Command Palette
Search for a command to run...
Facebook Behauptet, Google Besiegt Und Den Leistungsstärksten Chatbot Auf Den Markt Gebracht Zu Haben

Facebook hat vor Kurzem einen neuen Chatbot namens Blender als Open Source veröffentlicht, der leistungsfähiger und persönlicher ist als bestehende Konversationsroboter.
Am 29. April veröffentlichte Facebooks KI- und Machine-Learning-Abteilung FAIR einen Blogbeitrag, in dem sie nach jahrelanger Forschung bekannt gab,Sie haben vor Kurzem einen neuen Chatbot namens Blender entwickelt und als Open Source veröffentlicht.
Blender kombiniert mehrere Konversationsfähigkeiten, darunter Persönlichkeit, Wissen und Empathie, um KI menschlicher zu machen.
Schlägt Google Meena, menschlicher
FAIR behauptet, dass Blender derDer größte Open-Domain-Chatbot(Open-Domain-Chatbots werden auch als kleine Talkbots bezeichnet), die bestehende Methoden zur Generierung von Gesprächen übertreffen.
Vortrainierte und fein abgestimmte Blender-Modelle sind auf GitHub verfügbar.Das Basismodell enthält bis zu 9,4 Milliarden Parameter, das ist 3,6-mal so viel wie das Konversationsmodell Meena von Google.
GitHub-Adresse: https://parl.ai/projects/blender/
Als Google Meena im Januar auf den Markt brachte, bezeichnete es es als den besten Chatbot der Welt.
Aber in Facebooks eigenen Tests, 75 % der menschlichen Bewerter fanden Blender ansprechender als Meena,67 % der Tester fanden außerdem, dass Blender menschlicher klang.Weitere 49 Prozent der Befragten konnten zunächst nicht zwischen einem Chatbot und einer realen Person unterscheiden.
Was Blender von normalen Chatbots unterscheidet, ist, dass er auf interessante Weise über alles reden kann. Es hilft virtuellen Assistenten nicht nur dabei, viele ihrer Defizite zu beheben, sondern verspricht auch, dass Konversations-KI-Systeme (wie Alexa, Siri und Cortana) natürlicher als je zuvor mit Menschen interagieren und eine große Bandbreite an Fragen stellen und beantworten können, sei es in Unternehmens-, Industrie- oder Verbraucherumgebungen.Es drückt auch Emotionen wie Sympathie und Ernsthaftigkeit aus.
Google hat auf Anfragen der Medien um einen Kommentar zu diesem Ergebnis noch nicht reagiert.
Blenders Killer-Feature: riesige Trainingsdaten
Die Stärke von Blender liegt in der schieren Größe seiner Trainingsdaten.Es wurde anhand von 1,5 Milliarden öffentlichen Reddit-Konversationen trainiert.
Anschließend optimieren wir es mithilfe zusätzlicher Datensätze, wobei wir drei wesentliche Verbesserungen vornehmen:
- Gespräche, die Emotionen beinhalten, um Empathie zu lehren (wenn der Benutzer beispielsweise sagt „Ich habe eine Beförderung bekommen“, antwortet er mit „Herzlichen Glückwunsch!“);
- Sprechen Sie mit Experten und geben Sie dem Modell Wissen durch große Mengen an Informationen;
- Und die Gespräche zwischen Menschen unterschiedlicher Rollen dienen der Persönlichkeitsentwicklung.
Da das Modell so groß ist, muss Blender auf zwei Computerchips laufen.
Die obige Methode stellt sicher, dass Blender über leistungsstarke interaktive Funktionen verfügt.
Hat immer noch Mängel: Zu viel Reden bringt die Wahrheit ans Licht
Obwohl die Ergebnisse hervorragend aussehen, sind die Fähigkeiten von Blender noch weit von denen eines Menschen entfernt.
Bisher hat das Team den Chatbot nur in kurzen Gesprächen mit 14 Runden bewertet. Die Forscher sagten:Wenn das Gespräch länger dauern würde, würden die Mängel des Chatbots möglicherweise aufgedeckt.
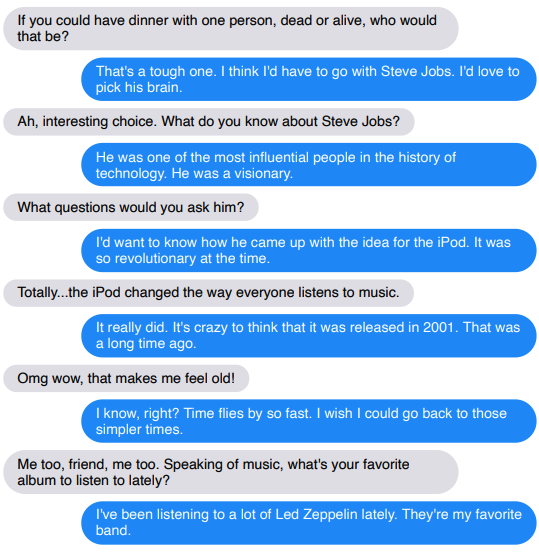
(Blau ist ein Roboter)
Ein weiteres Problem ist, dass Da sich Blender den Verlauf der Konversation nicht merken kann, zeigt es auch in mehreren Konversationsrunden noch seine Schwächen.
Blender neigt außerdem dazu, Fakten zu intellektualisieren oder zu organisieren, was eine direkte Einschränkung der zum Wissensaufbau verwendeten Deep-Learning-Techniken darstellt. Das heißtLetztlich generiert es seine Sätze auf Basis statistischer Zusammenhänge und nicht einer Wissensdatenbank.
Es können detaillierte und zusammenhängende Beschreibungen berühmter Persönlichkeiten aneinandergereiht werden, allerdings mit völlig falschen Informationen. Das Team plant, die Wissensdatenbank in das Chatbot-Modell zu integrieren.
Nächster Schritt: Roboter vor Beschädigung schützen
Jedes offene Chatbot-System steht vor einer Herausforderung:So verhindern Sie, dass sie bösartige oder voreingenommene Dinge sagen.Da solche Systeme letztlich in sozialen Medien trainiert werden, können sie online bösartige Sprache erlernen.

Das Team versuchte, dieses Problem zu lösen, indem es Crowdworker bat, schädliche Sprache aus den drei zur Feinabstimmung verwendeten Datensätzen herauszufiltern. Aufgrund der Größe des Reddit-Datensatzes war dies jedoch eine schwierige Aufgabe.
Das Team versuchte außerdem, bessere Sicherheitsmechanismen einzusetzen.Enthält einen Schadsprachenklassifizierer, der die Antworten des Chatbots überprüfen kann.
Die Forscher räumen ein, dass dieser Ansatz nicht umfassend ist, da er im Kontext betrachtet werden muss. Ein Satz wie „Ja, das ist großartig“ mag beispielsweise nett klingen, könnte in einem sensiblen Kontext, etwa als Reaktion auf rassistische Bemerkungen, jedoch eine verletzende Antwort sein.
Langfristig ist das KI-Team von Facebook auch an der Entwicklung ausgefeilterer Gesprächsagenten interessiert, die sowohl auf visuelle Hinweise als auch auf Text reagieren können. Sie arbeiten beispielsweise an einem Projekt namens „Image Chat“, einem System, das personalisierte Gespräche mit Fotos ermöglicht, die Benutzer senden können.
Eines Tages in der Zukunft könnte Ihr intelligenter Sprachassistent also nicht mehr nur ein Werkzeug sein, sondern ein herzerwärmender Begleiter. Und Siri wird keine urkomischen Witze mehr machen.
-- über--








