Command Palette
Search for a command to run...
VEGA Scientific Paper Graphics Und Text Data Understanding Dataset
Datum
Größe
Organisation
Veröffentlichungs-URL
Paper-URL
Tags
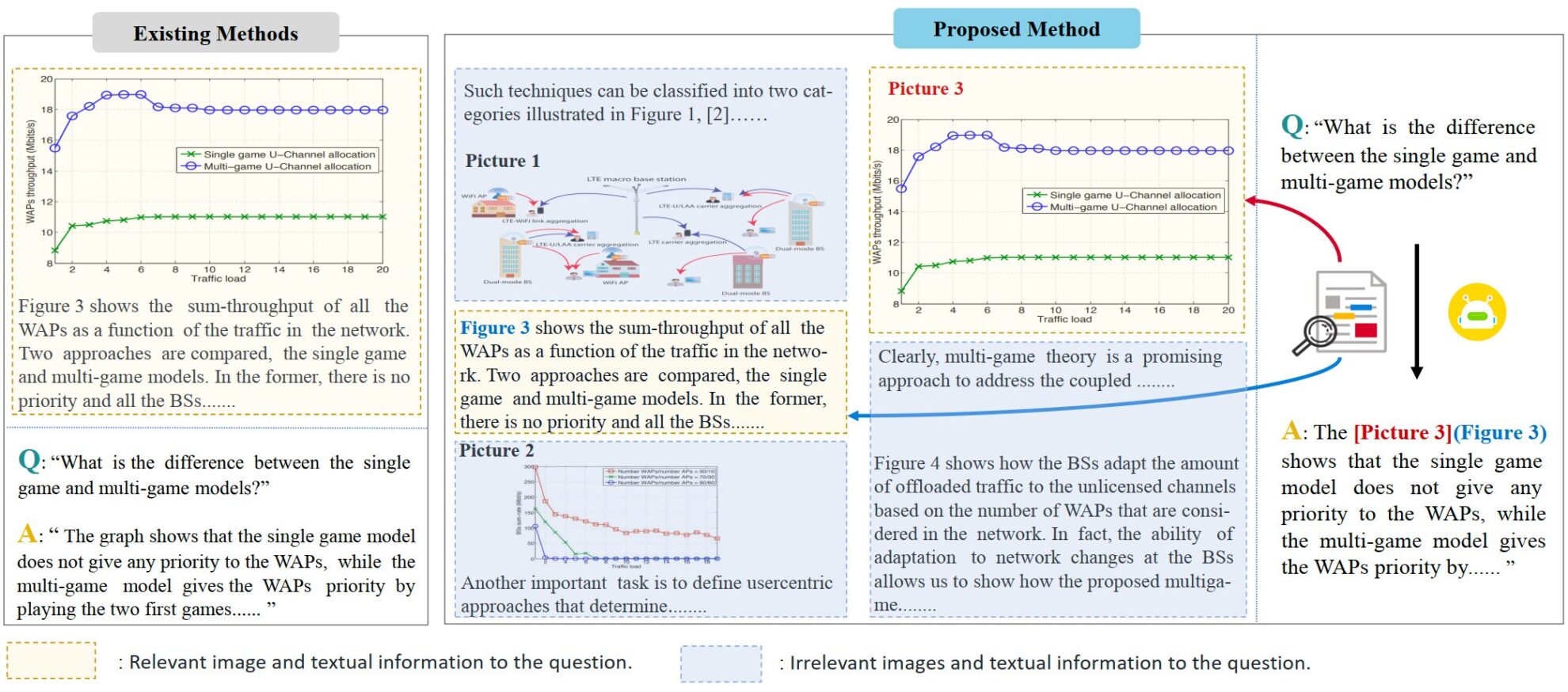
VEGA ist ein multimodaler Datensatz, der sich auf das Verständnis wissenschaftlicher Arbeiten konzentriert. Es wurde 2024 von Ji Rongrongs Team an der Xiamen-Universität vorgeschlagen und soll die Leistung von Modellen bei der Verarbeitung von Eingaben mit komplexen Text- und Bildinformationen bewerten und verbessern. Das entsprechende Papier ist „VEGA: Lernen des verschachtelten Bild-Text-Verständnisses in großen Vision-Language-ModellenDer Datensatz enthält Text- und Bilddaten aus über 50.000 wissenschaftlichen Arbeiten und wurde speziell für die Aufgabe des Interleaved Image-Text Comprehension (IITC) erstellt. Der Erstellungsprozess des VEGA-Datensatzes umfasst drei Schritte: Fragenscreening, Kontextkonstruktion und Antwortmodifikation. Ziel ist es, längere und komplexere interlaced Text- und Bildinhalte als Eingabe bereitzustellen, und das Modell muss bei der Beantwortung die referenzierten Bilder angeben. VEGA basiert auf dem SciGraphQA-Datensatz, einem Datensatz für Aufgaben zum Verständnis von Papierbildern, der 295.000 Frage-Antwort-Paare enthält. Darauf aufbauend führte das Forschungsteam drei Schritte durch: Fragenscreening, Kontextkonstruktion und Antwortmodifikation, um den VEGA-Datensatz zu erhalten. Es enthält 593.000 Trainingsdaten in Papierform und 2.326 Testdaten von 2 verschiedenen Aufgaben. Ziel ist es, längere und komplexere verschachtelte Text-Bild-Inhalte als Eingabe bereitzustellen und erfordert, dass das Modell bei der Beantwortung die referenzierten Bilder angibt.
- Fragenscreening: Bei manchen Fragen im Originaldatensatz fehlen eindeutige Bildbezüge, was zu Verwirrung führt, wenn die Eingabeinformationen auf mehrere Bilder erweitert werden.
- Kontextkonstruktion: Die Frage und Antwort im Originaldatensatz beziehen sich nur auf ein Bild und liefern nur wenige Kontextinformationen. Um die Menge an Text und Bildern zu erweitern, lud das Forschungsteam die Quelldateien relevanter Dokumente auf Arxiv herunter und erstellte Daten in zwei Längen: 4.000 Token und 8.000 Token. Jedes Frage-Antwort-Paar enthält bis zu 8 Bilder.
- Antwortänderung: Der Autor hat die Antworten im Originaldatensatz geändert und die bei der Beantwortung referenzierten Bilder angegeben, um die Anforderungen der IITC-Aufgabe zu erfüllen.
Zitat
@misc{zhou2024vegalearninginterleavedimagetext, title={VEGA: Lernen von verschachtelter Bild-Text-Verständnis in großen Vision-Sprach-Modellen}, Autor={Chenyu Zhou und Mengdan Zhang und Peixian Chen und Chaoyou Fu und Yunhang Shen und Xiawu Zheng und Xing Sun und Rongrong Ji}, Jahr={2024}, eprint={2406.10228}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2406.10228}, }
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.