Command Palette
Search for a command to run...
Befreie Den Ursprünglichen Künstler! Wav2Lip Nutzt KI, Um Musik Zu Hören Und Die Lippenbewegungen Der Charaktere Zu Synchronisieren

"Sehen ist Glauben"Angesichts der KI-Technologie ist dies wirkungslos geworden. Es gibt immer mehr Technologien zum Ändern des Gesichts und zur Lippensynchronisation, und die Effekte werden immer realistischer. Heute stellen wir vor Wav2Lip Das Modell benötigt lediglich ein Originalvideo und ein Zielaudio, um sie zu einem Ganzen zu kombinieren.
In den letzten Jahren haben Hollywood-Animationsfilme wiederholt mehr als eine Milliarde Dollar an den Kinokassen eingespielt, wie etwa „Zoomania“ und „Die Eiskönigin“, die alle von hervorragender Qualität sind.Nehmen wir nur die Lippenbewegungen als Beispiel: Sie sind sehr präzise und die Lippenbewegungen von Zeichentrickfiguren sind fast identisch mit denen von echten Menschen.
Um einen solchen Effekt zu erzielen, ist ein sehr komplizierter Prozess erforderlich, der enorme personelle und materielle Ressourcen erfordert. Um Kosten zu sparen, verwenden viele Animationsproduzenten daher nur relativ einfache Lippenbewegungen.
Jetzt arbeitet KI daran, die Arbeit von Konzeptkünstlern zu erleichtern. Ein Team der Universität Hyderabad in Indien und der Universität Bath in Großbritannien veröffentlichte dieses Jahr einen Artikel in ACM MM2020„Ein Lippensynchronisationsexperte ist alles, was Sie für die Lippensynchronisation in der freien Wildbahn brauchen.“,Es wird ein KI-Modell namens Wav2Lip vorgeschlagen, das lediglich ein Video einer Person und eine Zielstimme benötigt, um beides zu einem einzigen zu kombinieren, sodass beide nahtlos zusammenarbeiten.
Lippensynchronisationstechnik Wav2Lip, der Effekt ist so hervorragend
Es gibt tatsächlich viele Technologien zur Lippensynchronisation. Schon vor dem Aufkommen der auf Deep Learning basierenden Technologie gab es einige Technologien, die die Lippenform der Figur mit dem tatsächlichen Sprachsignal abglichen.
Aber Wav2Lip weist unter allen Methoden absolute Vorteile auf. Andere bestehende Methoden basieren hauptsächlich auf statischen Bildern, um lippensynchronisierte Videos auszugeben, die zur Zielstimme passen. Bei dynamischen, sprechenden Charakteren funktioniert die Lippensynchronisation jedoch oft nicht gut.
Wav2Lip kann bei dynamischen Videos eine Lippenkonvertierung direkt durchführen und Videoergebnisse ausgeben, die mit der Zielstimme übereinstimmen.
Darüber hinaus sorgen nicht nur Videos, sondern auch die Lippensynchronisation zu animierten Bildern für mehr Abwechslung bei Ihren Emoticons!

Die manuelle Auswertung ergabIm Vergleich zu bestehenden Methoden übertreffen mit Wav2Lip generierte Videos bestehende Methoden in über 90 % der Fälle.
Wie effektiv ist das Modell? Super Neuro hat einige Tests durchgeführt. Das folgende Video zeigt den laufenden Effekt der offiziellen Demo. Als Eingabematerialien dienen die vom Beamten bereitgestellten Testmaterialien sowie die von Super Neural Network ausgewählten chinesischen und englischen Testmaterialien.
Die Charaktere im ursprünglichen Videoeingang sprechen nicht
Durch den Betrieb des KI-Modells wird die Lippenform des Charakters mit der Eingabestimme synchronisiert
Dass der Effekt perfekt ist, können wir im Animationsvideo der offiziellen Demo sehen. Im Super Neural Real Person Test ist der Lippensynchronisationseffekt insgesamt, abgesehen von einer leichten Deformation und Zittern der Lippen, immer noch relativ genau.
Das Tutorial ist da, lernen Sie in drei Minuten
Möchten Sie es nach dem Anschauen auch unbedingt ausprobieren? Wenn Sie bereits eine kühne Idee haben, warum starten Sie nicht gleich damit?
Derzeit ist das Projekt auf GitHub als Open Source verfügbar und der Autor bietet interaktive Demonstrationen, Colab-Notizbücher sowie vollständigen Trainingscode, Inferenzcode, vortrainierte Modelle und Tutorials.
Die Projektdetails lauten wie folgt:
Projektname:Wav2Lip
GitHub-Adresse:
https://github.com/Rudrabha/Wav2Lip
Projektbetriebsumgebung:
- Sprache: Python 3.6+
- Videobearbeitungsprogramm: ffmpeg
Laden Sie das vortrainierte Gesichtserkennungsmodell herunter:
https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
Zusätzlich zur Vorbereitung der oben genannten Umgebung müssen Sie auch die folgenden Softwarepakete herunterladen und installieren:
- librosa==0.7.0
- numpy==1.17.1
- opencv-contrib-python>=4.2.0.34
- opencv-python==4.1.0.25
- tensorflow==1.12.0
- Fackel == 1.1.0
- Torchvision == 0.3.0
- tqdm==4.45.0
- Zahl == 0,48
Auf diese umständlichen Prozeduren müssen Sie sich jedoch nicht einstellen.Sie müssen nur ein Bild/Video einer Person (CGI-Person ist auch OK) + Audio (synthetisches Audio ist auch OK) vorbereiten.Sie können es mit nur einem Klick auf der Container-Service-Plattform für die Rechenleistung von Machine Learning im Inland ausführen.
Portal:https://openbayes.com/console/openbayes/containers/EiBlCZyh7k7
Aktuell bietet die Plattform zudem jede Woche kostenlose vGPU-Nutzungszeit an, sodass jeder das Tutorial problemlos absolvieren kann.
Das Modell hat drei Gewichte: Wav2Lip, Wav2Lip+GAN und Expert Discriminator. Unter diesen sind die Effekte der beiden letztgenannten Modelle deutlich besser als bei alleiniger Verwendung des Wav2Lip-Modells. Die in diesem Tutorial verwendeten Gewichte sind Wav2Lip+GAN.
Die Modellautoren betonen, dassAlle Ergebnisse des Open-Source-Codes sollten nur für Forschungs-/akademische/persönliche Zwecke verwendet werden.Das Modell wird auf Grundlage des LRS2-Datensatzes (Lip Reading Sentences 2) trainiert, daher ist jede Form der kommerziellen Nutzung strengstens untersagt.
Um einen Missbrauch der Technologie zu vermeiden, empfehlen die Forscher außerdem dringend, alle mit dem Code und den Modellen von Wav2Lip erstellten Inhalte als synthetisch zu kennzeichnen.
Die Schlüsseltechnologie dahinter: Lippensynchronisationsdiskriminator
Wie kann Wav2Lip Audiodaten so präzise abhören und die Lippensynchronisation so präzise durchführen?
Es heißt, der Schlüssel zum Durchbruch sei:Die Forscher verwendeten einen Lippensynchronisationsdiskriminator,Dies zwingt den Generator, kontinuierlich genaue und realistische Lippenbewegungen zu erzeugen.
Darüber hinaus verbessert diese Studie die Bildqualität, indem sie im Diskriminator mehrere aufeinanderfolgende Bilder anstelle eines einzelnen Bildes verwendet und einen Bildqualitätsverlust (und nicht nur einen Kontrastverlust) nutzt, um zeitliche Korrelationen zu berücksichtigen.
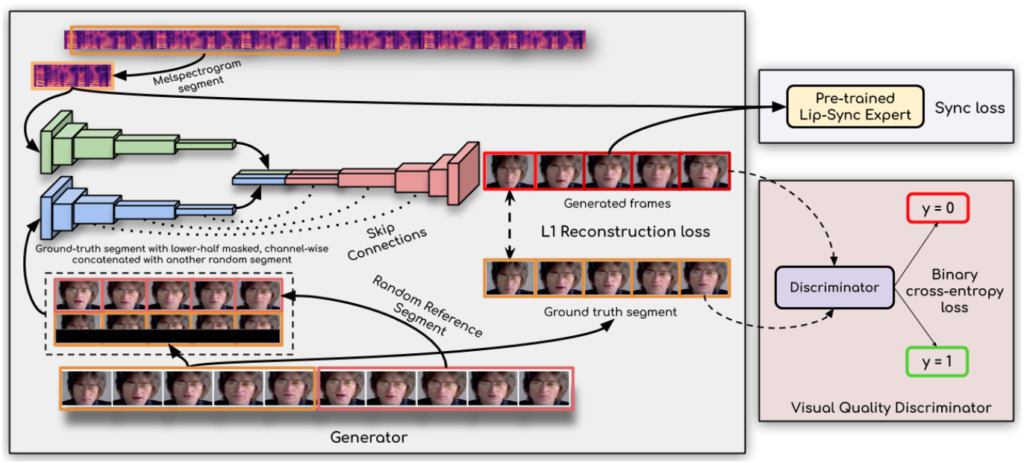
Die Forscher sagten:Ihr Wav2Lip-Modell ist nahezu universell, auf jedes Gesicht, jede Stimme und jede Sprache anwendbar und kann für jedes Video eine hohe Genauigkeit erreichen.Es lässt sich nahtlos mit dem Originalvideo zusammenführen, kann auch zum Konvertieren animierter Gesichter verwendet werden und auch der Import synthetischer Sprache ist möglich.
Es ist denkbar, dass dieses Artefakt eine weitere Welle von Geistervideos auslöst …
Papieradresse:
Demo-Adresse:
https://bhaasha.iiit.ac.in/lipsync/
-- über--








