Command Palette
Search for a command to run...
1.1 T arXiv-Datensatz: 1,7 Millionen Papiere, Sie Können Es Im Nächsten Leben Sehen
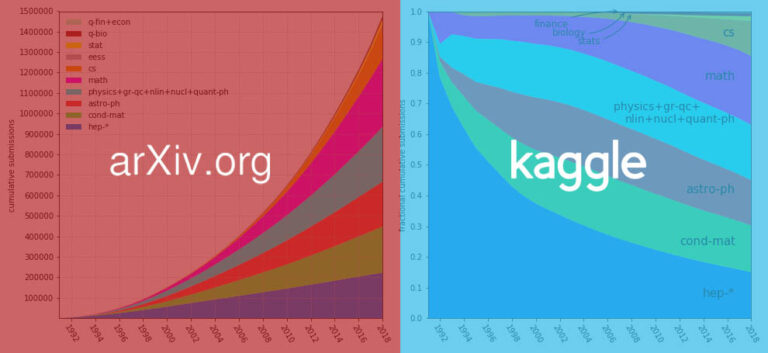
Vor Kurzem hat arXiv mehr als 1,7 Millionen Artikel in einem Datensatz zusammengefasst und auf der Kaggle-Plattform platziert, um den Zugriff auf und das Herunterladen von Artikeln in Zukunft zu vereinfachen. Der Datensatz ist derzeit etwa 1,1 TB groß und wird durch wöchentliche Updates weiter wachsen.
Mehr als 1,7 Millionen wissenschaftliche Arbeiten, 1,1 TB groß. Dies ist ein Datensatz, der kürzlich von arXix auf Kaggle geöffnet wurde. Als die Internetnutzer danach fragten, riefen sie: So cool!
Das Team für die Datensatzzusammenstellung sagte, es hoffe, entsprechende Forscher dazu inspirieren zu können, umfassendere Technologien des maschinellen Lernens zu erforschen und zu weiteren Entdeckungen und Innovationen zu gelangen.
Offene Datensätze erleichtern die Papiersuche
Seit fast 30 Jahren bietet arXiv der Öffentlichkeit und der Forschungsgemeinschaft offenen Zugang zu wissenschaftlichen Artikeln aus einem breiten Spektrum von Fachgebieten.Von den weitläufigen Zweigen der Physik über die vielen Zweige der Informatik bis hin zu allen Disziplinen wie Mathematik, Statistik, Elektrotechnik, quantitativer Biologie und Wirtschaftswissenschaften.
Es gibt viele Forschungsarbeiten auf arXiv, und obwohl viele Menschen davon profitieren,Allerdings wird häufig von Mängeln berichtet, wie beispielsweise umständliches Browsen, Suchen und Sortieren.Einige Leute haben sogar Tipps zur Suche nach Artikeln auf arXiv gefunden und diese mit Ihnen geteilt.
Um arXiv zugänglicher zu machen, bietet die Cornell University jetzt einen kostenlosen, offenen arXiv-Datensatz auf Kaggle an.
Der Datensatz enthält 1,7 Millionen wissenschaftliche Arbeiten sowie arbeitbezogene Elemente (Features) wie Artikeltitel, Autor, Kategorie, Zusammenfassung und Volltext-PDF.
Eleonora Presani, Geschäftsführerin von arXiv, sagte: „Dass das gesamte arXiv-Korpus auf Kaggle verfügbar ist, steigert das Potenzial der arXiv-Artikel enorm. Indem wir den Datensatz auf Kaggle bereitstellen, ermöglichen wir es den Menschen nicht mehr nur, Wissen durch das Lesen dieser Artikel zu erwerben,Noch wichtiger ist, dass die Daten und Informationen hinter arXiv der Öffentlichkeit in einem maschinenlesbaren Format zur Verfügung gestellt werden. "

Presani fügte hinzu: „arXiv ist mehr als nur ein Archiv für Artikel; es ist eine Plattform für den Wissensaustausch. Dies erfordert von uns Innovationen in der Präsentation und Interpretation verfügbaren Wissens. Kaggle-Nutzer können dazu beitragen, die Grenzen dieser Innovation zu erweitern, und es bietet uns einen neuen Kanal für die Zusammenarbeit mit der Community.“
Ansehen: Was enthält der arXiv-Datensatz?
Die grundlegenden Informationen des arXiv-Datensatzes lauten wie folgt:
arXiv-Datensatz
Herausgegeben von: Paul Ginsparg, Moonshot Factory, Jack Hidary
Enthaltene Menge:Mehr als 1,7 Millionen wissenschaftliche Arbeiten
Datenformat:json
Datengröße:1,1 TB
Veröffentlichungszeit:August 2020
Downloadadresse:https://www.kaggle.com/Cornell-University/arxiv
Derzeit stellt der arXiv-Datensatz eine Metadatendatei im JSON-Format bereit, die die relevanten Einträge für jedes Papier wie folgt enthält:
- id: Papierzugriffsadresse, die zum Zugriff auf das Papier verwendet werden kann;
- Einreicher: Einreicher des Papiers;
- Autoren: Autoren des Papiers;
- Titel: Titel des Papiers;
- Kommentare: weitere Informationen wie Seitenzahl und Abbildungen im Dokument;
- journal-ref: Informationen über die Zeitschrift, in der der Artikel veröffentlicht wurde;
- doi: digitaler Objektbezeichner;
- Zusammenfassung: Zusammenfassung des Papiers;
- Kategorien: die Kategorien oder Tags, zu denen das Papier in arXiv gehört;
- Versionen: Papierversionen.
Sie können diese umfangreichen Dokumente einfach durchsuchen, filtern und prüfen.
Darüber hinaus können Benutzer über die folgenden beiden Links direkt auf jedes Dokument auf arXiv zugreifen:
- https://arxiv.org/abs/{id}: die Seite mit dem Artikel, einschließlich der Zusammenfassung und anderer Links;
- https://arxiv.org/pdf/{id}: PDF-Downloadseite für Dokumente.
Auch Massenzugriff ist möglich: Das vollständige PDF ist kostenlos im Bucket gs://arxiv-dataset auf Google Cloud Storage oder über die Google API (JSON-Dokumentation und XML-Dokumentation) verfügbar.
Die PDF-Papierdateien sind in mehreren .tar.gz-Dateien im Ordner „tarpdfs“ gruppiert und der gesamte Datensatz ist ungefähr 1,1 TB groß. Die Einzelheiten sind wie folgt (nachfolgend sind der 1., 2. und 3. Teil der Felder im Januar 2010 (1001) aufgeführt):
tarpdfs/arXiv_pdf_1001_001.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_001.tar.gz)tarpdfs/arXiv_pdf_1001_002.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_002.tar.gz)tarpdfs/arXiv_pdf_1001_003.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_003.tar.gz)
Benutzer können Daten auch mit Tools wie gsutil auf ihren lokalen Computer herunterladen.

Doch was sind die konkreten Verwendungsszenarien dieses Datensatzes? Viele Internetnutzer haben bereits Ideen, beispielsweise zur Themenmodellierung und zur Verwendung der Daten zum Trainieren von GPT-3.
arXiv: Ein riesiges Archiv wissenschaftlicher Arbeiten
Studierende in der wissenschaftlichen Forschung und im akademischen Bereich müssen mit arXiv vertraut sein.
Es handelt sich um eine Website, die Vorabdrucke von Artikeln aus den Bereichen Physik, Mathematik, Informatik und Biologie sammelt. Es bietet wissenschaftlichen Forschern nicht nur eine Plattform zum „Aufbewahren von Ideen“, sondern dient auch als riesige Ressourcenbibliothek, in der jeder nach Artikeln suchen und diese lesen kann.
Bis Oktober 2008 hatte arXiv.org mehr als 500.000 Vorabdrucke gesammelt. bis Ende 2014 erreichte seine Sammlung 1 Million;Seit Oktober 2016 liegen die arXiv-Einreichungen bei über 10.000 pro Monat.
arXiv wurde 1991 vom Physiker Paul Ginsbag gegründet. Ursprünglich war es für die Sammlung von Vorabdrucken physikalischer Arbeiten gedacht, später wurde die Plattform auf andere Bereiche wie Astronomie und Mathematik ausgeweitet.
arXiv wurde ursprünglich am Los Alamos National Laboratory (LANL) gehostet und hieß daher in den Anfangstagen „LANL Preprint Database“. Derzeit ist arXiv an der Cornell University angesiedelt und verfügt über Spiegelseiten auf der ganzen Welt. Die Site wurde 1999 in arXiv.org umbenannt.
Einfach ausgedrückt ist arXiv eine Website zum „Reservieren eines Platzes“. Um zu verhindern, dass ihre Ideen von anderen plagiiert werden, bevor das Papier veröffentlicht wird, veröffentlichen die Forscher ihre Entwürfe auf arXiv, um ihre Originalität zu beweisen.
Quellen:
https://www.kaggle.com/Cornell-University/arxiv?select=arxiv-metadata-oai-snapshot.json
https://zh.wikipedia.org/wiki/ArXiv
-- über--








