Command Palette
Search for a command to run...
OpenForensics-Datensatz Zur Gesichtsfälschungserkennung
Datum
Größe
Veröffentlichungs-URL
Paper-URL
Lizenz
CC BY 4.0
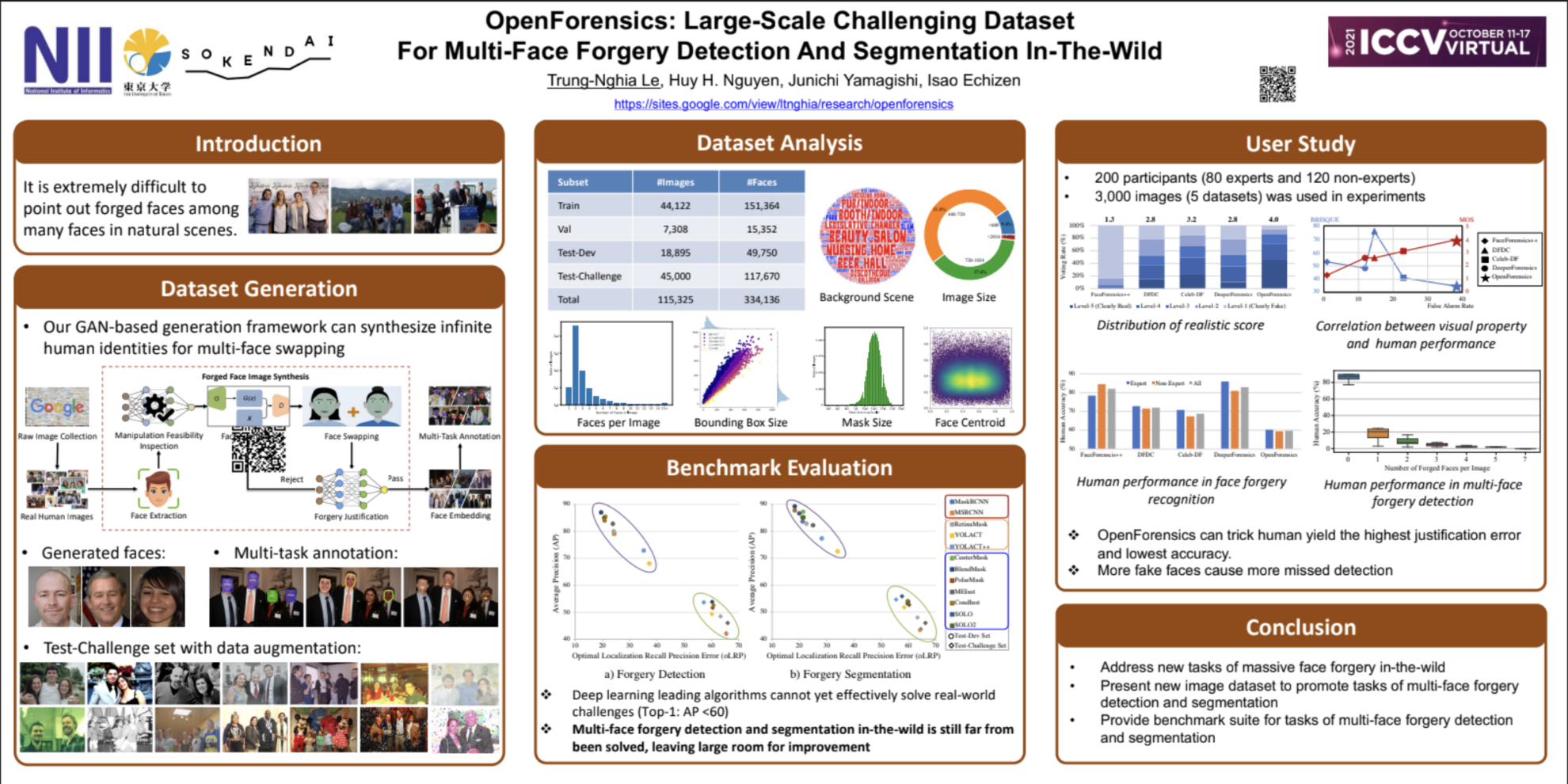
Der OpenForensics-Datensatz ist ein umfangreicher, anspruchsvoller Datensatz, der für vielschichtige Aufgaben zur Fälschungserkennung und -segmentierung entwickelt wurde. Es wurde 2021 von Forschern des National Institute of Informatics, SOKENDAI und der Universität Tokio veröffentlicht. Die entsprechenden Ergebnisse der Studie sind „OpenForensics: Anspruchsvoller, umfangreicher Datensatz zur Erkennung und Segmentierung von Fälschungen mehrerer Gesichter in der Praxis".
Der Datensatz besteht aus 115.000 Bildern aus der freien Wildbahn und 334.000 Gesichtern, alle mit umfangreichen Gesichtsanmerkungen, darunter Fälschungskategorien, Begrenzungsrahmen, Segmentierungsmasken, Fälschungsgrenzen und allgemeine Gesichtsmerkmale, und deckt verschiedene Hintergründe und mehrere Personen unterschiedlichen Alters, Geschlechts, unterschiedlicher Posen, Positionen und Gesichtsverdeckungen ab. Dieser Datensatz unterstützt nicht nur Aufgaben zur Erkennung und Segmentierung von Fälschungen mehrerer Gesichter, sondern auch allgemeine Aufgaben mit allgemeinen Gesichtern und bietet großes Potenzial für die Forschung zur Deepfake-Prävention und allgemeinen Erkennung menschlicher Gesichter.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.