Command Palette
Search for a command to run...
Informationsbeschaffung, Pfadplanung, E-Commerce, Was Sind Die Schlachtfelder Von KDD?

KDD 2020, die führende internationale Konferenz im Bereich Data Mining, startet nächste Woche. Von den 2.035 in diesem Jahr eingereichten Beiträgen wurden 338 angenommen. Unter ihnen zeigten inländische Technologiegiganten wie BAT, Didi und Huawei gute Leistungen.
Die jährliche internationale Konferenz zum Thema Data Mining und Wissensentdeckung ACM SIGKDD 2020 (Conference on Knowledge Discovery and Data Mining, kurz KDD),Es findet vom 23. bis 27. August online statt.

Mit der Entwicklung der Datenbanktechnologie und der kontinuierlichen Ansammlung von Daten hat der Bereich Data Mining immer mehr Aufmerksamkeit erhalten.
Auch die Zahl der Einreichungen bei KDD ist in den letzten Jahren deutlich gestiegen, von 1.115 im Jahr 2016 auf 2.035 in diesem Jahr. Der Beitrag der Chinesen zu diesen Arbeiten wird immer größer und die Ergebnisse sind sehr beeindruckend.
KDD ist in seinem 26. Jahr, und die wissenschaftliche Forschungsstärke der Chinesen nimmt von Jahr zu Jahr zu
KDD begann 1995 und wird jährlich vom ACM Special Committee on Data Mining and Knowledge Discovery (SIGKDD) veranstaltet.Von der CCF (China Computer Federation) als internationale Konferenz der Klasse A empfohlen.Es gilt als „Weltmeisterschaft“ im Bereich Data Mining.
Als weltweit hochrangigste internationale Konferenz im Bereich Data Mining ist die KDD für ihre strenge Annahmequote für Beiträge bekannt. Die jährliche Annahmequote übersteigt nicht 201 TP3T, und dieses Jahr ist da keine Ausnahme.
Am 25. Mai gab KDD 2020 die angenommenen Beiträge offiziell bekannt.In diesem Jahr wurden insgesamt 1.279 Arbeiten im Forschungsbereich (wissenschaftliche Arbeiten für die Forschungsgemeinschaft) eingereicht und 216 angenommen, sodass die Annahmequote bei 16,81 TP3T lag.
Für den Track „Applied Data Science“ (den praxisorientierten Track für die Industrie) wurden 756 Arbeiten eingereicht.121 Beiträge wurden angenommen, die Annahmequote lag bei 16%.
Dieses Jahr ist der 26. KDD. Den Statistiken zur Zahl der veröffentlichten Arbeiten und der gewonnenen Auszeichnungen zufolge hat die Beteiligung von Chinesen an KDD in den letzten Jahren von Jahr zu Jahr zugenommen, ihre Leistungen wurden immer besser, immer mehr Arbeiten wurden ausgewählt und sie haben viele Preise gewonnen.
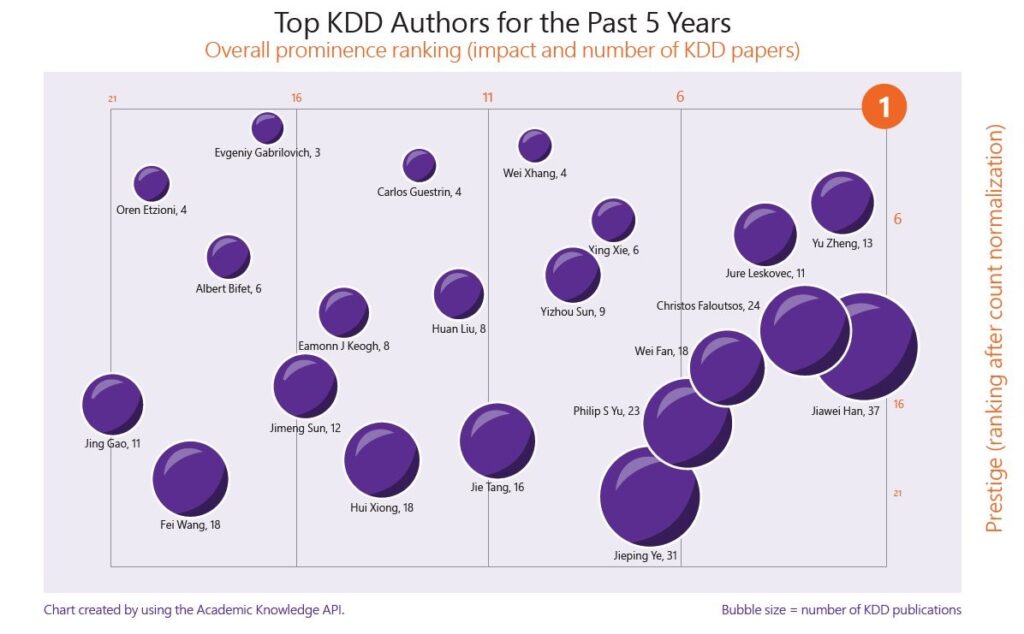
In den letzten Jahren sind die Leistungen großer inländischer Technologieunternehmen im KDD-Bereich immer beeindruckender geworden.
Laut Statistik haben die drei großen BAT-Unternehmen im Jahr 2018 insgesamt 12 Artikel veröffentlicht. In diesem Jahr veröffentlichte Alibaba allein 25 Artikel, Tencent 10 Artikel, Baidu 9 Artikel und Didi, Huawei und JD.com jeweils 6 Artikel.
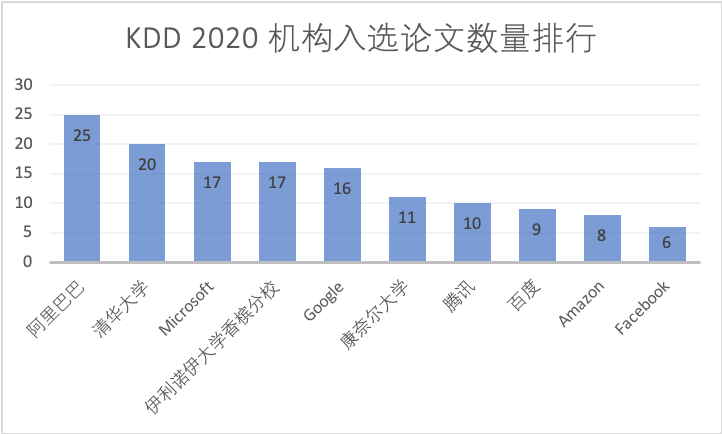
KDD 2020: Wo ist das Schlachtfeld für große Unternehmen?
Wir haben die angenommenen Beiträge großer inländischer Unternehmen nach Anwendungsszenarien sortiert, damit jeder sie lernen und nachschlagen kann. Einige dieser Artikel wurden auf arXiv veröffentlicht, Sie können also einen kleinen Vorgeschmack darauf werfen.
Informationsabruf „Extrahieren privilegierter Funktionen aus Taobao-Empfehlungen“

Einheit: Alibaba
Zusammenfassung:Funktionen spielen bei Vorhersageaufgaben im E-Commerce eine wichtige Rolle. Um die Konsistenz zwischen Offline-Schulung und Online-Bereitstellung zu gewährleisten, verwenden wir normalerweise für beide die gleichen Funktionen. Diese Konsistenz lässt jedoch einige Unterscheidungsmerkmale außer Acht. So liefern beispielsweise Merkmale wie die Verweildauer auf einer Produktdetailseite Aufschluss über die Abschätzung der Conversion Rate (CVR), also der Wahrscheinlichkeit, mit der ein Nutzer das Produkt nach einem Klick kauft. Allerdings sollten CVR-Vorhersagen online vorgenommen werden, bevor ein Klick erfolgt.Wir definieren die Merkmale, die diskriminierend sind, aber nur im Training verwendet werden können, als privilegierte Merkmale. Basierend auf der Destillationstechnik zum Überbrücken der Lücke zwischen Training und Inferenz schlägt dieses Dokument einen Algorithmus zur Merkmalsfraktionierung (PFD) vor.Wir haben Experimente mit zwei grundlegenden Vorhersageaufgaben für Taobao-Empfehlungen durchgeführt, nämlich der Klickrate für die grobkörnige Rangfolge und der CVR für die feinkörnige Rangfolge. Durch das Extrahieren der verbotenen interaktiven Funktionen während der CTR-Bereitstellung und der Post-hoc-Funktionen für CVR erzielen wir erhebliche Verbesserungen gegenüber ihren starken Basislinien. Beim Online-A/B-Test verbesserte sich Click Metrics in der CTR-Aufgabe um +5,0%. Bei der CVR-Aufgabe wird die Konvertierungsmetrik um 2,3% verbessert. Darüber hinaus erreichen wir durch die Behandlung mehrerer Probleme beim PFD-Training eine vergleichbare Trainingsgeschwindigkeit als Basislinie ohne jegliche Destillation.
Papieradresse:
https://arxiv.org/abs/1907.05171
Informationsabruf „Kontrollierbares Rahmenwerk für Empfehlungen mit mehreren Interessen“

Einheit: Alibaba
Zusammenfassung:In den letzten Jahren wurden neuronale Netzwerke im Zuge der rasanten Entwicklung der Deep-Learning-Technologie häufig in Empfehlungssystemen für den E-Commerce eingesetzt. Wir formalisieren das Empfehlungsproblem des Empfehlungssystems als ein sequenzielles Empfehlungsproblem mit dem Ziel, das nächste Element vorherzusagen, mit dem ein Benutzer wahrscheinlich interagieren wird. Neuere Arbeiten geben meist eine ganzheitliche Einbettung in die Verhaltenssequenzen der Nutzer vor. Eine einheitliche Benutzereinbettung kann jedoch nicht die vielfältigen Interessen eines Benutzers über einen bestimmten Zeitraum hinweg widerspiegeln. In diesem Artikel schlagen wir ein neuartiges steuerbares Multi-Interest-Framework für sequenzielle Empfehlungen namens ComiRec vor. Unser Multi-Interest-Modul erfasst mehrere Interessen aus Benutzerverhaltenssequenzen und kann zum Abrufen von Kandidatenelementen aus einem umfangreichen Elementpool verwendet werden. Diese Elemente werden dann in ein Aggregationsmodul eingespeist, um allgemeine Empfehlungsinformationen zu erhalten. Das Aggregationsmodul verwendet steuerbare Faktoren, um die Genauigkeit und Vielfalt der Empfehlungen auszugleichen. Wir führen sequenzielle Empfehlungsexperimente mit zwei realen Datensätzen durch: Amazon und Taobao.Experimentelle Ergebnisse zeigen, dass unser Framework im Vergleich zu den modernsten Modellen erhebliche Verbesserungen erzielt. Unser Framework wurde auch erfolgreich auf der Offline-Distributed-Cloud-Plattform von Alibaba bereitgestellt.
Papieradresse:
https://arxiv.org/abs/2005.09347
Informationsabruf: „Ein präzises und vielfältiges Empfehlungsframework basierend auf einem Bayesian Graph Convolutional Neural Network“

Unternehmen: Huawei
Zusammenfassung:In Empfehlungssystemen ist das genaue Erlernen der Darstellung von Benutzern und Elementen ein sehr wichtiges Thema. Mit der umfassenden Forschung und Anwendung von Graph-Convolutional-Netzwerken hat die Anwendung von Graph-Convolutional-Netzwerken auf Empfehlungssysteme immer mehr Aufmerksamkeit erregt. Alle vorhandenen graphenbasierten Empfehlungsmodelle betrachten den beobachteten Graphen der Benutzer-Element-Interaktion als Grundwahrheit zwischen Benutzern und Elementen. Im Kontext von Empfehlungssystemen ist diese Einstellung jedoch nicht immer sinnvoll. Beispielsweise werden mit dieser Einstellung Interaktionen ohne Kanten im Interaktionsdiagramm als negative Beispiele behandelt, und solche unbeobachteten Interaktionen können in der Zukunft potenzielle Interaktionen sein. Andererseits können einige beobachtete Kanten unwirklich sein oder durch Rauschen verursacht werden. Um dieses Problem zu lösen,In dieser Arbeit verwenden wir das Bayesian Graph Convolutional Network (BGCN), um Unsicherheit in Benutzer-Element-Interaktionsdiagrammen zu modellieren.
Wir schlagen eine detaillierte BPR-Verlustfunktion für den Trainingsprozess vor und diskutieren auch ausführlich, wie mit unserem Modell Vorhersagen getroffen werden können. Wir haben unser Modell anhand von vier öffentlichen Datensätzen validiert und festgestellt, dass unser BGCN-Modell in allen Bewertungsmetriken bestehende, auf Graphen basierende Empfehlungsmodelle übertraf. Wir haben dies auch anhand von Produktdatensätzen überprüft und festgestellt, dass auch die Genauigkeit des BGCN-Modells verbessert wurde.Darüber hinaus haben wir festgestellt, dass die Empfehlungsergebnisse unseres BGCN-Modells sowohl Genauigkeit als auch Vielfalt berücksichtigen und der Empfehlungseffekt bei „Kaltstart“-Benutzern signifikanter ist.
Verwandte Links:
https://zhuanlan.zhihu.com/p/142812078
Pfadplanung „Polestar: Ein intelligenter, effizienter, landesweiter Pfad-Engine für den öffentlichen Nahverkehr“

Einheit: Baidu
Zusammenfassung:Öffentliche Verkehrsmittel spielen im täglichen Leben der Menschen eine wichtige Rolle. Es ist erwiesen, dass öffentliche Verkehrsmittel umweltfreundlicher, effizienter und wirtschaftlicher sind als jede andere Form der Fortbewegung. Da die Verkehrsnetze jedoch immer größer und die Reisesituationen komplexer werden, wird es für die Menschen immer schwieriger, mit öffentlichen Verkehrsmitteln effizient die beste Route von einem Ort zum anderen zu finden. Zu diesem Zweck schlagen wir in diesem Artikel Polestar vor, eine datengesteuerte Engine für intelligentes und effizientes Routing im öffentlichen Nahverkehr. Konkret schlagen wir zunächst ein neues Public Transport Graph (PTG)-Modell für öffentliche Verkehrssysteme mit verschiedenen Reisekosten, wie etwa Zeit oder Entfernung, vor. Wir führten dann eine allgemeineRoutensuchalgorithmen und eine effiziente Site-Binding-Methode zur effizienten Generierung von Kandidatenrouten. Darauf aufbauend schlagen wir ein Dual-Path-Kandidaten-Ranking-Modell vor, um Benutzerpräferenzen in dynamischen Reisesituationen zu erfassen. Abschließend demonstrieren Experimente mit zwei realen Datensätzen die Vorteile von NorthStar in Bezug auf Effizienz und Effektivität.Tatsächlich wurde Polestar bereits Anfang 2019 auf Baidu Maps eingesetzt, einem der größten Kartendienste der Welt. Bisher hat Polaris Dienste für mehr als 330 Städte bereitgestellt, mehr als 100 Millionen Anfragen pro Tag beantwortet und eine deutliche Steigerung der Klickraten der Benutzer erzielt.
Papieradresse:
https://arxiv.org/abs/2007.07195
Pfadplanung hybrider räumlich-zeitlicher Graph-Convolutional-Netzwerke: Verbesserung der Verkehrsvorhersage mit Navigationsdaten

Einheit: Alibaba
Zusammenfassung:Aufgrund der Popularität von Online-Navigationsdiensten, Mitfahrgelegenheiten und Smart-City-Projekten hat die Verkehrsprognose in letzter Zeit zunehmend an Interesse gewonnen. Aufgrund der nichtstationären Natur des Straßenverkehrs wird der Mangel an Kontextinformationen die Genauigkeit der Vorhersage grundsätzlich einschränken. Um dieses Problem zu lösen, schlagen wir ein Hybrid Spatiotemporal Graph Convolutional Network (H-STGCN) vor, das in der Lage ist, zukünftige Reisezeiten durch Nutzung von Daten zum bevorstehenden Verkehrsaufkommen abzuleiten. Insbesondere schlagen wir einen Algorithmus vor, um den bevorstehenden Verkehr von einer Online-Navigationsmaschine abzurufen. Unter Verwendung einer stückweise linearen Fluss-Dichte-Beziehung wandelt eine neuartige Transformatorstruktur das eingehende Volumen in eine äquivalente Reisezeit um. Wir kombinieren dieses Signal mit dem häufig verwendeten Laufzeitsignal und wenden dann eine Graphenfaltung an, um die räumlichen Abhängigkeiten zu erfassen.Insbesondere konstruieren wir eine zusammengesetzte Adjazenzmatrix, die die Nähe des angeborenen Transports widerspiegelt. Wir führen umfangreiche Experimente mit realen Datensätzen durch. Die Ergebnisse zeigen, dass H-STGCN modernste Methoden in verschiedenen Bereichen deutlich übertrifft, insbesondere bei der Vorhersage nicht wiederkehrender Staus.
Papieradresse:
https://arxiv.org/abs/2006.12715
Pfadplanung „Vorhersage individueller Verarbeitungseffekte bei großen Teamwettbewerben im Rahmen der Shared-Bicycle-Ökonomie“

Einheit: Didi
Zusammenfassung:Um das kumulative Benutzerengagement (z. B. kumulative Klicks) bei sequenziellen Empfehlungen zu maximieren, müssen normalerweise zwei potenziell widersprüchliche Ziele abgewogen werden, nämlich das Streben nach einem höheren unmittelbaren Benutzerengagement (z. B. Klickrate) und das Anregen der Benutzer zum Stöbern (d. h. mehr Artikel).In bestehenden Arbeiten werden diese beiden Aufgaben häufig getrennt untersucht, was häufig zu suboptimalen Ergebnissen führt.In diesem Artikel untersuchen wir dieses Problem aus der Perspektive der Online-Optimierung und schlagen einen flexiblen und praktischen Rahmen vor, um eine längere Browsing-Zeit des Benutzers und ein höheres unmittelbares Benutzerengagement gezielt gegeneinander abzuwägen. Indem wir Elemente als Aktionen, Benutzeranforderungen als Zustände und Benutzerabgänge als absorbierende Zustände betrachten, formulieren wir das Verhalten jedes Benutzers als einen personalisierten Markov-Entscheidungsprozess (MDP) und reduzieren so das Problem der Maximierung des kumulativen Benutzerengagements auf ein Problem des stochastischen kürzesten Pfads (SSP). Gleichzeitig wird durch die unmittelbare Schätzung der Benutzerbeteiligung und der Ausstiegswahrscheinlichkeiten gezeigt, dass das SSP-Problem durch dynamische Programmierung effektiv gelöst werden kann.Experimente mit realen Datensätzen demonstrieren die Wirksamkeit der Methode. Darüber hinaus wurde diese Methode auf einer großen E-Commerce-Plattform eingesetzt, wodurch die kumulierte Anzahl der Klicks um mehr als 7 % erhöht wurde.
Papieradresse:
Verbraucherdienste: Maximierung des kumulativen Benutzerengagements bei kontinuierlichen Empfehlungen: Eine Online-Optimierungsperspektive

Einheit: Alibaba
Zusammenfassung:Um das kumulative Benutzerengagement (z. B. kumulative Klicks) bei sequenziellen Empfehlungen zu maximieren, müssen normalerweise zwei potenziell widersprüchliche Ziele gegeneinander abgewogen werden, nämlich das Streben nach einem höheren unmittelbaren Benutzerengagement (z. B. Klickrate) und das Anregen des Benutzers zum Stöbern (d. h. mehr Artikelpräsenz). In bestehenden Studien werden diese beiden Aufgaben häufig getrennt untersucht, was oft zu suboptimalen Ergebnissen führt.
In diesem Artikel untersuchen wir dieses Problem aus der Perspektive der Online-Optimierung und schlagen einen flexiblen und praktischen Rahmen vor, um eine längere Browsing-Zeit des Benutzers und ein höheres unmittelbares Benutzerengagement gezielt gegeneinander abzuwägen. Indem wir Elemente als Aktionen, Benutzeranforderungen als Zustände und Benutzerabgänge als absorbierende Zustände betrachten, formulieren wir das Verhalten jedes Benutzers als personalisierten Markov-Entscheidungsprozess (MDP) und vereinfachen das Problem der Maximierung der kumulativen Benutzerbeteiligung zu einem Problem des stochastischen kürzesten Pfads (SSP). Gleichzeitig wird durch die Schätzung der momentanen Benutzerbeteiligung und der Ausstiegswahrscheinlichkeiten bewiesen, dass dynamische Programmierung das SSP-Problem effektiv lösen kann.Unsere Experimente mit realen Datensätzen zeigen die Wirksamkeit unseres Ansatzes. Darüber hinaus wurde diese Methode auf einer großen E-Commerce-Plattform eingesetzt, wodurch die kumulierte Anzahl der Klicks um mehr als 7 % erhöht wurde.
Papieradresse:
Verbraucherdienste „Intelligente Chatbots für den Kundenservice erstellen: Lernen, zeitnah zu reagieren“

Einheit: Didi
Zusammenfassung:
In den letzten Jahren haben intelligente Chatbots im Bereich des Kundenservice große Verbreitung gefunden. Eine der größten Herausforderungen für Chatbots bei der Aufrechterhaltung einer reibungslosen Konversation mit Kunden besteht darin, zum richtigen Zeitpunkt zu antworten. Die meisten fortgeschrittenen Chatbots verfolgen jedoch einen Interaktion-für-Interaktion-Ansatz.Solche Chatbots reagieren auf jede Äußerung des Kunden, was in manchen Fällen zu unangemessenen Antworten führen und den Gesprächsverlauf fehlleiten kann.
In diesem Artikel schlagen wir ein Multi-Round Response Trigger Model (MRTM) vor, um dieses Problem zu lösen. MRTM lernt durch ein selbstüberwachtes Lernschema aus groß angelegten Mensch-Maschine-Gesprächen zwischen Kunden und Agenten.Es nutzt die semantische Übereinstimmungsbeziehung zwischen Kontext und Antwort, um ein semantisches Übereinstimmungsmodell zu trainieren, und ermittelt die Gewichtung gleichzeitig auftretender Äußerungen im Kontext durch einen asymmetrischen Selbstaufmerksamkeitsmechanismus. Anhand der Gewichtungen wird dann ermittelt, ob auf einen gegebenen Kontext reagiert werden soll.
Wir führen umfangreiche Experimente mit zwei Konversationsdatensätzen durch, die aus realen Online-Kundendienstsystemen gesammelt wurden. Die Ergebnisse zeigen, dass MRTM die Basislinie deutlich übertrifft. Darüber hinaus haben wir MRTM in den Kundenservice-Chatbot von Didi integriert. Basierend auf der Fähigkeit, den geeigneten Reaktionszeitpunkt zu erkennen, kann der Chatbot Informationen aus mehreren Gesprächsrunden schrittweise aggregieren und zum geeigneten Zeitpunkt intelligentere Antworten geben.
Papieradresse:
https://dl.acm.org/doi/10.1145/3394486.3403390
E-Commerce „Duale heterogene Graph-Aufmerksamkeitsnetzwerke zur Verbesserung der Long-Tail-Leistung der Store-Suche im E-Commerce“

Einheit: Alibaba
Zusammenfassung:
Duale heterogene Graph-Aufmerksamkeitsnetzwerke zur Verbesserung der Long-Tail-Leistung der Shop-Suche im E-Commerce
Angesichts des enormen Wachstums der Taobao-Benutzer und -Shops steht die Shop-Suche vor mehreren einzigartigen Herausforderungen:
1) Viele Ladennamen können die von ihnen verkauften Produkte nicht vollständig zum Ausdruck bringen, d. h. es besteht eine semantische Lücke zwischen Benutzeranfragen und Ladennamen.
2) Aufgrund der fehlenden Benutzerinteraktion ist es schwierig, gute Suchergebnisse für Long-Tail-Abfragen bereitzustellen, und es ist schwierig, Long-Tail-Shops abzurufen, die für die Abfrage sehr relevant sind. Um diese beiden zentralen Herausforderungen zu bewältigen, wenden wir uns Graph Neural Networks (GNNs) zu. Speziell,Unter Verwendung von Benutzerinteraktionsdaten aus der Store-Suche und der Produktsuche schlagen wir ein Dual Heterogeneous Graph Attention Network (DHGAT) vor, das in eine Zwei-Turm-Architektur integriert ist.Zunächst erstellen wir einen heterogenen Graphen im Kontext der Ladensuche, indem wir die Nähe erster und zweiter Ordnung aus dem Suchverhalten, dem Klickverhalten und den Kaufaufzeichnungen der Benutzer nutzen. Anschließend konzentriert sich DHGAT auf die Übernahme der heterogenen und homogenen Nachbarn von Abfragen und Speichern, um seine eigene Darstellung zu verbessern und so das Long-Tail-Phänomen zu mildern.Darüber hinaus verringert DHGAT die semantische Lücke, indem es die Titel verwandter Elemente kombiniert und so die Semantik von Abfragetexten und Geschäftsnamen bereichert.
Papieradresse:
https://dl.acm.org/doi/10.1145/3394486.3403393
E-Commerce: Ein Werbeplan mit garantierter Auslieferung auf Anfrageebene: Vorhersage und Zuteilung》
Unternehmen: Tencent
Zusammenfassung:In der bestehenden Forschung zur Bereitstellung von Online-Werbung wird der Dienst üblicherweise als ein Problem der Angebotszuweisung auf Gruppen- oder Benutzerebene modelliert. Dabei wird davon ausgegangen, dass Suchergebnisse verfügbar sind und Verträge unterzeichnet wurden. Der Schwerpunkt liegt daher auf der Suche nach der besten Zuweisung für die Online-Bereitstellung. Diese Technologien reichen jedoch nicht aus, um den Anforderungen der heutigen Branchentrends gerecht zu werden:
1) Werbetreibende streben eine präzisere Zielgruppenansprache an, die nicht nur Attribute auf Benutzerebene, sondern auch Attribute auf Anfrageebene erfordert.
2) Benutzer bevorzugen benutzerfreundlichere Werbedienste, was zu stärkeren Einschränkungen bei der Werbung führt.
3) Der Engpass für das Umsatzwachstum der Verlage liegt nicht nur in den Werbedienstleistungen, sondern auch in der Prognosegenauigkeit und den Verkaufsstrategien.
Da der Maßstab von Modellen auf Anforderungsebene um mehrere Größenordnungen größer ist als der von Modellen auf Populations- oder Benutzerebene, ist die Lösung dieser Probleme nicht trivial.
Angesichts dieser Herausforderung schlugen wir ein ganzheitlich konzipiertes Werbeplanungssystem auf Anfrageebene mit garantierter Auslieferung vor und optimierten sorgfältig drei Schlüsselelemente, darunter Impression-Prognose, Vertrieb und Service.Unser System wurde im Online-Werbesystem mit garantierter Zustellung von Tencent eingesetzt und hat fast ein Jahr lang Milliarden von Benutzern bedient. Auswertungen umfangreicher realer Daten und der Leistung eingesetzter Systeme zeigen, dass unser Design die Genauigkeit und Bereitstellungsgeschwindigkeit der Impression-Vorhersage auf Anforderungsebene erheblich verbessern kann.
Papieradresse: Noch nicht veröffentlicht
INPREM: Ein erklärbares und vertrauenswürdiges Vorhersagemodell für das Gesundheitswesen

Unternehmen: Tencent
Zusammenfassung:
Der Aufbau prädiktiver Modelle für die personalisierte Medizin auf der Grundlage historischer elektronischer Gesundheitsakten ist zu einem aktiven Forschungsgebiet geworden. Dank ihrer leistungsstarken Funktionen zur Merkmalsextraktion haben Deep-Learning-Methoden bei vielen klinischen Vorhersageaufgaben gute Ergebnisse erzielt. Aufgrund der mangelnden Interpretierbarkeit und Glaubwürdigkeit ist die Anwendung in tatsächlichen klinischen Entscheidungsfällen jedoch schwierig.
Um dieses Problem zu lösen, schlagen wir in diesem Artikel ein interpretierbares und vertrauenswürdiges Vorhersagemodell (INPREM) für das Gesundheitswesen vor. Erstens ist INPREM als interpretierbares lineares Modell konzipiert, um Interpretierbarkeit zu erreichen. Gleichzeitig werden nichtlineare Beziehungen in die erlernten Gewichte kodiert, um die Abhängigkeiten zwischen und innerhalb jedes Besuchs zu modellieren.Dadurch erhalten wir die Beitragsmatrix der Eingangsvariablen,Als Beweis für die vorhergesagten Ergebnisse hilft es den Ärzten zu verstehen, warum das Modell eine solche Vorhersage macht, und macht das Modell dadurch besser interpretierbar.Zweitens platzieren wir aus Gründen der Zuverlässigkeit ein Zufallsgatter (das einer Bernoulli-Verteilung zum Ein- oder Ausschalten folgt) auf jedem Gewicht des Modells sowie einen zusätzlichen Zweig zur Schätzung des Datenrauschens. Das Modell verwendet Monte-Carlo-Sampling und eine Zielfunktion, die Datenrauschen berücksichtigt, um die Unsicherheit jeder Vorhersage zu erfassen. Die erfasste Unsicherheit wiederum informiert den Arzt über das Vertrauensniveau des Modells, wodurch das Modell vertrauenswürdiger wird. Wir zeigen empirisch, dass das vorgeschlagene INPREM gegenüber bestehenden Methoden erhebliche Vorteile hat.
Papieradresse:
https://dl.acm.org/doi/abs/10.1145/3394486.3403087
Die Registrierung für die KDD 2020 Online-Konferenz ist geöffnet
KDD 2020 ist in Bearbeitung und die Registrierung für die Konferenz ist jetzt geöffnet:
https://www.kdd.org/kdd2020/#!
Die vollständige Tagesordnung wurde bekannt gegeben. Interessierte Studierende können per Zoom an der Veranstaltung teilnehmen. Studententickets kosten 50 US-Dollar. Eine der mit größter Spannung erwarteten Sitzungen, die Eröffnungszeremonie und Preisverleihung, findet am 25. August von 8:00 bis 10:00 Uhr Ortszeit statt. Bitte bleiben Sie dran.
Den vollständigen Zeitplan finden Sie hier:
https://www.kdd.org/kdd2020/schedule
Quellen:
https://www.kdd.org/kdd2020/accepted-papers#ads-papers
https://www.aminer.cn/conf/kdd2020/papers
-- über--








