Command Palette
Search for a command to run...
MMedC Großes Mehrsprachiges Medizinisches Korpus
Datum
Größe
Organisation
Veröffentlichungs-URL
Paper-URL
Lizenz
CC BY-NC-SA 3.0
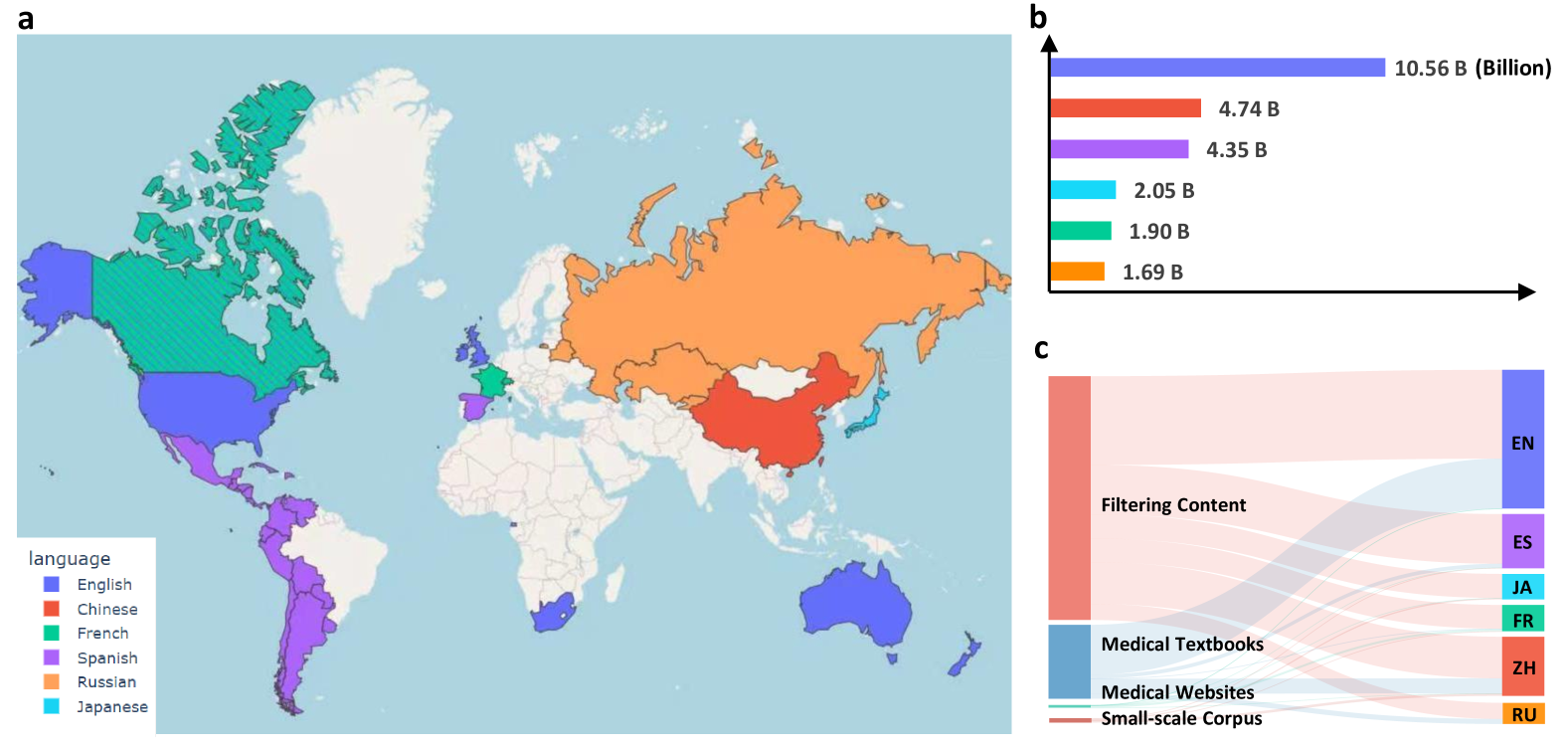
Das Massive Multilingual Medical Corpus (MMedC) ist ein mehrsprachiges medizinisches Korpus, das 2024 vom Smart Healthcare Team der School of Artificial Intelligence der Shanghai Jiao Tong University erstellt wurde. Es enthält ungefähr 25,5 Milliarden Token in sechs Hauptsprachen: Englisch, Chinesisch, Japanisch, Französisch, Russisch und Spanisch. Dieser Datensatz wurde erstellt, um die Entwicklung mehrsprachiger medizinischer Großsprachenmodelle voranzutreiben, die den größten Teil der Welt abdecken, und die Unterstützung für weitere Sprachen wird weiterhin aktualisiert und erweitert. Die relevanten Papierergebnisse sindAuf dem Weg zum Aufbau eines mehrsprachigen Sprachmodells für die Medizin“, veröffentlicht in Nature Communications. Die Datenquellen von MMedC umfassen hauptsächlich vier Aspekte: Erstens werden medizinbezogene Inhalte durch heuristische Algorithmen aus großen allgemeinen Textdatenbanken (wie CommonCrawl) herausgefiltert; zweitens wird Text aus medizinischen Lehrbüchern mithilfe optischer Zeichenerkennungstechnologie (OCR) extrahiert; drittens werden in vielen Ländern Daten von offiziell lizenzierten medizinischen Websites gecrawlt; Abschließend werden einige vorhandene medizinische Datensätze im kleinen Maßstab integriert. Um die Entwicklung mehrsprachiger Modelle im medizinischen Bereich zu bewerten, hat das Forschungsteam außerdem einen neuen mehrsprachigen Bewertungsstandard für Multiple-Choice-Fragen und -Antworten namens MMedBench entwickelt. Alle Fragen in MMedBench stammen direkt aus den Fragendatenbanken der medizinischen Untersuchungen verschiedener Länder und werden nicht einfach durch Übersetzungen erlangt. Dadurch wird eine diagnostische Verzerrung des Verständnisses vermieden, die durch Unterschiede in den Leitlinien der medizinischen Praxis in verschiedenen Ländern verursacht wird. Während des Bewertungsprozesses muss das Modell nicht nur die richtige Antwort auswählen, sondern auch eine vernünftige Erklärung liefern. Dadurch wird die Fähigkeit des Modells, komplexe medizinische Informationen zu verstehen und zu interpretieren und eine umfassendere Bewertung zu erreichen, weiter getestet. Das Forschungsteam hat außerdem das mehrsprachige medizinische Basismodell MMed-Llama 3 als Open Source veröffentlicht. Es zeigte in mehreren Benchmarks außergewöhnlich gute Ergebnisse, übertraf bestehende Open-Source-Modelle deutlich und eignet sich besonders für die individuelle Feinabstimmung im medizinischen Bereich. Alle Daten und Codes wurden als Open Source freigegeben, was die Zusammenarbeit und den Technologieaustausch innerhalb der globalen Forschungsgemeinschaft weiter fördert. Die Konstruktion und Open Source von MMedC bietet umfassende und qualitativ hochwertige Datenunterstützung für das Training und die Auswertung mehrsprachiger medizinischer Sprachmodelle, trägt zur Lösung der Probleme von Sprachbarrieren und der Globalisierung medizinischer Ressourcen bei und weist ein großes Anwendungspotenzial im medizinischen Bereich auf.
Zitat
@misc{qiu2024building,
title={Towards Building Multilingual Language Model for Medicine},
author={Pengcheng Qiu and Chaoyi Wu and Xiaoman Zhang and Weixiong Lin and Haicheng Wang and Ya Zhang and Yanfeng Wang and Weidi Xie},
year={2024},
eprint={2402.13963},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.