Command Palette
Search for a command to run...
PyTorch 1.5 Veröffentlicht, TorchServe in Zusammenarbeit Mit AWS

Vor Kurzem hat PyTorch ein Update auf Version 1.5 veröffentlicht. Als immer beliebter werdendes Framework für maschinelles Lernen brachte PyTorch dieses Mal auch wichtige Funktionsverbesserungen mit sich. Darüber hinaus haben Facebook und AWS zusammengearbeitet, um zwei wichtige PyTorch-Bibliotheken zu starten.
Da PyTorch zunehmend in Produktionsumgebungen eingesetzt wird, ist es für PyTorch zu einer der obersten Prioritäten geworden, der Community bessere Tools und Plattformen zur effizienten Skalierung von Trainings und Bereitstellung von Modellen bereitzustellen.
Vor Kurzem wurde PyTorch 1.5 veröffentlicht.Die Hauptbibliotheken Torchvision, Torchtext und Torchaudio wurden aktualisiert und Funktionen wie die Konvertierung von Modellen von der Python-API zur C++-API wurden eingeführt.

außerdem,Facebook hat außerdem mit Amazon zusammengearbeitet, um zwei wichtige Tools auf den Markt zu bringen: das Model-Serving-Framework TorchServe und den Kubernetes-Controller TorchElastic.
TorchServe zielt darauf ab, einen sauberen, kompatiblen Pfad in Industriequalität für die groß angelegte Bereitstellung der PyTorch-Modellinferenz bereitzustellen.
Mit dem TorchElastic Kubernetes-Controller können Entwickler mithilfe von Kubernetes-Clustern schnell fehlertolerante verteilte Trainingsjobs in PyTorch erstellen.
Dies scheint ein Versuch von Facebook und Amazon zu sein, TensorFlow im Rahmen groß angelegter Performance-KI-Modelle den Krieg zu erklären.
TorchServe: für Inferenzaufgaben
Die Bereitstellung von Machine-Learning-Modellen für Inferenzen im großen Maßstab ist nicht einfach. Entwickler müssen Modellartefakte sammeln und verpacken, einen sicheren Serving-Stack erstellen, Softwarebibliotheken für die Vorhersage installieren und konfigurieren, APIs und Endpunkte erstellen und verwenden, Protokolle und Metriken für die Überwachung generieren und mehrere Modellversionen auf möglicherweise mehreren Servern verwalten.
Jede dieser Aufgaben nimmt viel Zeit in Anspruch und kann die Modellbereitstellung um Wochen oder sogar Monate verzögern. Darüber hinaus ist die Optimierung der Dienste für Online-Anwendungen mit geringer Latenz ein Muss.
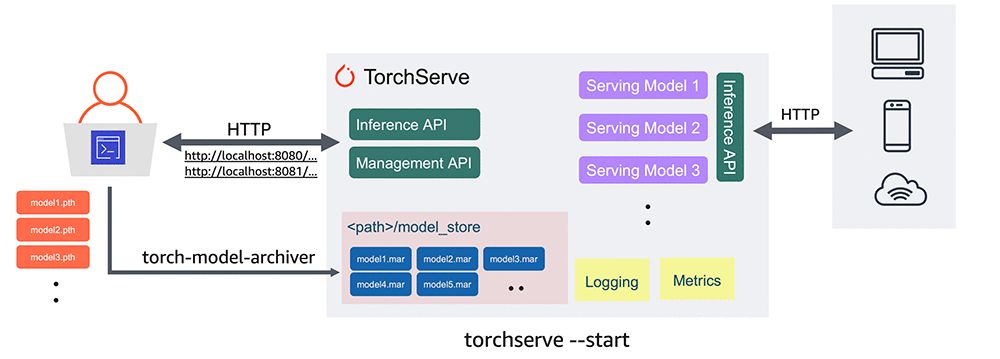
Bisher fehlte Entwicklern, die PyTorch verwendeten, eine offiziell unterstützte Methode zum Bereitstellen von PyTorch-Modellen. Die Veröffentlichung des Produktionsmodell-Service-Frameworks TorchServe wird diese Situation ändern und es einfacher machen, Modelle in die Produktion zu bringen.
Im folgenden Beispiel zeigen wir, wie Sie ein trainiertes Modell aus Torchvision extrahieren und mit TorchServe bereitstellen.
#Download a trained PyTorch modelwget https://download.pytorch.org/models/densenet161-8d451a50.pth#Package model for TorchServe and create model archive .mar filetorch-model-archiver \--model-name densenet161 \--version 1.0 \--model-file examples/image_classifier/densenet_161/model.py \--serialized-file densenet161–8d451a50.pth \--extra-files examples/image_classifier/index_to_name.json \--handler image_classifiermkdir model_storemv densenet161.mar model_store/#Start TorchServe model server and register DenseNet161 modeltorchserve — start — model-store model_store — models densenet161=densenet161.mar
Eine Betaversion von TorchServe ist jetzt verfügbar.Zu den Features gehören:
- Native API: Unterstützt die Inferenz-API für Vorhersagen und die Verwaltungs-API für die Verwaltung von Modellservern.
- Sichere Bereitstellung: Beinhaltet HTTPS-Unterstützung für sichere Bereitstellungen.
- Leistungsstarke Modellverwaltungsfunktionen: Ermöglicht die vollständige Konfiguration von Modellen, Versionen und einzelnen Workern über die Befehlszeilenschnittstelle, Konfigurationsdateien oder die Runtime-API.
- Modellarchiv: Bietet Tools zum Ausführen der „Modellarchivierung“, einem Prozess zum Verpacken eines Modells, von Parametern und unterstützenden Dateien in einem einzigen dauerhaften Artefakt. Mithilfe einer einfachen Befehlszeilenschnittstelle können Sie eine einzelne „.mar“-Datei verpacken und exportieren, die alles enthält, was Sie zum Bereitstellen eines PyTorch-Modells benötigen. Die .mar-Datei kann weitergegeben und wiederverwendet werden.
- Integrierte Modellhandler: Unterstützt Modellhandler, die die gängigsten Anwendungsfälle abdecken, wie z. B. Bildklassifizierung, Objekterkennung, Textklassifizierung und Bildsegmentierung. TorchServe unterstützt auch benutzerdefinierte Handler.
- Protokollierung und Metriken: Unterstützt robuste Protokollierung und Echtzeitmetriken zur Überwachung von Inferenzdiensten und Endpunkten, Leistung, Ressourcennutzung und Fehlern. Es ist auch möglich, benutzerdefinierte Protokolle zu generieren und benutzerdefinierte Metriken zu definieren.
- Modellverwaltung: Unterstützt die gleichzeitige Verwaltung mehrerer Modelle oder mehrerer Versionen desselben Modells. Mithilfe der Modellversionierung können Sie zu einer früheren Version zurückkehren oder den Datenverkehr für A/B-Tests an andere Versionen weiterleiten.
- Vorgefertigte Bilder: Sobald es fertig ist, können Sie das Dockerfile und das Docker-Image von T orchServe in CPU-basierten und NVIDIA GPU-basierten Umgebungen bereitstellen. Die neuesten Dockerfiles und Images finden Sie hier.
Installationsanweisungen, Tutorials und Dokumentation sind auch unter pytorch.org/serve verfügbar.
TorchElastic: Integrierter K8S-Controller
Da aktuelle Trainingsmodelle für maschinelles Lernen, wie beispielsweise RoBERTa und TuringNLG, immer größer werden, wird die Notwendigkeit, sie auf verteilte Cluster zu skalieren, immer wichtiger. Um diesen Bedarf zu decken, werden häufig präemptive Instanzen (wie Amazon EC2 Spot Instances) verwendet.
Aber diese unterbrechbaren Instanzen selbst sind unvorhersehbar, und hier kommt das zweite Tool, TorchElastic, ins Spiel.
Die Integration von Kubernetes und TorchElastic ermöglicht es PyTorch-Entwicklern, Machine-Learning-Modelle auf einem Cluster von Rechenknoten zu trainieren.Diese Knoten können dynamisch geändert werden, ohne den Modelltrainingsprozess zu unterbrechen.
Selbst wenn ein Knoten ausfällt, können Sie dank der integrierten Fehlertoleranz von TorchElastic das Training auf Knotenebene unterbrechen und fortsetzen, sobald der Knoten wieder fehlerfrei ist.
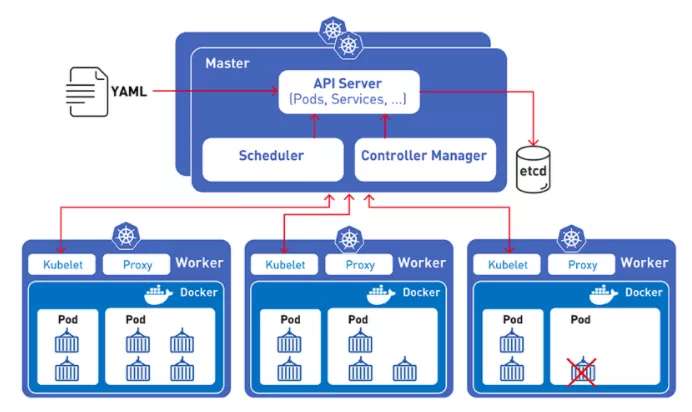
Darüber hinaus können Sie mithilfe des Kubernetes-Controllers mit TorchElastic die kritische Aufgabe des verteilten Trainings auf einem Cluster mit ersetzten Knoten ausführen, falls Probleme mit der Hardware oder der Knotenwiederverwendung auftreten.
Trainingsjobs können mit einem Teil der angeforderten Ressourcen gestartet und dynamisch skaliert werden, wenn Ressourcen verfügbar werden, ohne dass ein Stoppen oder Neustarten erforderlich ist.
Um diese Funktionen zu nutzen, geben Benutzer einfach Trainingsparameter in einer einfachen Jobdefinition an und das Kubernetes-TorchElastic-Paket verwaltet den Lebenszyklus des Jobs.
Hier ist ein einfaches Beispiel einer TorchElastic-Konfiguration für einen Imagenet-Trainingsjob:
apiVersion: elastic.pytorch.org/v1alpha1kind: ElasticJobmetadata:name: imagenetnamespace: elastic-jobspec:rdzvEndpoint: $ETCD_SERVER_ENDPOINTminReplicas: 1maxReplicas: 2replicaSpecs:Worker:replicas: 2restartPolicy: ExitCodetemplate:apiVersion: v1kind: Podspec:containers:- name: elasticjob-workerimage: torchelastic/examples:0.2.0rc1imagePullPolicy: Alwaysargs:- "--nproc_per_node=1"- "/workspace/examples/imagenet/main.py"- "--arch=resnet18"- "--epochs=20"- "--batch-size=32"
Microsoft und Google, geraten Sie in Panik?
Die Zusammenarbeit zwischen den beiden Unternehmen bei der Einführung der neuen PyTorch-Bibliothek hat möglicherweise eine tiefere Bedeutung, da die Routine „nicht mit dir spielen“ nicht das erste Mal in der Geschichte der Framework-Modellentwicklung auftritt.
Im Dezember 2017 gaben AWS, Facebook und Microsoft bekannt, dass sie ONNX gemeinsam für Produktionsumgebungen entwickeln würden.Damit soll dem Monopol von Googles TensorFlow auf die industrielle Nutzung entgegengewirkt werden.
In der Folgezeit haben gängige Deep-Learning-Frameworks wie Apache MXNet, Caffe2 und PyTorch alle einen unterschiedlich starken Support für ONNX implementiert, was die Migration von Algorithmen und Modellen zwischen verschiedenen Frameworks erleichtert.

Allerdings hat die Vision von ONNX, Wissenschaft und Industrie zu vernetzen, die ursprünglichen Erwartungen nicht erfüllt. Jedes Framework verwendet immer noch sein eigenes Servicesystem, und im Grunde sind nur MXNet und PyTorch in ONNX eingedrungen.
Heute,PyTorch hat sein eigenes Servicesystem gestartet und ONNX hat fast seinen Daseinssinn verloren (MXNet sagte, es sei ratlos).
Andererseits wird PyTorch ständig erweitert und aktualisiert, und die Kompatibilität und Benutzerfreundlichkeit des Frameworks verbessern sich.Es nähert sich seinem stärksten Rivalen TensorFlow und übertrifft ihn sogar.
Obwohl Google über eigene Cloud-Dienste und Frameworks verfügt, wird es für Google durch die Kombination der Cloud-Ressourcen von AWS und des Framework-Systems von Facebook schwierig, mit dieser leistungsstarken Kombination umzugehen.
Microsoft wurde von zwei Mitgliedern des ehemaligen ONNX-Trios aus dem Gruppenchat geworfen. Was sind die Pläne von Microsoft für den nächsten Schritt?
-- über--








