Command Palette
Search for a command to run...
Der Trainingsdatensatz Auf OpenAI-Niveau Mit Fast 200.000 Büchern Ist Online

Möchten auch Sie ein leistungsstarkes GPT-Modell wie OpenAI trainieren, leiden aber unter dem Mangel an ausreichenden Trainingsdatensätzen? Vor Kurzem hat ein Internetnutzer in der Reddit-Community einen Klartext-Datensatz mit fast 200.000 Büchern hochgeladen. Das Trainieren eines erstklassigen GPT-Modells ist kein Traum mehr.
Kürzlich ein heißer Ressourcenbeitrag in der Machine-Learning-Community „Ein Datensatz mit 196.640 Klartextbüchern zum Trainieren großer Sprachmodelle wie GPT“Es löste eine hitzige Diskussion aus.
Dieser Datensatz enthält Download-Links für alle großen Textkorpora (Stand: September 2020). Darüber hinaus enthält er den Klartext aller Bücher in Bibliotik (einer Online-Ressourcenbibliothek für Bücher) sowie viel Code für das Training.
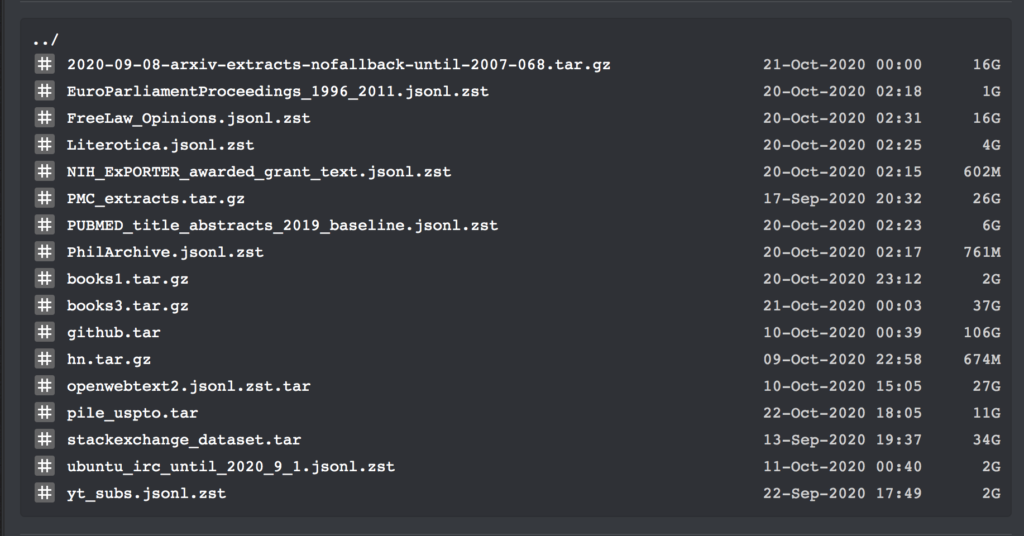
Erst gestern veröffentlichte der Internetnutzer Shawn Presser in der Machine-Learning-Community von Reddit eine Reihe von Klartext-Datensätzen, die einhelliges Lob erhielten.
Diese Datensätze enthalten insgesamt 196.640 Bände mit Klartextdaten, die zum Trainieren großer Sprachmodelle wie GPT verwendet werden können.
Da dieser Datensatz mehrere Datensätze und Trainingscodes enthält, werden wir hier nicht ins Detail gehen. Wir listen nur die spezifischen Informationen der Datensätze „books1“ und „books3“ auf:
Buch-Klartext-Datensatz
Gepostet von: Shawn Presser
Enthaltene Menge:Bücher1: 1800 Bücher; Buch3: 196640 Bücher
Datenformat:txt-Format
Datengröße:Bücher1: 2,2 GB; Bücher3: 37 GB
Aktualisierungszeit:Oktober 2020
Downloadadresse:https://orion.hyper.ai/datasets/13642
Laut dem Datensatzorganisator Shawn Presser ist die Qualität dieser Datensätze sehr hoch. Er brauchte etwa eine Woche, um allein das epub2txt-Skript für den Datensatz „books1“ zu reparieren.
Darüber hinaus erklärte er:Der Datensatz „books3“ scheint dem mysteriösen Datensatz „books2“ aus dem Artikel von OpenAI zu ähneln.Da OpenAI hierzu jedoch keine detaillierten Informationen bereitstellte, ist es unmöglich, etwaige Unterschiede zwischen den beiden zu erkennen.
Seiner Meinung nach ist dieser Datensatz jedoch dem Trainingsdatensatz von GPT-3 sehr ähnlich. Damit besteht der nächste Schritt darin, ein NLP-Sprachmodell zu trainieren, das mit GPT-3 vergleichbar ist. Natürlich gibt es eine Bedingung: Sie müssen auch genügend GPUs vorbereiten.

Laut der EinleitungDer Datensatz „books1“ enthält 1.800 Bücher, alle aus dem großen Textkorpus BookCorpus.Dazu gehören Gedichte, Romane usw.
Zum Beispiel „Shades of Grey: Noir, City Shrouded By Darkness“ der amerikanischen Autorin Kristie Lynn Higgins, „Animal Theater“ von Benjamin Broke und „America One“ von T.I. Waten.
Das leistungsstarke GPT-3 wird durch den Trainingsdatensatz unterstützt
Freunde, die sich für den Bereich der natürlichen Sprachverarbeitung interessieren, wissen, dass das von OpenAI mit enormem Aufwand entwickelte Modell zur natürlichen Sprachverarbeitung GPT-3 im Mai dieses Jahres mit seiner erstaunlichen Fähigkeit zur Textgenerierung große Aufmerksamkeit in der Branche erregte und seitdem beliebt ist.
GPT-3 kann nicht nur Fragen besser beantworten, übersetzen und Artikel schreiben, sondern verfügt auch über einige mathematische Berechnungsfunktionen. Der Grund für diese leistungsstarken Funktionen ist untrennbar mit dem riesigen Trainingsdatensatz verbunden, der dahinter steht.
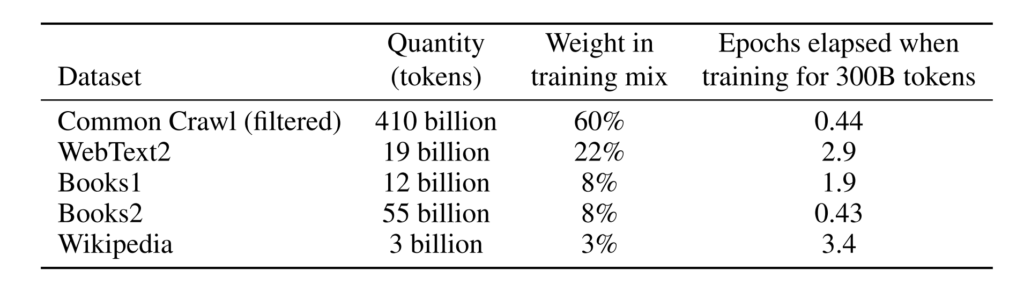
Laut der EinleitungDer von GPT-3 verwendete Trainingsdatensatz ist sehr groß. Es basiert auf dem CommonCrawl-Datensatz, der fast 1 Billion Wörter, Webtexte, Daten, Wikipedia und andere Daten enthält. Der größte verwendete Datensatz hat vor der Verarbeitung eine Kapazität von 45 TB.Auch die Ausbildungskosten beliefen sich auf sage und schreibe 12 Millionen US-Dollar.
Größere Trainingsdatensätze und mehr Modellparameter verschaffen GPT-3 bei Modellen zur Verarbeitung natürlicher Sprache einen großen Vorsprung.
Wenn normale Entwickler jedoch ein erstklassiges Sprachmodell trainieren möchten, bleiben sie beim Schritt des Trainierens des Datensatzes stecken, ganz zu schweigen von den hohen Trainingskosten.
Daher hat der von Shawn Presser bereitgestellte Datensatz dieses Problem zweifellos gelöst und einige Internetnutzer gaben an, dass sie durch diese Arbeit enorme Kosten gespart hätten.
Super Neuro hat den Datensatz books1 nun nach https://orion.hyper.ai,Suchen Sie nach den Schlüsselwörtern „Buch“ oder „Text“ oder klicken Sie auf den Originaltext, um zum Datensatz zu gelangen.
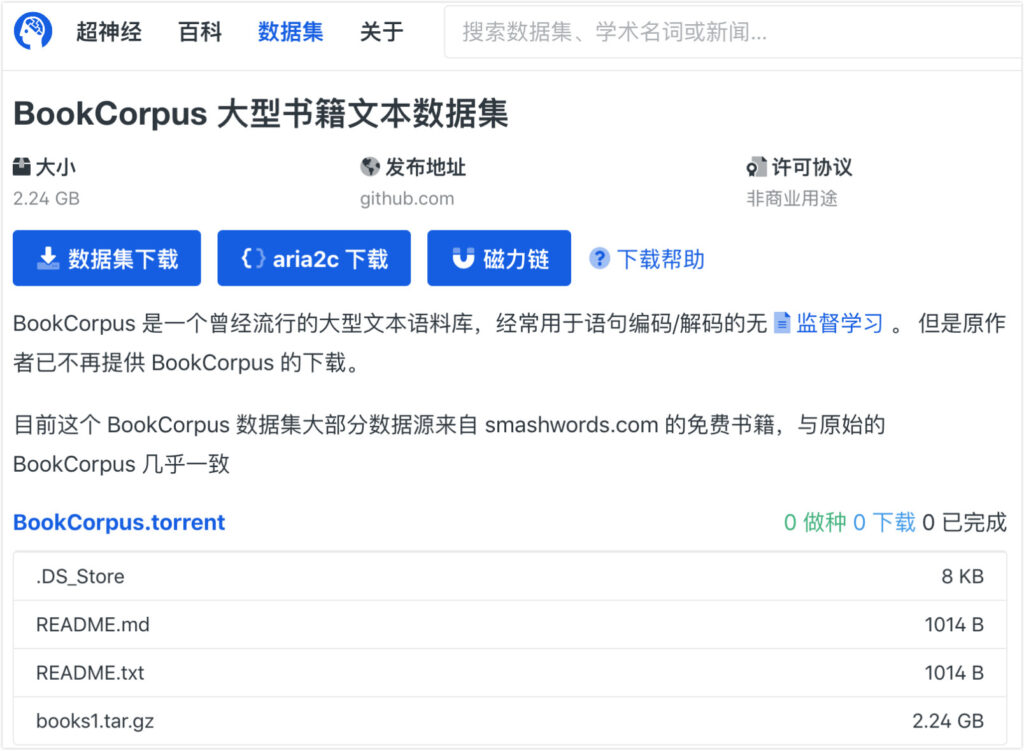
Weitere Datensätze können über die folgenden Links abgerufen werden:
Downloadadresse des Books3-Datensatzes:
https://the-eye.eu/public/AI/pile_preliminary_components/books3.tar.gz
Downloadadresse für den Trainingscode:
https://the-eye.eu/public/AI/pile_preliminary_components/github.tar
Ursprünglicher Reddit-Beitrag:https://www.reddit.com/r/MachineLearning/comments/ji7y06/p_dataset_of_196640_books_in_plain_text_for/
-- über--








