Command Palette
Search for a command to run...
Diese Gruppe Von Ingenieuren Hat in Ihrer Freizeit Das Chinesische NLP Einen Großen Schritt Nach Vorne Gebracht

Jemand hat gesagt, wer NLP (Natural Language Processing) studiert hat, wüsste, wie schwierig chinesisches NLP sei.
Obwohl beide zum NLP gehören, gibt es zwischen Englisch und Chinesisch aufgrund unterschiedlicher Sprachgewohnheiten große Unterschiede in der Analyse und Verarbeitung, und auch die Schwierigkeiten und Herausforderungen sind unterschiedlich.

Darüber hinaus sind einige der derzeit beliebten Modelle hauptsächlich für Englisch entwickelt. In Verbindung mit den einzigartigen Verwendungsgewohnheiten des Chinesischen sind viele Aufgaben (wie etwa die Wortsegmentierung) sehr schwierig, was zu sehr langsamen Fortschritten im Bereich des chinesischen NLP führt.
Dieses Problem könnte sich jedoch bald ändern, da seit dem letzten Jahr viele hervorragende Open-Source-Projekte entstanden sind, die die Entwicklung des chinesischen NLP-Bereichs erheblich gefördert haben.
Modell: Chinesischer vortrainierter ALBERT
Im Jahr 2018 hat Google das Sprachmodell BERT (Bidirectional Encoder Representations from Transformers) eingeführt. Aufgrund seiner extrem starken Leistung eroberte es gleich nach seiner Veröffentlichung die Charts vieler NLP-Standards und wurde sofort als Meisterwerk gefeiert.
Ein Nachteil von BERT ist jedoch, dass es zu groß ist. BERT-large hat 300 Millionen Parameter, was das Training sehr schwierig macht. Im Jahr 2019 brachte Google AI das leichtgewichtige ALBERT (A Little BERT) auf den Markt, das 18-mal kleinere Parameter als das BERT-Modell hat, aber eine bessere Leistung bietet.
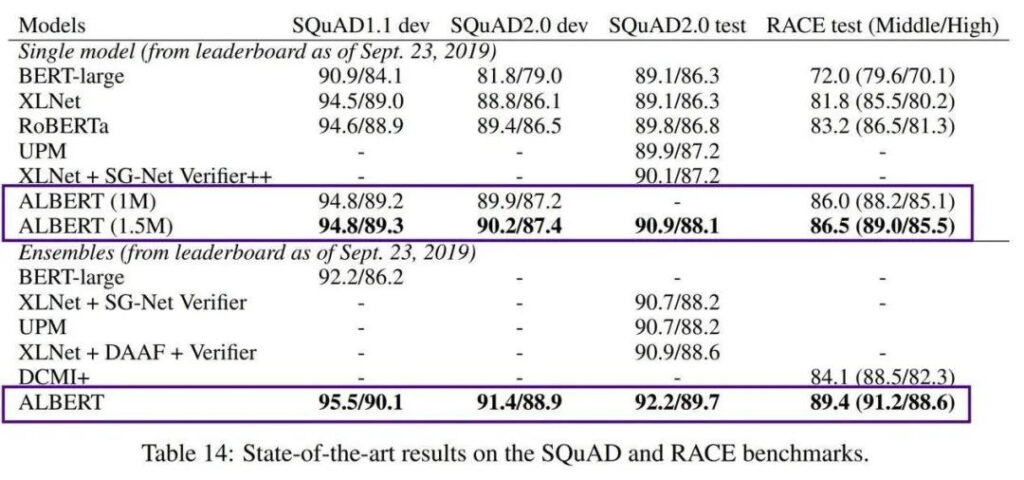
Obwohl es das Problem der hohen Trainingskosten und der großen Anzahl von Parametern vorab trainierter Modelle löst, ist AlBERT immer noch nur auf englische Kontexte ausgerichtet, was Ingenieuren, die sich auf die chinesische Entwicklung konzentrieren, ein wenig hilflos erscheinen lässt.
Um dieses Modell im chinesischen Kontext nutzbar zu machen und mehr Entwicklern zugutezukommen, hat das Team des Dateningenieurs Xu Liang im Oktober 2019 das erste vortrainierte chinesische ALBERT-Modell veröffentlicht.
Projektgalerie
https://github.com/brightmart/albert_zh
Dieses vortrainierte chinesische ALBERT-Modell (bezeichnet als albert_zh) wird anhand eines riesigen chinesischen Korpus trainiert. Die Schulungsinhalte stammen aus mehreren Enzyklopädien, Nachrichten und interaktiven Communities, darunter 30 GB chinesisches Korpus und mehr als 100 Milliarden chinesische Schriftzeichen.
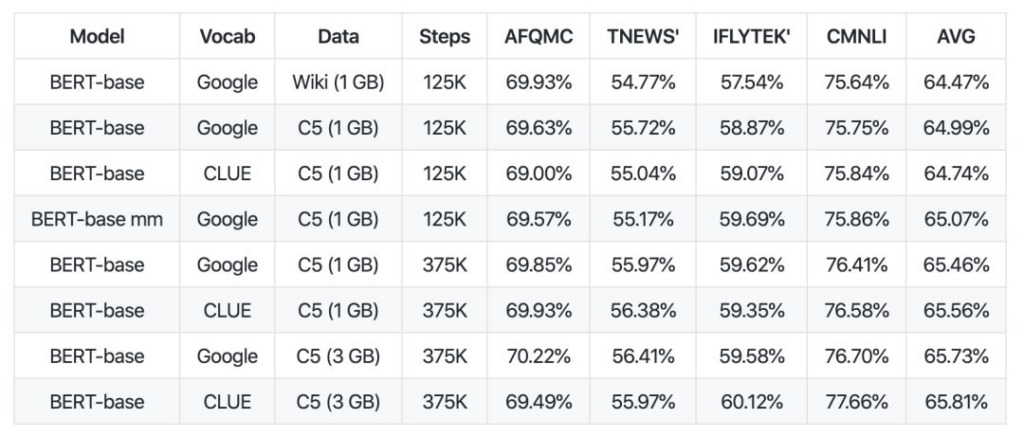
Aus dem Datenvergleich geht hervor, dass die Sequenzlänge vor dem Training von albert_zh auf 512 eingestellt ist, die Batchgröße 4096 beträgt und das Training 350 Millionen Trainingsdaten generiert. Ein weiteres leistungsstarkes Vortrainingsmodell, roberta_zh, generiert 250 Millionen Trainingsdaten mit einer Sequenzlänge von 256.
Das Vortraining von albert_zh generiert mehr Trainingsdaten und verwendet längere Sequenzen. Es wird erwartet, dass albert_zh eine bessere Leistung als roberta_zh hat und längere Texte besser verarbeiten kann.
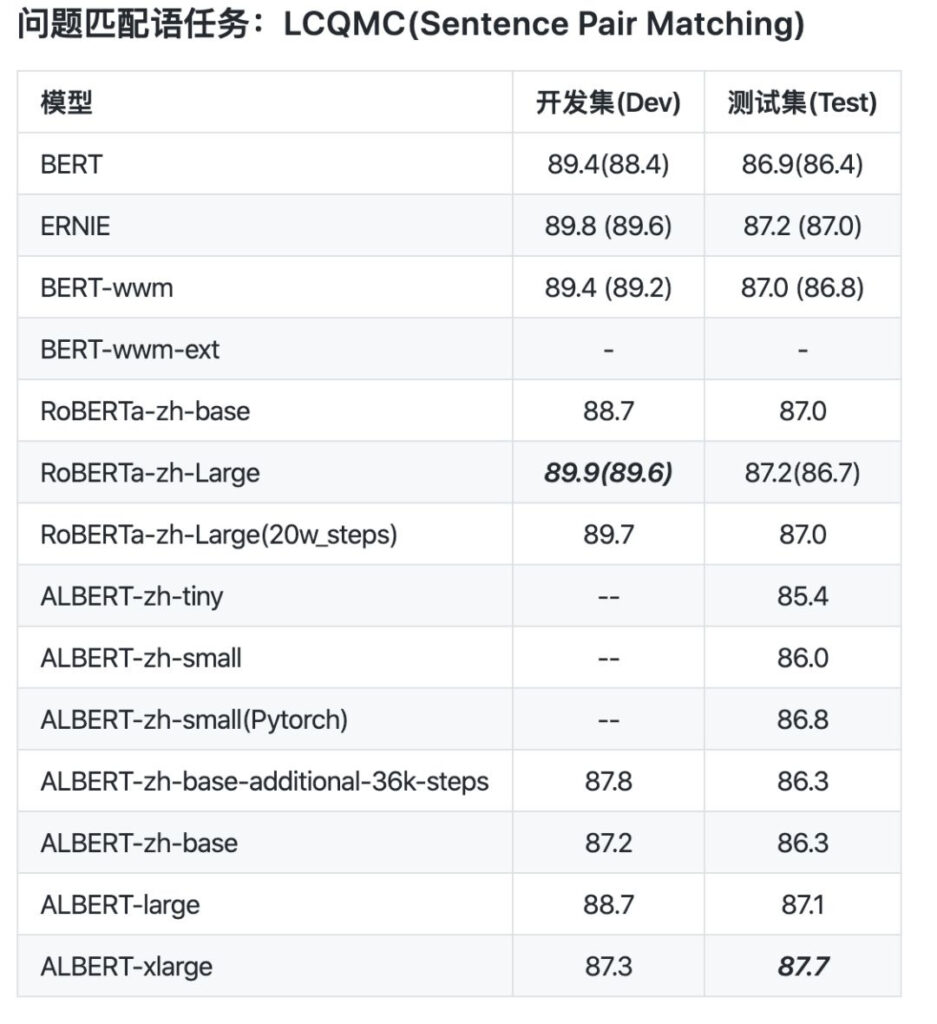
Darüber hinaus hat albert_zh eine Reihe von ALBERT-Modellen mit unterschiedlichen Parametergrößen trainiert, von winzig bis extrem groß, was die Popularität von ALBERT im Bereich der chinesischen NLP erheblich gefördert hat.
Es ist erwähnenswert, dass Google AI im Januar 2020 ALBERT V2 veröffentlichte und dann langsam die chinesische Google-Version von ALBERT auf den Markt brachte.
Benchmark: ChineseGLUE für Chinese GLUE
Wenn wir erst einmal Modelle haben, wie beurteilen wir dann, ob sie gut oder schlecht sind? Voraussetzung hierfür ist ein ausreichend guter Testbenchmark. Außerdem wurde im letzten Jahr der Benchmark ChineseGLUE für chinesisches NLP als Open Source veröffentlicht.
ChineseGLUE basiert auf dem branchenweit anerkannten Test-Benchmark GLUE, einer Sammlung von neun Aufgaben zum Verständnis der englischen Sprache. Ihr Ziel ist es, die Erforschung allgemeiner und robuster Systeme zum Verständnis natürlicher Sprache zu fördern.
Zuvor gab es keine entsprechende chinesische Version von GLUE, und einige vorab trainierte Modelle konnten in öffentlichen Tests zu verschiedenen Aufgaben nicht beurteilt werden, was zu einer Fehlausrichtung bei der Entwicklung und Anwendung von NLP im chinesischen Bereich und sogar zu einer Verzögerung bei der technologischen Anwendung führte.
Angesichts dieser Situation haben Dr. Zhenzhong Lan, der Erstautor von AlBERT, Xu Liang, der Entwickler von ablbert_zh, und mehr als 20 weitere Ingenieure gemeinsam einen Benchmark für chinesisches NLP herausgebracht: ChineseGLUE.
Projektgalerie
https://github.com/chineseGLUE/chineseGLUE
Durch die Einführung von ChineseGLUE konnte Chinesisch als Indikator für die Bewertung neuer Modelle einbezogen werden, wodurch ein vollständiges Bewertungssystem zum Testen vortrainierter chinesischer Modelle entstand.
Dieser leistungsstarke Test-Benchmark umfasst die folgenden Aspekte:
1) Ein chinesischer Aufgaben-Benchmark, der aus mehreren Sätzen oder Satzpaaren besteht und mehrere Sprachaufgaben auf verschiedenen Niveaus abdeckt.
2) Bereitstellung einer Leistungsbewertungsrangliste, die regelmäßig aktualisiert wird, um eine Grundlage für die Modellauswahl zu bieten.
3) Eine Sammlung von Benchmark-Modellen, einschließlich des Startcodes, vortrainierter Modelle und Benchmarks für ChineseGLUE-Aufgaben, die in Frameworks wie TensorFlow, PyTorch und Keras verfügbar sind.
4) Verfügen Sie über ein riesiges Originalkorpus für die Vorschulung oder Sprachmodellierungsforschung, das etwa 10G groß ist (2019), und soll bis Ende 2020 auf ein ausreichendes Originalkorpus (z. B. 100G) erweitert werden.
Die Einführung und kontinuierliche Verbesserung von ChineseGLUE dürfte zur Geburt leistungsfähigerer chinesischer NLP-Modelle führen, so wie GLUE die Entstehung von BERT miterlebt hat.
Ende Dezember 2019 wurde das Projekt in ein umfassenderes und technisch besser unterstütztes Projekt migriert: CLUEbenchmark/CLUE.
Projektgalerie
https://github.com/CLUEbenchmark/CLUE
Daten: Der umfassendste Datensatz und das größte Korpus der Geschichte
Neben vortrainierten Modellen und Test-Benchmarks sind Datenressourcen wie Datensätze und Korpora ein weiteres wichtiges Bindeglied.
Dies führte zu einer umfassenderen Organisation namens CLUE, der Abkürzung für das chinesische Wort GLUE. Es handelt sich um eine Open-Source-Organisation, die Bewertungsmaßstäbe für das Verständnis der chinesischen Sprache bereitstellt. Zu ihren Schwerpunkten gehören: Aufgaben und Datensätze, Benchmarks, vortrainierte chinesische Modelle, Korpora und Ranking-Veröffentlichungen.
Vor einiger Zeit hat CLUE den größten und umfassendsten chinesischen NLP-Datensatz veröffentlicht, der 142 Datensätze in 10 Kategorien umfasst: CLUEDatasetSearch.

Projektgalerie
https://github.com/CLUEbenchmark/CLUEDatasetSearch
Sein Inhalt umfasst alle wichtigen Richtungen der aktuellen Forschung wie NER, Qualitätssicherung, Stimmungsanalyse, Textklassifizierung, Textzuweisung, Textzusammenfassung, maschinelle Übersetzung, Wissensgraphen, Korpora und Leseverständnis.
Geben Sie einfach Schlüsselwörter oder Informationen wie verwandte Felder auf der Website-Seite ein und Sie können nach entsprechenden Ressourcen suchen. Jeder Datensatz enthält Informationen wie Name, Aktualisierungszeit, Anbieter, Beschreibung, Schlüsselwörter, Kategorie und Papieradresse.
Vor Kurzem hat die CLUE-Organisation 100 GB chinesisches Korpus und eine Sammlung hochwertiger chinesischer vortrainierter Modelle geöffnet und ein Papier bei arViv eingereicht.

In Bezug auf das Korpus hat CLUE CLUECorpus2020 als Open Source bereitgestellt: Groß angelegtes Vortrainingskorpus für Chinesen, 100 G chinesisches Vortrainingskorpus.
Diese Inhalte werden nach der Korpusbereinigung des chinesischen Teils des Common Crawl-Datensatzes erhalten.
Sie können direkt für Vortrainings-, Sprachmodell- oder Sprachgenerierungsaufgaben verwendet werden oder kleine Vokabulare speziell für chinesische NLP-Aufgaben veröffentlichen.
Projektgalerie
https://github.com/CLUEbenchmark/CLUECorpus2020
In Bezug auf die Modellsammlung wurde CLUEPretrainedModels veröffentlicht: eine Sammlung hochwertiger chinesischer vortrainierter Modelle – die fortschrittlichsten großen Modelle, die schnellsten kleinen Modelle und ähnlichkeitsspezifische Modelle.
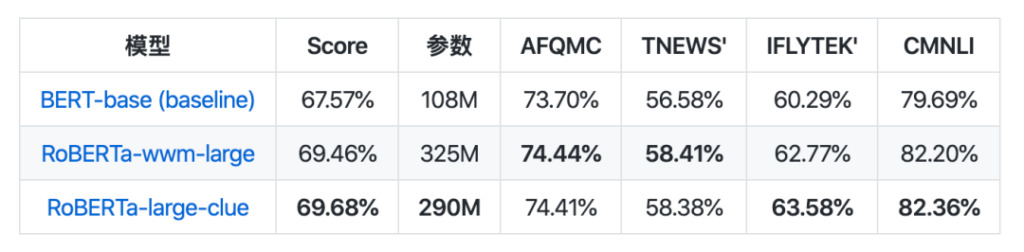
Das große Modell erzielt die gleichen Ergebnisse wie das derzeit beste chinesische NLP-Modell und übertrifft bei einigen Aufgaben sogar die Leistung. Das kleine Modell ist etwa 8-mal schneller als Bert-Base. Das semantische Ähnlichkeitsmodell wird zur Verarbeitung semantischer Ähnlichkeits- oder Satzpaarprobleme verwendet und ist wahrscheinlich besser als die direkte Verwendung eines vortrainierten Modells.
Projektgalerie
https://github.com/CLUEbenchmark/CLUEPretrainedModels
Die Freigabe dieser Ressourcen ist in gewissem Maße wie Treibstoff, der den Entwicklungsprozess antreibt, und ausreichende Ressourcen könnten den Weg für eine schnelle Entwicklung der chinesischen NLP-Branche ebnen.
Sie machen chinesisches NLP einfach
Aus linguistischer Sicht sind Chinesisch und Englisch die beiden Sprachen mit der größten Anzahl an Benutzern und dem größten Einfluss auf der Welt. Aufgrund ihrer unterschiedlichen Sprachmerkmale stehen sie jedoch auch in der NLP-Forschung vor unterschiedlichen Problemen.
Obwohl die Entwicklung der chinesischen NLP tatsächlich schwieriger ist und hinter der Forschung zur englischen Sprache zurückbleibt, die von Maschinen besser verstanden wird, ist es gerade den im Artikel erwähnten Ingenieuren zu verdanken, dass sie die Entwicklung der chinesischen NLP vorantreiben und ihre Ergebnisse weiterhin erforschen und teilen, dass diese Technologien besser iteriert werden können.
Vielen Dank für ihren Einsatz und ihre Beiträge zu so vielen hochwertigen Projekten! Gleichzeitig hoffen wir, dass mehr Menschen teilnehmen und gemeinsam die Entwicklung des chinesischen NLP vorantreiben können.
-- über--








