Command Palette
Search for a command to run...
Das Heißeste ECCV Der Geschichte Hat Eröffnet, Und Diese Papiere Sind so Interessant

Die ECCV 2020, eine der drei wichtigsten internationalen Konferenzen im Bereich Computer Vision, fand vom 23. bis 27. August online statt. In diesem Jahr wurden bei der ECCV insgesamt 1.361 Beiträge angenommen. Wir haben die 15 beliebtesten Artikel ausgewählt, um sie mit den Lesern zu teilen.
Aufgrund der Auswirkungen der Epidemie wurde die diesjährige ECCV 2020 wie andere Top-Konferenzen von offline auf online umgestellt und begann am 23. August.

ECCV, der vollständige Name lautet European Conference on Computer Vision (Europäische Internationale Konferenz für Computer Vision),Es handelt sich um eine der drei wichtigsten internationalen Konferenzen zum Thema Computer Vision (die anderen beiden sind CVPR und ICCV) und findet alle zwei Jahre statt.
Obwohl die Epidemie dieses Jahres die Pläne vieler Menschen durcheinandergebracht hat, ist die Begeisterung aller für die wissenschaftliche Forschung und das Einreichen von wissenschaftlichen Arbeiten ungebrochen. Laut StatistikBeim ECCV 2020 gingen insgesamt 5.025 gültige Einsendungen ein, mehr als doppelt so viele wie in der vorherigen Sitzung (2018), und daher gilt es als das „heißeste ECCV der Geschichte“.
Schließlich wurden 1.361 Artikel zur Veröffentlichung angenommen, mit einer Annahmequote von 27%.Unter den angenommenen Beiträgen befinden sich 104 mündliche Beiträge, die 21 TP3T der insgesamt gültigen Einreichungen ausmachen, und 161 Spotlight-Beiträge, die etwa 31 TP3T ausmachen. Bei den restlichen Papieren handelt es sich um Poster.
Posenschätzung, 3D-Punktwolke, Liste hervorragender Artikel
Welche spannenden Forschungsergebnisse hat uns dieses Großereignis im Bereich Computer Vision in diesem Jahr gebracht?
Wir haben 15 Artikel aus den ausgewählten Artikeln ausgewählt, die mehrere Richtungen abdecken, wie etwa 3D-Objekterkennung, Posenabschätzung, Bildklassifizierung und Gesichtserkennung.
Fußgänger-Neuidentifizierung „Bitte nicht stören: Fußgänger-Neuidentifizierung unter Beeinträchtigung anderer Fußgänger“

Einheit:Huazhong Universität für Wissenschaft und Technologie, Sun Yat-sen Universität, Tencent Youtu Lab
Zusammenfassung:
Bei der herkömmlichen Personenidentifizierung wird davon ausgegangen, dass das zugeschnittene Bild nur eine einzige Person enthält. In Szenen mit vielen Menschen können handelsübliche Detektoren jedoch Begrenzungsrahmen mit mehreren Personen und einem großen Anteil Fußgänger im Hintergrund oder menschlicher Verdeckungen erzeugen.
Die aus diesen Bildern mit Fußgängerinterferenzen extrahierten Merkmale können Interferenzinformationen enthalten, die zu falschen Abrufergebnissen führen.
Um dieses Problem zu lösen, schlägt dieses Dokument ein neues tiefes Netzwerk (PISNet) vor. PISNet verwendet zunächst das bildgesteuerte Aufmerksamkeitsmodul „Query“, um die Merkmale des Ziels im Bild zu verbessern.
Darüber hinaus schlagen wir ein Rückwärtsaufmerksamkeitsmodul und eine Mehrpersonen-Trennverlustfunktion vor, um das Aufmerksamkeitsmodul zu unterstützen und die Störungen anderer Fußgänger zu unterdrücken.Unsere Methode wird anhand von zwei neuen Datensätzen zu Fußgängerinterferenzen evaluiert und die Ergebnisse zeigen, dass sie die modernsten Re-ID-Methoden übertrifft.

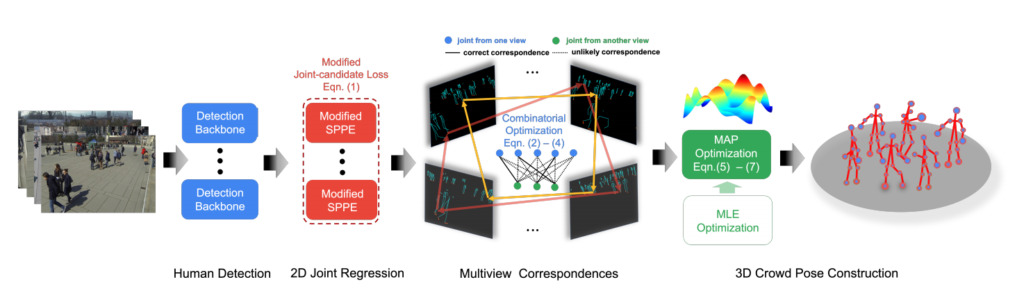
Posenschätzung „3D-Posenschätzung mehrerer Personen in überfüllten Szenen mittels Multi-Viewpoint-Geometrie“

Einheit:Johns Hopkins University, National University of Singapore
Zusammenfassung:
Extrema-Einschränkungen sind das Kernproblem der Merkmalsübereinstimmung und Tiefenschätzung bei aktuellen 3D-Methoden zur Schätzung der menschlichen Pose mit mehreren Maschinen. Obwohl die Formulierung in Szenen mit spärlichen Menschenmengen zufriedenstellend funktioniert, wird ihre Wirksamkeit in Szenen mit dichten Menschenmengen häufig in Frage gestellt, hauptsächlich aufgrund der Mehrdeutigkeit aus zwei Quellen.
Der erste Grund ist die Nichtübereinstimmung menschlicher Gelenke aufgrund einfacher Hinweise, die durch den euklidischen Abstand zwischen Gelenken und Epipolarlinien gegeben sind. Das zweite Problem ist die mangelnde Robustheit, die auf die naive Minimierung des Problems mit der Methode der kleinsten Quadrate zurückzuführen ist.
In diesem ArtikelWir weichen von der Formulierung zur 3D-Posenschätzung mehrerer Personen ab und formulieren sie als Schätzung der Pose einer Menschenmenge neu.Unser Ansatz besteht aus zwei Schlüsselkomponenten: einem grafischen Modell für schnelles Cross-View-Matching und einem Maximum-a-posteriori-Schätzer (MAP) für die 3D-Rekonstruktion der menschlichen Pose. Wir demonstrieren die Wirksamkeit und Überlegenheit unseres Ansatzes anhand von vier Benchmark-Datensätzen.
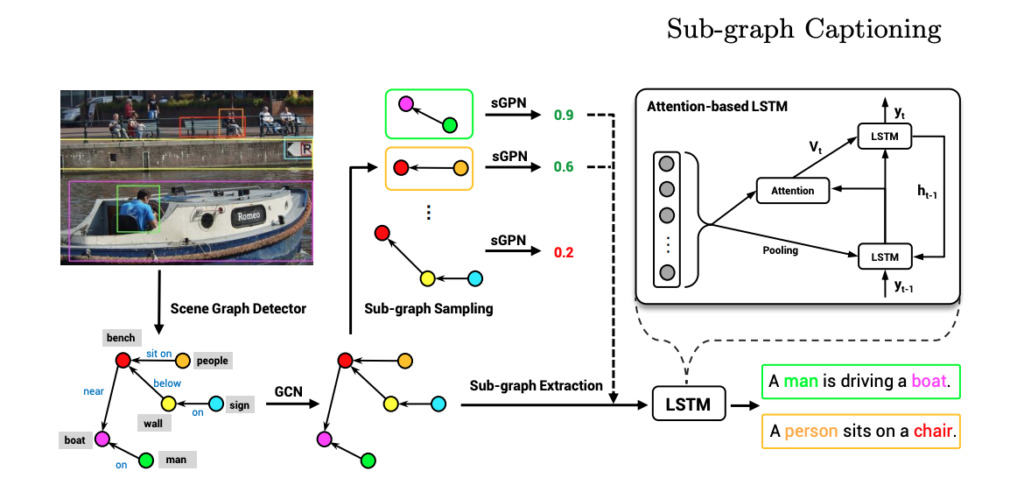
Bilder beschreiben 《Generierung einer Beschreibung in natürlicher Sprache durch Szenengraphzerlegung》

Einheit:Tencent AI Lab, Universität von Wisconsin-Madison
Zusammenfassung:
In diesem Artikel wird eine Methode zur Generierung natürlicher Sprachbeschreibungen auf Grundlage der Szenengraphenzerlegung vorgeschlagen.
Die Beschreibung von Bildern mithilfe natürlicher Sprache ist eine anspruchsvolle Aufgabe. In diesem Artikel wird der Ausdruck von Bildszenengraphen untersucht und eine Methode zur Generierung einer natürlichsprachlichen Beschreibung von Bildern auf Grundlage der Szenengraphenzerlegung vorgeschlagen. Der Kern dieser Methode besteht darin, den einem Bild entsprechenden Szenengraphen in mehrere Untergraphen zu zerlegen, wobei jeder Untergraph einem Teil des Inhalts oder einem Teil des Bildbereichs entspricht.Durch die Auswahl wichtiger Teilgraphen durch ein neuronales Netzwerk zur Generierung eines vollständigen Satzes zur Beschreibung des Bildes kann diese Methode genaue, vielfältige und kontrollierbare Beschreibungen in natürlicher Sprache generieren.Die Forscher führten außerdem umfangreiche Experimente durch und die Ergebnisse zeigten die Vorteile dieses neuen Modells.
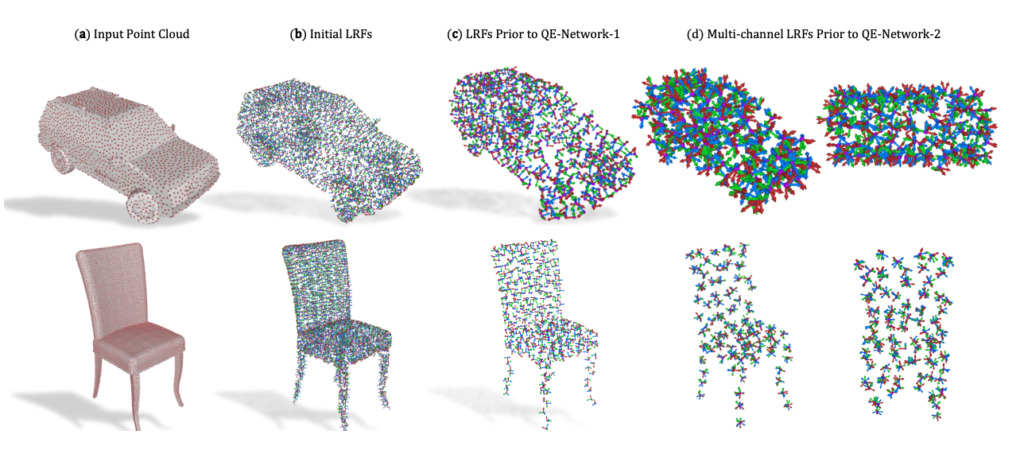
3D-Punktwolken Quaternionen-äquivariante Kapselnetzwerke für 3D-Punktwolken

Einheit:Stanford University, Technische Universität Dortmund, Universität Padua
Zusammenfassung:
Wir schlagen eine 3D-Kapselarchitektur zur Verarbeitung von Punktwolken vor, die SO(3)-Gruppen von Rotationen, Translationen und Permutationen eines ungeordneten Eingabesatzes entspricht.
Das Netzwerk arbeitet mit einer spärlichen Menge lokaler Referenzrahmen, die aus der Eingabepunktwolke berechnet werden. Das Netzwerk erreicht End-to-End-Varianzen durch eine neuartige 3D-Quaternionengruppen-Kapselschicht, die einen äquivarianten dynamischen Routing-Prozess umfasst.
Kapselebenen ermöglichen es uns, Geometrie und Pose zu trennen und so den Weg für informativere und strukturiertere latente Räume zu ebnen.Dabei verknüpfen wir den dynamischen Routing-Prozess zwischen Kapseln theoretisch mit dem bekannten Weiszfeld-Algorithmus zur Lösung des Problems der iterativ neu gewichteten kleinsten Quadrate (IRLS) mit nachweisbaren Konvergenzeigenschaften und erreichen so eine robuste Posenschätzung über alle Kapselschichten hinweg.
Dank spärlicher äquivarianter Quaternionenkapseln ermöglicht unsere Architektur eine gemeinsame Objektklassifizierung und Orientierungsschätzung, die wir anhand gängiger Benchmark-Datensätze empirisch validieren.
Gesichtserkennung 《Erklärbare Gesichtserkennung》

Einheit:System- und Technologieforschung, Visym Labs
Zusammenfassung:
Bei der erklärbaren Gesichtserkennung (kurz XFR) handelt es sich um das Problem, die von einem Gesichtsvergleicher zurückgegebenen Vergleichsergebnisse zu erklären.Dies gibt Aufschluss darüber, warum ein Detektor mit einer Identität übereinstimmt und mit einer anderen nicht.Das Verständnis dieses Prinzips kann das Vertrauen der Menschen in die Gesichtserkennung stärken und ihr Verständnis verbessern.
In diesem Dokument stellen wir die erste umfassende Benchmark- und Basisbewertung von XFR bereit. Wir definieren ein neues Bewertungsschema namens „Inpainting Game“, bei dem es sich um einen kuratierten Satz von 3648 Tripletts (Sonde, Partner, Nicht-Partner) von 95 Subjekten handelt, wobei durch synthetisches Inpainting ausgewählter Gesichtsmerkmale (wie Nase, Augenbraue oder Mund) ein gepatchter Nicht-Partner erstellt wird.
Die Aufgabe des XFR-Algorithmus besteht darin, eine Netzwerk-Aufmerksamkeitskarte zu generieren, die am besten anzeigt, welche Bereiche im Prüfbild mit dem gepaarten Bild übereinstimmen, und nicht die nicht übereinstimmenden Bereiche, die für jedes Triplett übermalt werden. Auf dieser Grundlage lässt sich quantifizieren, welche Bildbereiche für die Gesichtserkennung hilfreich sind.
Abschließend stellen wir einen umfassenden Benchmark für diesen Datensatz bereit, bei dem wir fünf hochmoderne Algorithmen anhand von drei Gesichtsvergleichern vergleichen. Dieser Benchmark umfasst zwei neue Algorithmen namens Subtree EBP und Density-based Input Sampling Explanation (DISE), die die Leistung bestehender hochmoderner Techniken deutlich übertreffen.
Wir zeigen auch qualitative Visualisierungen dieser Netzwerkaufmerksamkeitstechniken anhand neuer Bilder und untersuchen, wie diese erklärbaren Gesichtserkennungsmodelle die Transparenz und das Vertrauen in Gesichtsvergleicher verbessern können.

Altersschätzung 《Synthese zur Umrechnung von Lebensspanne in Alter》

Einheit:University of Washington, Stanford University, Adobe Research
Zusammenfassung:
Wir lösen das Problem der Altersprogression und -regression für ein einzelnes Foto – indem wir voraussagen, wie eine Person in der Zukunft oder in der Vergangenheit aussehen wird.
Die meisten bestehenden Alterungsmethoden beschränken sich auf Veränderungen der Textur und ignorieren die Veränderungen der Kopfform während des Alterns und Wachstums des Menschen. Dies schränkt die Anwendbarkeit bisheriger Methoden auf ältere Erwachsene ein und die Anwendung dieser Methoden auf Fotos von Kindern führt nicht zu qualitativ hochwertigen Ergebnissen.
Wir schlagen eine neuartige, mehrdomänenbasierte Bild-zu-Bild-Architektur für ein generatives kontradiktorisches Netzwerk vor, dessen gelernter latenter Raum einen kontinuierlichen bidirektionalen Alterungsprozess modelliert.Das Netzwerk wird anhand des FFHQ-Datensatzes trainiert, den wir nach Alter, Geschlecht und semantischer Segmentierung beschriften. Verwenden Sie feste Altersklassen als Ankerpunkte, um kontinuierliche Alterstransformationen anzunähern.Unser Framework kann anhand nur eines Fotos vollständige Kopfporträts im Alter von 0 bis 70 Jahren vorhersagen und die Textur und Kopfform ändern.Wir präsentieren Ergebnisse zu einer großen Vielfalt an Fotos und Datensätzen und zeigen erhebliche Verbesserungen gegenüber dem aktuellen Stand der Technik.

Portal: Papiere, Codes, alles mit einem Klick
Das Obige ist nur die Spitze des Eisbergs der Tausenden von ausgewählten Artikeln im ECCV 2020. Angesichts der riesigen Menge von 1.361 Artikeln ist es jedoch wirklich keine leichte Aufgabe, die Artikel, die Sie interessieren, sowie die Originallinks, Codes usw. zu finden.
Allerdings Paper Digest Team Das Team hat den Weg für Leser geebnet und das Auffinden von Dokumenten und Codes ist kein Problem mehr.
Das Team hat kürzlich eine Zusammenfassung der Highlights des ECCV 2020-Papiers in einem Satz veröffentlicht.Jeder Beitrag wurde in einem Satz zusammengefasst, der prägnant und auf den Punkt war, und die Adresse des Beitrags war beigefügt.Ermöglichen Sie den Lesern, schnell die Zeitungen zu finden, die sie am liebsten lesen möchten.

Die Adresse steht für Sie zur Mitnahme bereit:
Darüber hinaus haben sie sorgfältig 170 Artikel zusammengestellt, in denen Codes veröffentlicht wurden. Leser können direkt auf den entsprechenden Link klicken, um den Code anzuzeigen:
Darüber hinaus hat crossminds.ai auch die Präsentation des mündlichen Vortrags zusammengestellt, und die Leser können die Technologie im Vortrag anhand der Demo-Demonstration klarer und intuitiver verstehen, was sehr interessant ist:
https://crossminds.ai/category/eccv%202020/
-- über--








