Command Palette
Search for a command to run...
Damedane, Das Göttliche Lied Von B Station: Die Essenz Liegt Im Gesichtswechsel, Sie Können Es in Fünf Minuten Lernen

Es gibt einen endlosen Strom an KI-Technologien, die das Gesicht verändern, aber jede Generation ist besser als die vorherige. Vor kurzem hat ein in NeurIPs 2019 veröffentlichtes KI-Modell zur Gesichtsveränderung mit Bewegungsmodell erster Ordnung an Popularität gewonnen, und sein Ausdrucksübertragungseffekt ist besser als bei anderen Methoden auf demselben Gebiet. Diese Technologie hat in letzter Zeit einen neuen Trend an den B-Stationen ausgelöst …
Vor kurzem ist auf Bilibili eine Welle von Videos mit einem übermäßig „rohen“ Stil (Slang der B-Station, was so viel wie „teuflisch lustig“ bedeutet) aufgetaucht, die Millionen von Aufrufen hatten und daher ziemlich beliebt sind.
Up Meister mit vollen Fähigkeiten, verwenden „Bewegung erster Ordnung, Bewegungsmodell erster Ordnung“Das KI-Projekt zur Gesichtsveränderung hat eine Vielzahl von Videos mit einzigartigen Stilen hervorgebracht.
Zum Beispiel sangen Jacky Cheung, Du Fu, Tang Monk und das Pandakopf-Emoji mit großer Emotion „Damedane“ und „Unravel“ … Das Bild sieht so aus:


Wenn euch die animierten Bilder nicht genügen, dann geht es direkt zum Video:
Die Crying-Cat-Version des Gehirnwäscheliedes „Damedane“, das bisher 2,113 Millionen Mal gespielt wurde, Quelle: B-Station Up Master dickes Haar Hu Tutu
Ich muss sagen, es macht ein bisschen süchtig … Sie können zur kleinen kaputten Station gehen, um nach weiteren Werken zu suchen, die Sie sich ansehen können.
Diese Videos haben unzählige Internetnutzer dazu bewegt, es selbst zu versuchen, und sie haben Nachrichten mit der Bitte um Tutorials hinterlassen. Als nächstes werfen wir einen Blick auf die Technologien, die diese gesichtsverändernden Effekte (die Wurzel allen Übels) erzielen:Bewegungsmodell erster Ordnung.
Learning Garden B Station, mehrere Tutorials zum Erlernen der Lippensynchronisation
Bislang sind in endlosem Strom ähnliche Technologien zum Gesichtswechseln und Lippensynchronisieren aufgetaucht, und jedes Mal, wenn eine davon vorgeschlagen wird, löst sie eine Welle des Gesichtswechselwahns aus.
Das Bewegungsmodell erster Ordnung erfreut sich großer Beliebtheit, da es sich zur Optimierung von Gesichtszügen und Lippenform eignet und einfach anzuwenden und effizient umzusetzen ist.
Wenn Sie beispielsweise das Gesicht von "damedane" am Anfang des Artikels ändern möchten,Es dauert nur wenige Sekunden und kann in fünf Minuten erlernt werden.
Die meisten Uploader auf Bilibili wählen Google Drive und Colab für die Durchführung von Tutorials. Angesichts der Schwierigkeit, die Firewall zu umgehen, haben wir ein Tutorial von einem der Upmaster ausgewählt und den inländischen Containerdienst für maschinelles Lernen und Rechenleistung verwendet (https://openbayes.com), und jetzt können Sie auch jede Woche die kostenlose vGPU-Nutzungszeit nutzen, um dieses Tutorial einfach abzuschließen.
Update 30.09.2020: Derzeit hat bilibili alle Videos zum Thema „AI-Gesichtsveränderung“ entfernt, daher hat das OpenBayes-Team eine entsprechende Textversion des Schritt-für-Schritt-Tutorials hinzugefügt:
Sie können Ihre eigene "Damedane" in weniger als 5 Minuten fertigstellen
In diesem Tutorial-Video wird alles Schritt für Schritt erklärt, sodass selbst Anfänger diese Technik zur Gesichtsveränderung problemlos erlernen können. Der Upmaster hat das Notebook ebenfalls auf die Plattform hochgeladen und kann es durch einfaches Klonen mit einem Klick direkt verwenden.
Viele technische Up-Moderatoren sagten jedoch, dass sie neben der Unterhaltung auch Videos für den technischen Austausch erstellen und daher hoffen, dass sie nicht von jedem böswillig missbraucht werden.
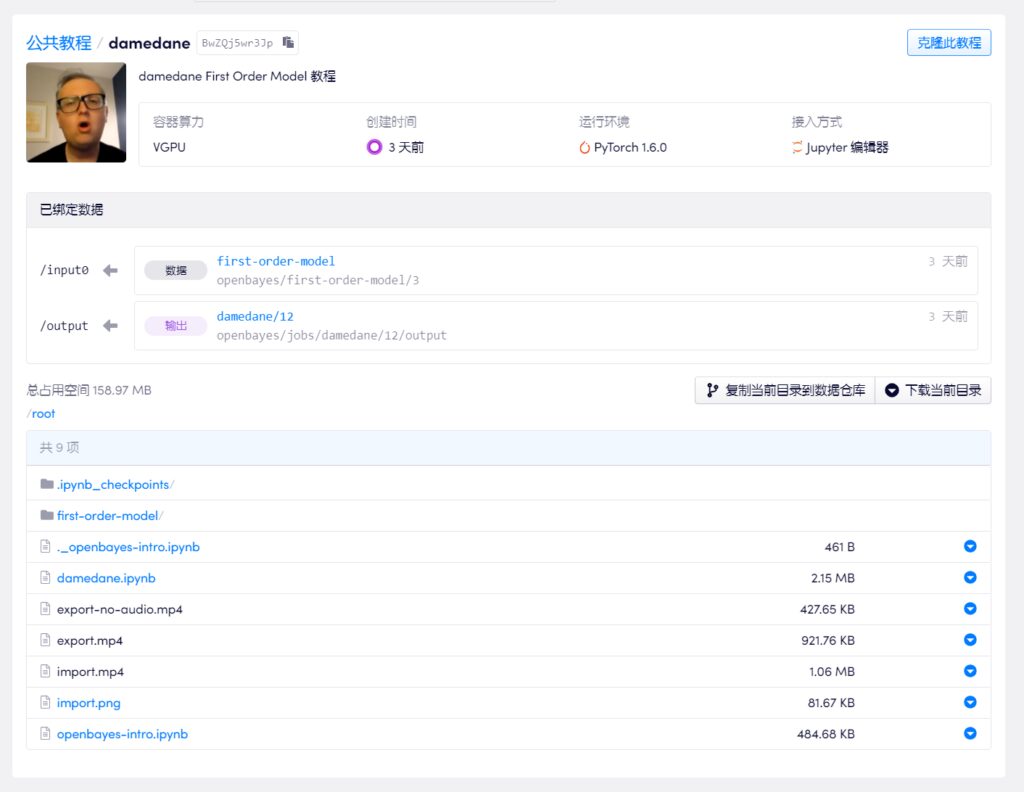
Adresse des Video-Tutorials:
https://openbayes.com/console/openbayes/containers/BwZQj5wr3Jp
Ursprüngliche Github-Adresse des Projekts:
https://github.com/AliaksandrSiarohin/first-order-model
Ein weiteres Werkzeug zur Gesichtsveränderung: Wozu dient es?
Das Bewegungsmodell erster Ordnung stammt aus einem Paper, das auf der Top-Konferenz NeurlPS 2019 vorgestellt wurde.Bewegungsmodell erster Ordnung für Bildanimation,Die Autoren kommen von der Universität Trient in Italien und snap.

Wie Sie dem Titel entnehmen können,Das Ziel dieses Dokuments besteht darin, statischen Bildern Bewegung zu verleihen.Lassen Sie bei einem Quellbild und einem Fahrvideo das Bild im Quellbild parallel zu den Aktionen im Fahrvideo mitlaufen. Das heißt, alles in Bewegung zu bringen.
Der Effekt ist in der folgenden Abbildung dargestellt. Die obere linke Ecke ist das Fahrvideo und der Rest sind statische Quellbilder:

Zusammensetzung des Modellrahmens
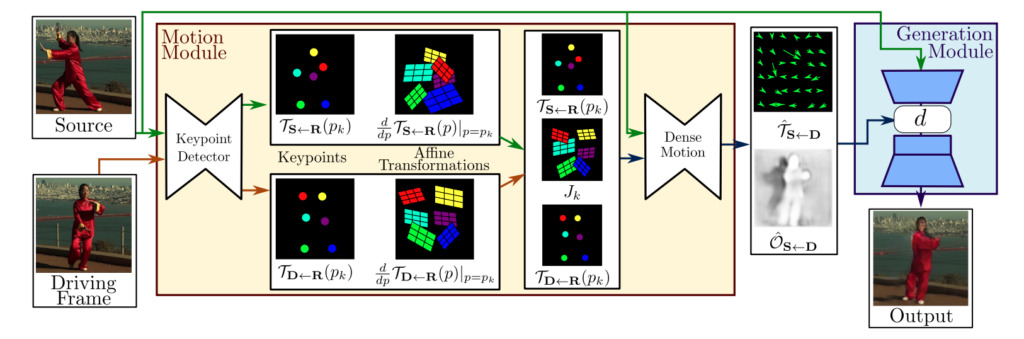
Im Allgemeinen besteht der Rahmen des Bewegungsmodells erster Ordnung aus zwei Modulen:Modul zur Bewegungsschätzung und Bilderzeugungsmodul.
Modul zur Bewegungsschätzung:Durch selbstüberwachtes Lernen werden Erscheinungs- und Bewegungsinformationen des Zielobjekts getrennt und als Merkmale dargestellt.
Bildgenerierungsmodul:Das Modell modelliert die Okklusionen, die während der Zielbewegung auftreten, extrahiert dann Erscheinungsinformationen aus einem gegebenen Prominentenbild und kombiniert sie mit der zuvor erhaltenen Merkmalsdarstellung für die Videosynthese.
Inwiefern ist es besser als das traditionelle Modell?
Manche Leute fragen sich vielleicht, worin der Unterschied zu früheren KI-Methoden zur Gesichtsveränderung besteht. Der Autor gibt eine Erklärung.
Für den vorherigen Videovorgang zur Gesichtsänderung waren die folgenden Vorgänge erforderlich:
- Normalerweise ist es notwendig, vorab ein Training mit den Gesichtsbilddaten beider auszutauschenden Parteien durchzuführen.
- Es ist notwendig, die wichtigsten Punkte des Quellbildes zu kommentieren und dann ein entsprechendes Modelltraining durchzuführen.
Doch in Wirklichkeit gibt es weniger persönliche Gesichtsdaten und nicht viel Zeit für Schulungen.Daher funktionieren herkömmliche Modelle bei bestimmten Bildern normalerweise besser, bei der Verwendung an der breiten Öffentlichkeit lässt sich die Qualität jedoch nur schwer garantieren und sie sind fehleranfällig.

Daher löst die in diesem Artikel vorgeschlagene Methode das Problem der Datenabhängigkeit und verbessert die Generierungseffizienz erheblich. Ausdruck und Handlungsübertragung erreichen wollen,NurEs muss nur anhand von Bilddatensätzen derselben Kategorie trainiert werden.
Wenn Sie beispielsweise eine Ausdrucksübertragung erreichen möchten, müssen Sie, unabhängig davon, wessen Gesicht Sie ersetzen, nur mit dem Gesichtsdatensatz trainieren. Wenn Sie eine Tai-Chi-Bewegungsübertragung erreichen möchten, können Sie den Tai-Chi-Videodatensatz zum Training verwenden.
Nach Abschluss des Trainings können Sie mithilfe des entsprechenden vortrainierten Modells das Quellbild zusammen mit dem Fahrvideo bewegen.

Der Autor verglich seine Methode mit den fortschrittlichsten Methoden auf diesem Gebiet, X2Face und Monkey-Net. Die Ergebnisse zeigten, dass im selben Datensatz alle Indikatoren dieser Methode verbessert wurden.Bei zwei Gesichtsdatensätzen (VoxCeleb und Nemo) übertrifft unsere Methode X2Face, das ursprünglich zur Gesichtsgenerierung vorgeschlagen wurde, auch deutlich.

-- über--








