Command Palette
Search for a command to run...
MV-MATH-Annotationsdatensatz Für Mathematisches Denken
Datum
Größe
Organisation
Veröffentlichungs-URL
Paper-URL
Lizenz
MIT
Tags
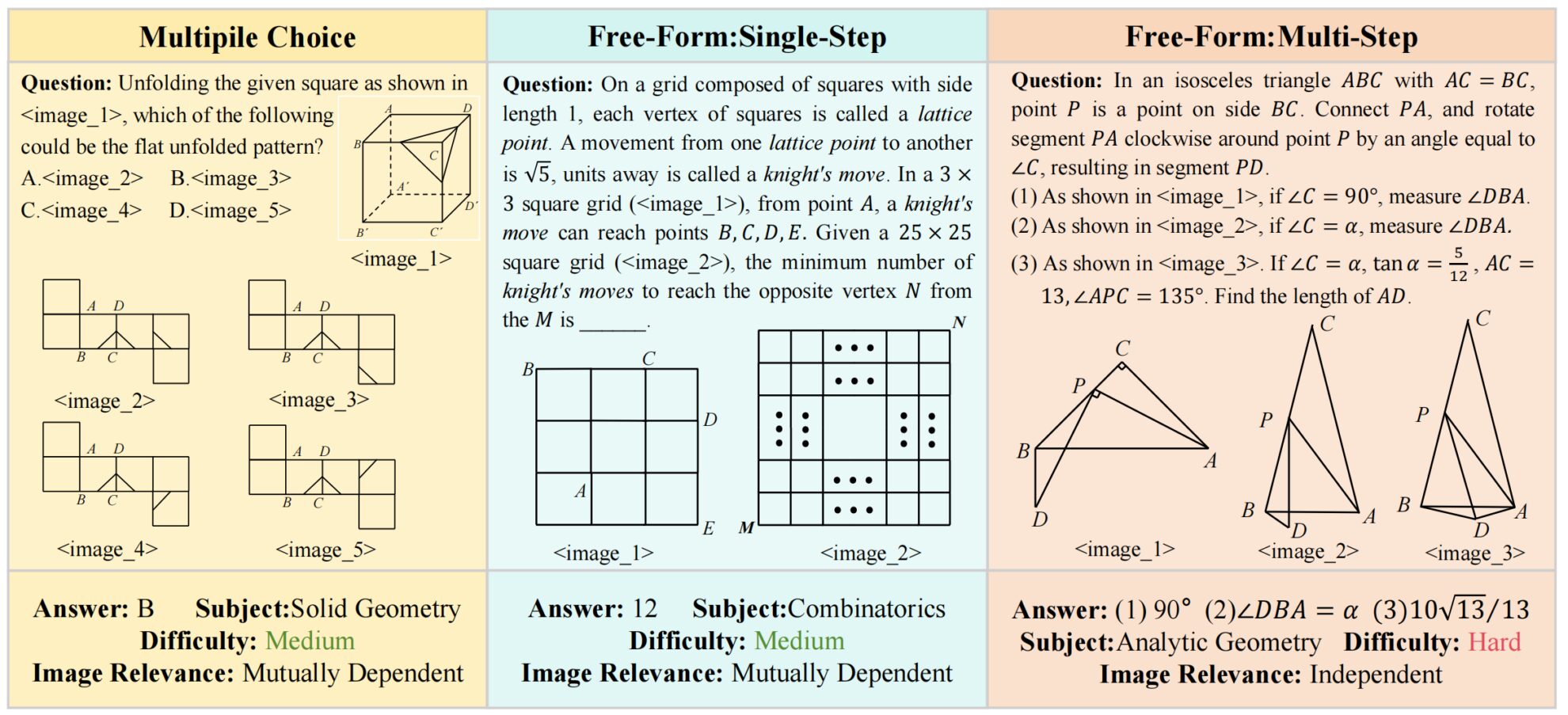
MV-MATH ist ein multimodaler Benchmark-Datensatz für mathematisches Denken, der 2025 vom Institute of Automation der Chinesischen Akademie der Wissenschaften vorgeschlagen wurde. Ziel ist eine umfassende Bewertung der mathematischen Denkfähigkeit multimodaler Large Language Models (MLLMs) in multivisuellen Szenen.MV-MATH: Bewertung multimodalen mathematischen Denkens in multivisuellen Kontexten", wurde von CVPR 2025 angenommen. Der MV-MATH-Datensatz enthält 2.009 hochwertige Mathematikaufgaben, die in drei Typen unterteilt sind: Multiple-Choice-Fragen, Lückentextfragen und mehrstufige Fragen. Der Datensatz enthält mehrere visuelle Szenen und jede Frage ist mit 2 bis 8 Bildern ausgestattet. Diese Bilder werden mit Text verflochten, um komplexe multivisuelle Szenen zu bilden, die mathematischen Problemen in der realen Welt näher kommen und die Denkfähigkeit des Modells zur Verarbeitung multivisueller Informationen effektiv bewerten können. Zweitens ist der Datensatz reich annotiert. Jede Probe wurde von mindestens zwei Kommentatoren kreuzvalidiert. Die Anmerkungen umfassen Fragen, Antworten, detaillierte Analysen und Bildrelevanz und liefern ausführliche Informationen zur Modellbewertung. Darüber hinaus deckt der Datensatz 11 Bereiche der Mathematik ab, von der Grundrechenart bis zur fortgeschrittenen Geometrie, darunter analytische Geometrie, Algebra, metrische Geometrie, Kombinatorik, Transformationsgeometrie, Logik, Stereometrie, Arithmetik, kombinatorische Geometrie, darstellende Geometrie und Statistik. Der Datensatz ist außerdem basierend auf der Länge der ausführlichen Antworten in drei Schwierigkeitsstufen unterteilt, wodurch die Argumentationsfähigkeit des Modells in verschiedenen mathematischen Bereichen umfassend bewertet werden kann. Es ist erwähnenswert, dass dieser Datensatz zum ersten Mal die Merkmalsbezeichnung der Bildkorrelation einführt und den Datensatz in zwei Teilmengen unterteilt: „Mutually Dependent Set“ (MD) und „Independent Set“ (ID). In der MD-Teilmenge sind Bilder miteinander verknüpft und das Verständnis eines Bildes erfordert den Bezug auf andere Bilder. Während in der ID-Teilmenge die Bilder unabhängig sind und einzeln interpretiert werden können. Es stammt nicht nur aus realen Szenarien des K-12-Bildungswesens und kann zur Entwicklung intelligenter Tutorsysteme verwendet werden, die Schülern dabei helfen, komplexe mathematische Probleme durch eine Kombination aus Grafiken und Text zu lösen, sondern bietet auch ein standardisiertes Bewertungstool für die multimodale Lernforschung, das Forschern dabei hilft, Leistungslücken in Modellen zum mathematischen Denken zu identifizieren und zu verbessern. Bei Tests gängiger multimodaler Großsprachenmodelle wie GPT-4o und QvQ lagen ihre Ergebnisse im MV-MATH-Datensatz jedoch bei 32,1 bzw. 29,3 und damit beide unter der Bestehensgrenze. Dies weist darauf hin, dass aktuelle multimodale Großmodelle bei multivisuellen mathematischen Denkaufgaben immer noch vor erheblichen Herausforderungen stehen.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.