von zwei Doktoranden der Universität Tokio abgeschlossen. CEO Shonosuke Ishiwatari und CTO Ryota Hinami haben beide an der Universität Tokio promoviert und 2020 das Mantra-Team gegründet.

CEO Shonosuke Ishiwa,Er begann 2010 sein Studium am Institut für Informationswissenschaft der Universität Tokio und schloss sein Studium mit einem Ph.D. ab. im Jahr 2019.Er konzentriert sich hauptsächlich auf Forschung und Entwicklung im Bereich der Verarbeitung natürlicher Sprache, einschließlich maschineller Übersetzung und Wörterbucherstellung, und ist auch der zweite Autor dieses Artikels.
Es ist erwähnenswert, dass Ishiwa Xiangzhisuke über umfangreiche Forschungserfahrung verfügt. Er war nicht nur Austauschwissenschaftler an der CMU, sondern absolvierte von 2016 bis 2017 auch ein halbes Jahr lang ein Praktikum bei Microsoft Research Asia in Peking. Damals forschte er im Team des MSRA-Chefforschers Liu Shujie zum Thema NLC (Natural Language Computing).
CTO Hinami Ryotaishi kam im selben Jahr wie Shonosuke in die Schule und konzentrierte sich auf den Bereich der Bilderkennung.2016–17 absolvierte ich ein Praktikum bei Microsoft Research Asia bei Shonosuke Ishiwa.
Dieses Freundespaar mit sich ergänzenden Fähigkeiten erledigte den Großteil der Arbeit von Mantra. Ist es nicht beneidenswert, von der Haarmenge bis hin zu den Ergebnissen?
Wenn Sie mehr über Mantra erfahren möchten, können Sie das Papier besuchen (https://arxiv.org/abs/2012.14271)、Offizielle Website des Projekts(https://mantra.co.jp/)Oder laden Sie den Datensatz herunter(https://orion.hyper.ai/datasets/14137), für weitere Forschung.








