Command Palette
Search for a command to run...
MMDU Sehr Langer Datensatz Zum Verständnis Von Dialogen Mit Mehreren Bildern Und Mehreren Durchläufen
Datum
Größe
Organisation
Veröffentlichungs-URL
Paper-URL
Lizenz
CC BY-NC-SA 3.0
Tags
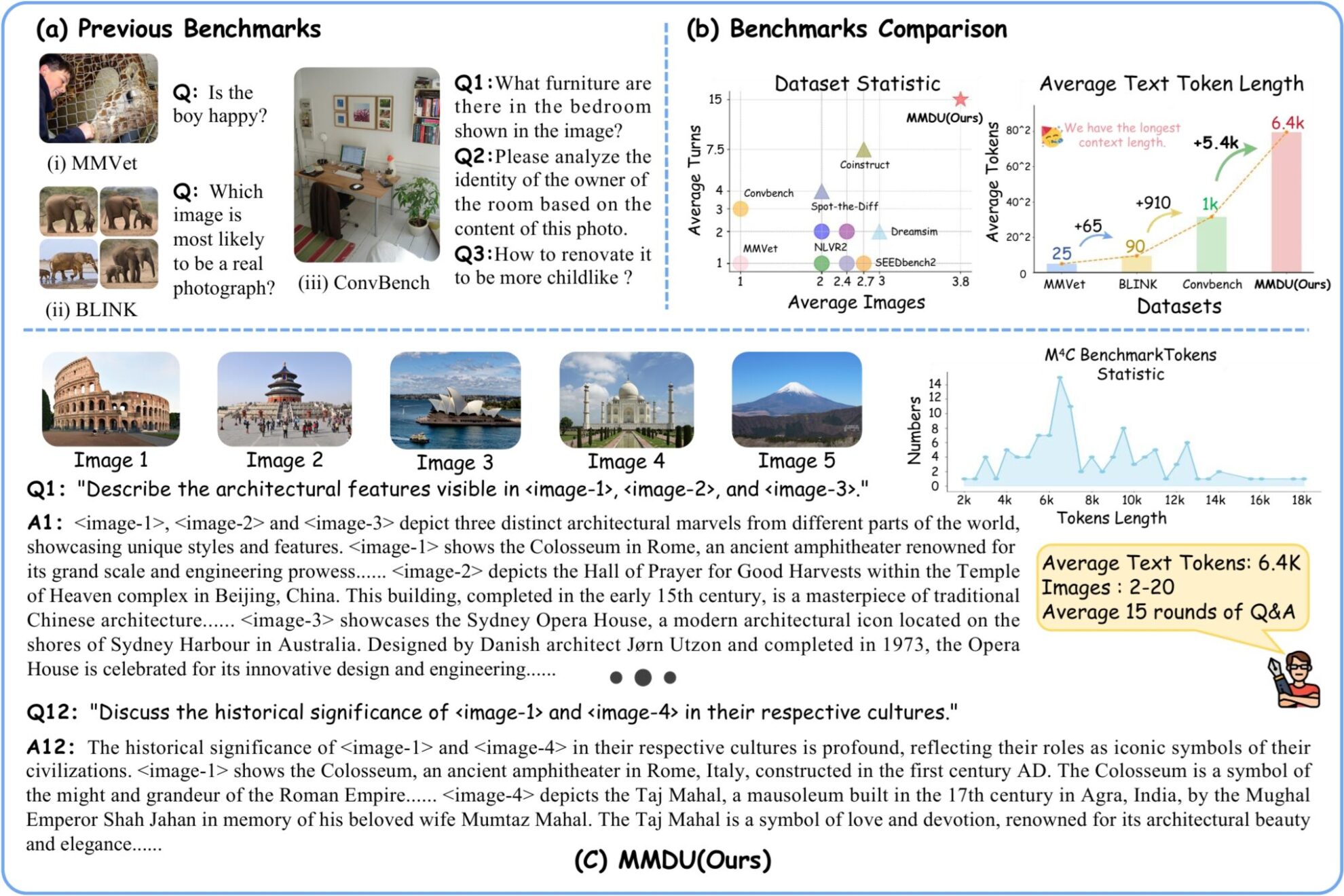
MMDU (Multi-Turn Multi-Image Dialog Understanding) ist ein ultralanger Datensatz zum Verständnis von Dialogen mit mehreren Bildern und mehreren Turns, der 2024 gemeinsam von der Universität Wuhan, dem Shanghai Artificial Intelligence Laboratory, der Chinesischen Universität Hongkong und Moore Threads veröffentlicht wurde. Das Forschungsteam veröffentlichte das PapierMMDU: Ein Multi-Turn Multi-Image Dialog Understanding Benchmark und Instruction-Tuning Dataset für LVLMs„In dem Artikel werden ein neuer Multi-Image-Multi-Round-Evaluierungs-Benchmark MMDU und ein groß angelegter Feinabstimmungsdatensatz für Anweisungen MMDU-45k vorgeschlagen, mit dem Ziel, die Leistung von LVLMs in Multi-Round- und Multi-Image-Konversationen zu bewerten und zu verbessern. Der Benchmark besteht aus 110 hochwertigen Dialogen mit mehreren Bildern und mehreren Durchgängen und mehr als 1.600 Fragen, jeweils mit einer ausführlichen Langantwort. Bisherige Benchmarks umfassen meist nur ein einzelnes Bild oder eine kleine Anzahl von Bildern, mit weniger Fragerunden und kurzen Antworten. Allerdings erhöht MMDU die Anzahl der Bilder, Frage-Antwort-Runden und die Kontextlänge von Fragen und Antworten erheblich. Die Probleme in MMUD betreffen 2 bis 20 Bilder mit einer durchschnittlichen Bild- und Text-Taglänge von 8,2.000 Tags und einer maximalen Bild- und Textlänge von 18.000 Tags, was für bestehende multimodale Großmodelle erhebliche Herausforderungen darstellt. In MMDU-45k hat das Forschungsteam insgesamt 45.000 Dialoge zur Befehlsoptimierung erstellt. Alle Daten im MMDU-45k-Datensatz haben einen sehr langen Kontext mit einer durchschnittlichen Bild-Text-Tokenlänge von 5 KB und einer maximalen Bild-Text-Tokenlänge von 17 KB. Jedes Gespräch umfasst durchschnittlich 9 Frage-Antwort-Runden und maximal 27 Runden. Darüber hinaus enthält jedes Datenelement den Inhalt von 2–5 Bildern. Der Datensatz ist in einem sorgfältig entworfenen Format mit hervorragender Skalierbarkeit aufgebaut und kann kombiniert werden, um mehr und längere Multi-Graph-Multi-Turn-Konversationen zu generieren. Die Diagrammlänge und die Anzahl der Runden in MMDU-45k übertreffen alle vorhandenen Datensätze zur Befehlsoptimierung erheblich. Diese Verbesserung verbessert die Fähigkeit des Modells zur Erkennung und zum Verständnis mehrerer Bilder sowie seine Fähigkeit, lange Kontextkonversationen zu verarbeiten, erheblich. Der MMDU-Benchmark bietet folgende Vorteile: **(1) Mehrrundendialog und Mehrbildeingabe:**Der MMDU-Benchmark besteht aus bis zu 20 Bildern und 27 Runden von Frage-und-Antwort-Dialogen, übertrifft mehrere vorherige Benchmarks und bildet reale Chat-Interaktionsszenarien realistisch nach. **(2) Langer Kontext:**Der MMDU-Benchmark bewertet die Fähigkeit von LVLMs, Kontextinformationen mit langen Kontextverläufen durch bis zu 18.000 Text- und Bild-Token zu verarbeiten und zu verstehen. **(3) Offene Bewertung:**MMDU verzichtet auf die geschlossenen Fragen und kurzen Ergebnisse (z. B. Multiple-Choice-Fragen oder kurze Antworten), auf denen herkömmliche Benchmarks basieren, und verfolgt einen realistischeren und verfeinerten Bewertungsansatz. Es bewertet die Leistung von LVLM durch frei formulierte Mehrrundenausgaben und betont dabei die Skalierbarkeit und Interpretierbarkeit der Bewertungsergebnisse. Beim Erstellen von MMDU wählten die Forscher hochrelevante Bilder und Textinformationen aus der Open-Source-Wikipedia aus und mithilfe des GPT-4o-Modells erstellten menschliche Kommentatoren Frage- und Antwortpaare.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.