Command Palette
Search for a command to run...
旋转位置编码 RoPE (Rotary Position Embedding)
日期
旋转位置编码 RoPE (Rotary Position Embedding) 是论文「Roformer: Enhanced Transformer With Rotray Position Embedding」中提出的一种能够将相对位置信息依赖集成到 self-attention 中并提升 transformer 架构性能的位置编码方式。它是目前大模型中广泛使用的一种位置编码,包括但不限于 Llama 、 Baichuan 、 ChatGLM 、 Qwen 等。由于计算资源限制,目前的大模型大多在较小的上下文长度中进行训练,在推理中,若超出预训练的长度,模型的性能将会显著降低。于是涌现出了许多基于 RoPE 的长度外推的工作,旨在让大模型能够在预训练长度之外,取得更好的效果。所以弄清楚 RoPE 的底层原理,对于 RoPE-base 模型进行长度外推至关重要。
RoPE 的基本原理
RoPE 的基本原理是将每个位置编码为一个旋转矢量,该矢量的长度和方向与位置信息相关。具体来说,对于一个长度为 n 的序列,RoPE 将每个位置 i 编码为一个旋转矢量 pe_i,其定义如下:
pe_i = (sin(iomega), cos(iomega))
其中,omega 是一个超参数,控制旋转矢量的频率。
RoPE 的优势
RoPE 的与众不同之处在于它能够将显式相对位置依赖性无缝集成到模型的自注意力机制中。这种动态方法有 3 个优点:
- 序列长度的灵活性:传统的位置嵌入通常需要定义最大序列长度,限制了它们的适应性。另一方面,RoPE 非常灵活。它可以为任意长度的序列即时生成位置嵌入。
- 减少 token 间的依赖关系:RoPE 在对 token 之间的关系进行建模方面非常聪明。随着 token 在序列中彼此距离越来越远,RoPE 自然会减少它们之间的 token 依赖性。这种逐渐减弱的方式与人类理解语言的方式更加一致。
- 增强的自注意力:RoPE 为线性自注意力机制配备了相对位置编码,这是传统绝对位置编码中不存在的功能。此增强功能允许更精确地利用 token 嵌入。
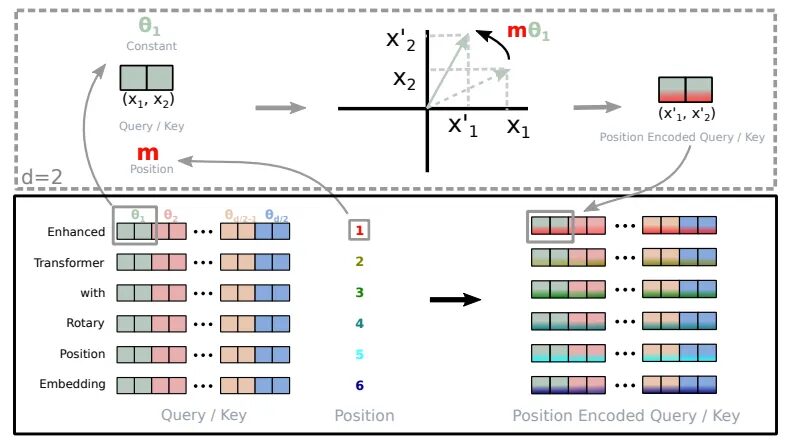
旋转编码的实现(取自 Roformer)
传统的绝对位置编码类似于指定单词出现在位置 3 、 5 或 7,而与上下文无关。相比之下,RoPE 让模型了解单词之间是如何相互关联的。它认识到单词 A 经常出现在单词 B 之后和单词 C 之前。这种动态理解增强了模型的性能。
RoPE 的实现
分解旋转位置编码 (RoPE) 的代码来理解它的实现方法。
precompute_theta_pos_frequencies函数计算 RoPE 的特殊值。首先定义一个名为theta的超参数来控制旋转的幅度。较小的值会产生较小的旋转。然后,它使用计算一组旋转角度theta。该函数还创建序列中的位置列表,并通过获取位置列表和旋转角度的外积来计算每个位置应旋转的程度。最后,它将这些值转换为具有固定大小的极坐标形式的复数,这就像表示位置和旋转的密码。apply_rotary_embeddings函数采用数值并用旋转信息增强它们。它首先将输入值的最后一个维度分成代表实部和虚部的对。然后将这些对组合成单个复数。接下来,该函数将预先计算的复数与输入相乘,从而有效地应用旋转。最后,它将结果转换回实数并重塑数据,为进一步处理做好准备。
参考来源
【1】https://www.bolzjb.com/archives/PiBBdbZ7.html