Command Palette
Search for a command to run...
Lyft Veröffentlicht Den Größten Datensatz Zur Vorhersage Autonomen Fahrens Der Stufe L5 Und Startet Einen Wettbewerb Zur Bewegungsvorhersage
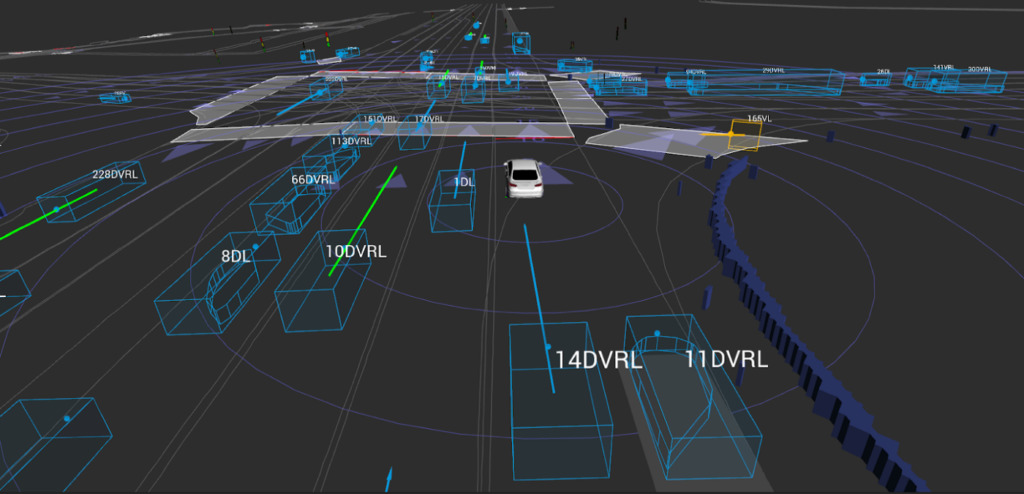
Lyft hat vor Kurzem einen Datensatz zur Vorhersage autonomen Fahrens der Stufe 5 veröffentlicht, der mehr als 1.000 Stunden Fahraufzeichnungen enthält. Darüber hinaus hat das Unternehmen einen Wettbewerb zur Bewegungsvorhersage beim autonomen Fahren mit einem Preisgeld von 30.000 US-Dollar gestartet.
Lyft hat einen neuen Datensatz veröffentlicht.
Im vergangenen Juli veröffentlichte Lyft einen L5-Wahrnehmungsdatensatz zum autonomen Fahren, der mehr als 55.000 von Menschen beschriftete 3D-annotierte Frames enthielt. Damals galt er offiziell als der größte öffentliche Datensatz seiner Art.
Nur ein Jahr später veröffentlichte Lyft einen Satz von L5-Vorhersagedatensätzen für autonomes Fahren.

Download-Adresse der Anwendung: https://www.catalyzex.com/paper/arxiv:2006.14480/dataset
170.000 Szenen und mehr als 2.500 Kilometer Straßendaten
Der von Lyft dieses Mal veröffentlichte Datensatz konzentriert sich auf die Bewegungsvorhersage.Offizielle Stellen sagten, dass ein langjähriges Forschungsproblem im Bereich des autonomen Fahrens darin bestehe, Modelle zu entwickeln, die robust und zuverlässig genug seien, um Verkehrsbewegungen vorherzusagen.
Die Daten wurden über einen Zeitraum von vier Monaten von einer Flotte aus 23 autonomen Fahrzeugen auf einer festen Route in Palo Alto, Kalifornien, gesammelt.Enthält Fahrtenprotokolle von Autos, Fußgängern und anderen aufgetretenen Hindernissen.
Der Datensatz umfasst insbesondere:
- 1000 Stunden:Mehr als 1.000 Stunden Aufzeichnungen der autonomen Fahrzeugbewegungen;
- 170.000 Szenen:Jede Szene dauert etwa 25 Sekunden und umfasst Ampeln, Luftbilder, Bürgersteige usw.;
- 16.000 Meilen: 16.000 Meilen (2.575 Kilometer) Daten von öffentlichen Straßen;
- 15242 kommentierte Bilder:Enthält eine hochauflösende semantische Karte der beschrifteten Elemente und eine hochauflösende Vogelperspektive des Bereichs.

Diese Bewegungsdaten werden von einem auf dem Dach der Lyft-Fahrzeuge montierten Sensorarray erfasst, das Lidar-, Kamera- und Radardaten aufzeichnet, während die Fahrzeuge Zehntausende von Kilometern zurücklegen.
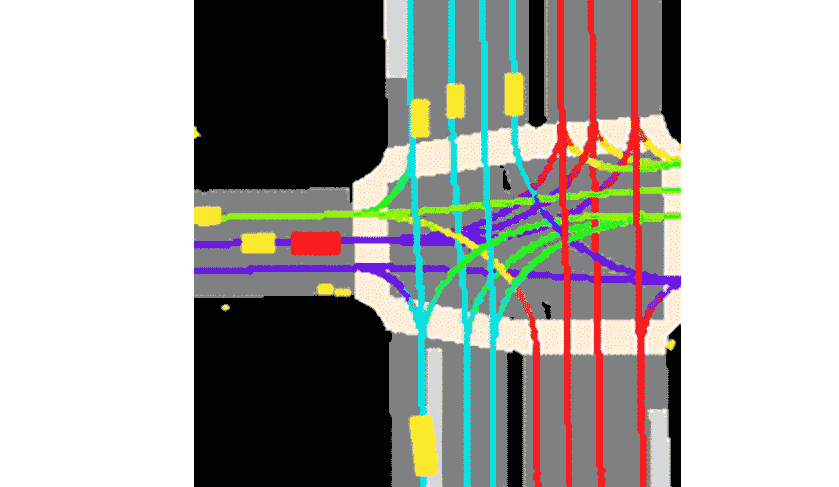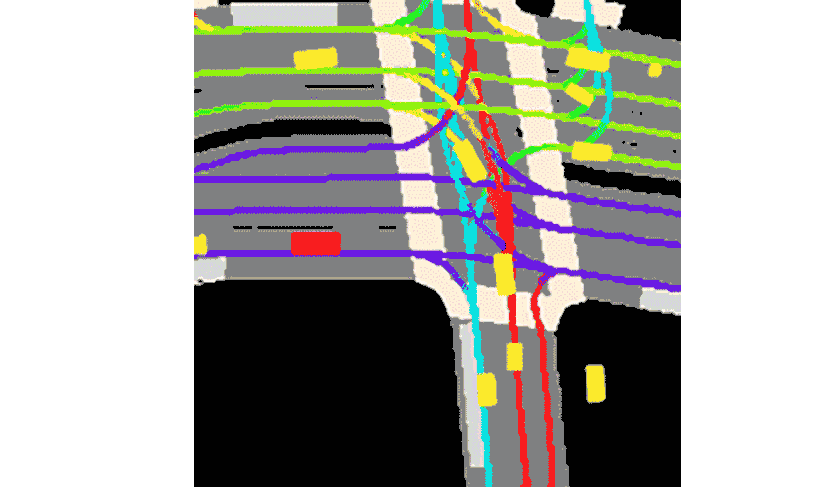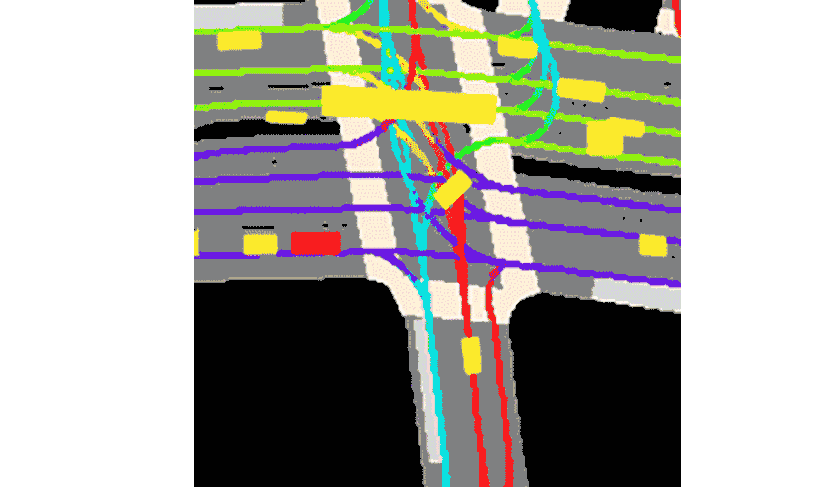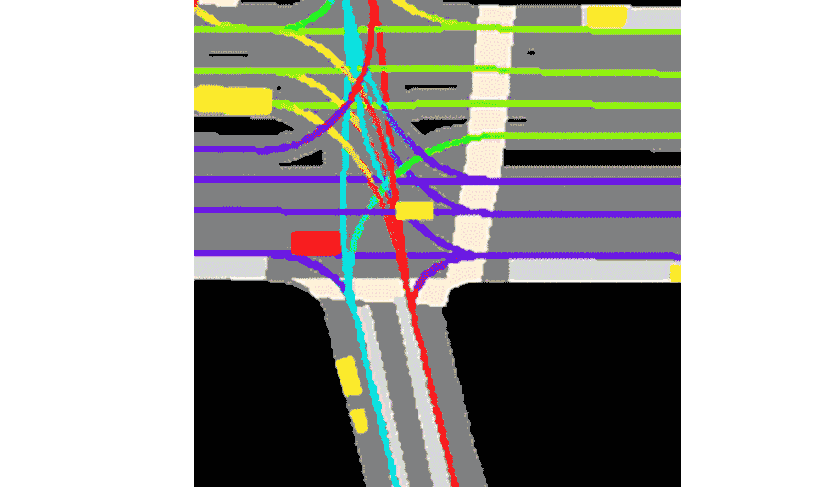
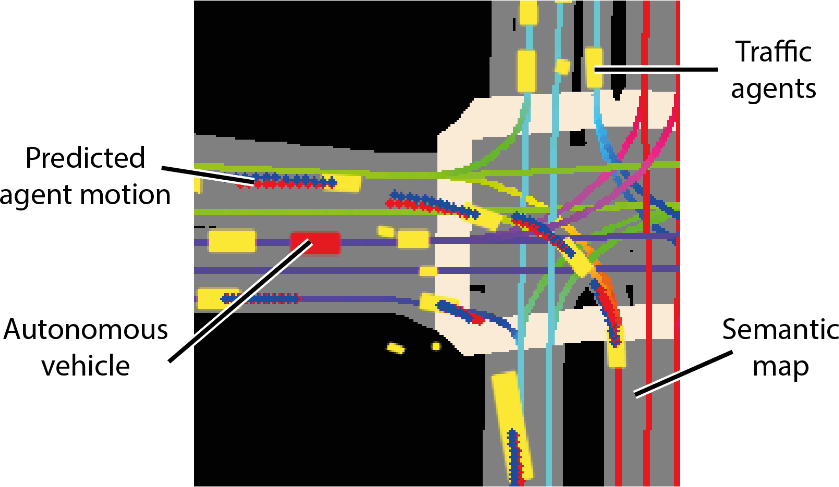
Lyft sagte, dass die Kollektion mit dem mitgelieferten Toolkit geliefert wird.Dies stellt den bislang größten, vollständigsten und detailliertesten Datensatz dar.Wird für die Entwicklung autonomen Fahrens und maschineller Lernaufgaben wie Bewegungsvorhersage, Planung und Simulation verwendet.
Derzeit stehen nur einige Teilmengen dieses Datensatzes zum Download zur Verfügung, darunter:
- Beispieldatensatz (53 MB)
- Trainingsdatensatz (aufgeteilt in drei Teile, insgesamt 69,4 GB)
- Vogelperspektive (2 GB)
- Semantischer Graph (2 MB)
Downloadadresse:
Starten Sie eine Challenge mit einem Preispool von 30.000 US-Dollar
gleichzeitig,Lyft plant außerdem, im August auf der Google Kaggle-Plattform einen Wettbewerb zu starten, bei dem Preise im Gesamtwert von 30.000 US-Dollar vergeben werden.

Die Highlights dieser Challenge:
- Wettbewerbsvoraussetzungen:Die Teilnehmer sagen die Bewegung von Fahrzeugen voraus.
- Vorbereitung:Offizielle Erinnerung: Ab sofort können Forscher und Ingenieure Trainingsdatensätze und Python-basierte Softwarepakete herunterladen, um mit den Daten zu experimentieren. Denn die Test- und Validierungskits werden im Rahmen des Wettbewerbs veröffentlicht;
- Endziel:Stärkung der Forschungsgemeinschaft und Beschleunigung von Innovationen durch Datensätze und Wettbewerbe.
Sacha Arnoud, leitender technischer Direktor bei Lyft, und Peter Ondruska, Leiter der Audio- und Videoforschung, schrieben in einem Blogbeitrag:„Daten sind die treibende Kraft hinter der Erprobung der neuesten Techniken des maschinellen Lernens.Obwohl der Zugriff auf umfangreiche und qualitativ hochwertige Daten zum autonomen Fahren begrenzt ist, sollte uns dies nicht davon abhalten, in diesem Bereich zu experimentieren. "
„Wir glauben, dass autonome Fahrzeuge ein bequemerer, sichererer und nachhaltigerer Teil des Transportsystems werden“, sagten Arnoud und Ondruska.„Durch den Datenaustausch mit der Forschungsgemeinschaft hoffen wir, wichtige und ungelöste Herausforderungen beim autonomen Fahren zu identifizieren."
KlickenLesen Sie den Originalartikel, können Sie mehr hochwertige Datensätze erhalten!
Blog-Adresse:
Papieradresse:
https://arxiv.org/pdf/2006.14480.pdf
GitHub-Adresse:
https://github.com/lyft/l5kit/
-- über--








