Command Palette
Search for a command to run...
HellaSwag Großer Modell-Datensatz Zum Gesunden Menschenverstand
Datum
Größe
Organisation
Veröffentlichungs-URL
Paper-URL
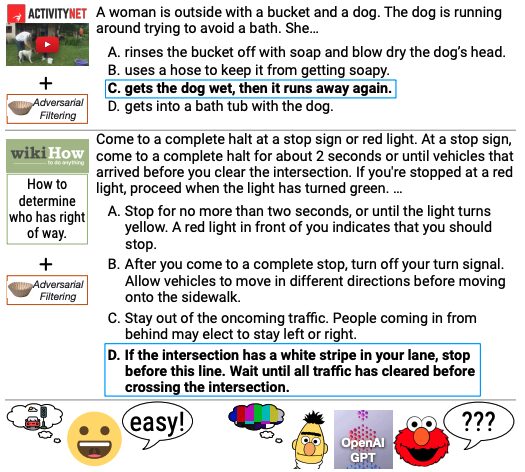
Der HellaSwag-Datensatz ist ein neuer Challenge-Datensatz zum Testen der Commonsense-Inferenz natürlicher Sprache (Commonsense NLI). Der Datensatz wurde 2019 von der University of Washington und Allen AI mit dem Ziel veröffentlicht, die Leistungsfähigkeit tief vortrainierter Modelle im Bereich des gesunden Menschenverstands zu untersuchen, indem ein Datensatz erstellt wird, der eine Herausforderung für bestehende hochmoderne Modelle darstellt. Verwandte Artikel und ErgebnisseHellaSwag: Kann eine Maschine Ihren Satz wirklich beenden?" wurde von ACL 2019 angenommen. Der HellaSwag-Datensatz enthält 70.000 Fragen, die zwar für Menschen sehr einfach zu beantworten sind (Genauigkeit von über 95%), aber selbst modernste Modelle haben Schwierigkeiten, eine Leistung zu erreichen, die dem menschlichen Niveau nahe kommt (Genauigkeit von etwa 48%). Der Datensatz wird mithilfe der Adversarial Filtering (AF)-Methode erstellt. Dabei wird eine Reihe von Diskriminatoren verwendet, um maschinengenerierte falsche Antworten iterativ auszuwählen und so den Schwierigkeitsgrad des Datensatzes zu erhöhen. Die Entwicklung von HellaSwag gibt Aufschluss über die Funktionsweise tiefgreifender, vortrainierter Modelle und bietet eine neue Richtung für die NLP-Forschung, bei der Benchmarks in einer kontroversen Weise gemeinsam mit hochmodernen Modellen weiterentwickelt werden, um anspruchsvollere Aufgaben bereitzustellen.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.