HyperAI
Command Palette
Search for a command to run...
梯度累积 Gradient Accumulation
日期
2 年前
标签
梯度累积 (Gradient Accumulation) 是一种将用于训练神经网络的样本批次分成几个按顺序运行的小 Batch 样本的机制。
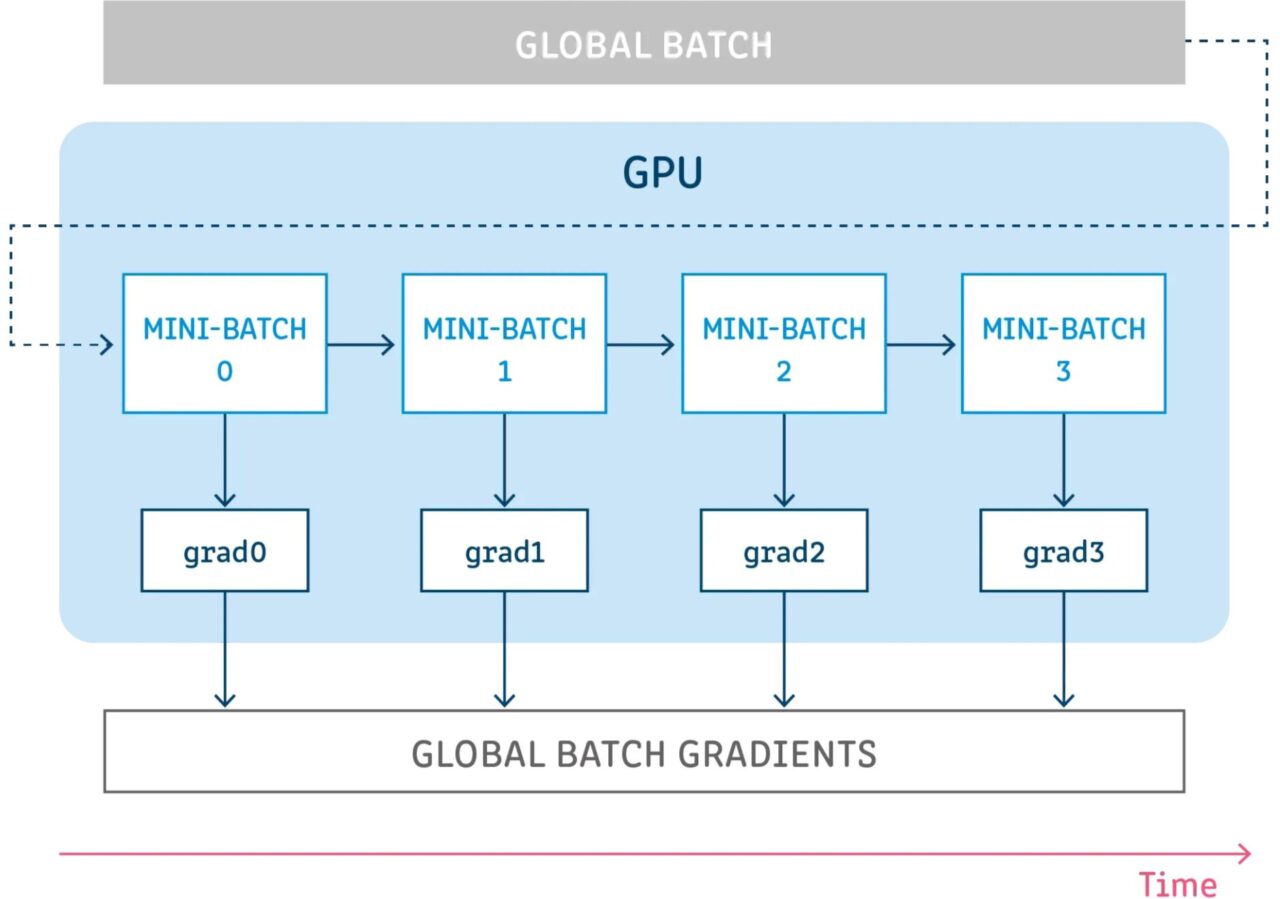
在进一步讨论梯度累积之前,最好回顾一下神经网络的反向传播过程。
神经网络的反向传播
深度学习模型由许多相互连接的层组成,其中样本在每一步中都通过前向传播进行传播。在传播完所有层后,网络生成样本的预测,然后计算每个样本的损失值,该值指定「网络对于该样本的错误有多大」。然后,神经网络计算这些损失值相对于模型参数的梯度。这些梯度用于计算各个变量的更新。
在构建模型时,选择一个优化器,它负责用于最小化损失的算法。优化器可以是框架中已实现的常见优化器之一(SGD 、 Adam 等),也可以是实现所需算法的自定义优化器。除了梯度之外,优化器还可能管理和使用更多参数来计算更新,例如学习率、当前步骤索引(用于自适应学习率)、动量等……
技术上的梯度累积
梯度累积意味着在累积这些步骤的梯度时,在不更新模型变量的情况下运行配置的一定数量的步骤,然后使用累积的梯度来计算变量更新。
在不更新任何模型变量的情况下运行一些步骤是从逻辑上将样本批次分割成几个小 Batch 的方式。在每个步骤中使用的样本批次实际上是一个小批次,而所有这些步骤中的样本组合起来实际上是全局批次。
通过在所有这些步骤中不更新变量,使所有小批次使用相同的模型变量来计算梯度。这是强制性的行为,以确保计算相同的梯度和更新,就好像使用全局批次大小一样。
在所有这些步骤中累积梯度会产生相同的梯度总和。
参考来源
【1】https://towardsdatascience.com/what-is-gradient-accumulation-in-deep-learning-ec034122cfa