HyperAI
Command Palette
Search for a command to run...
HuMo-17B:三模态协同创作
一、教程简介

HuMo 是由清华大学和字节跳动智能创作实验室于 2025 年 9 月发布的多模态视频生成框架,专注于人类中心的视频生成。能从文本、图像和音频等多种模态输入中生成高质量、精细且可控的人类视频。 HuMo 支持强大的文本提示跟随能力、一致的主体保留以及音频驱动的动作同步。支持从文本-图像(VideoGen from Text-Image)、文本-音频(VideoGen from Text-Audio)以及文本-图像-音频生成视频(VideoGen from Text-Image-Audio),相关论文成果为 HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning 。
HuMo 项目提供 1.7B 和 17B 两种规格的模型部署,本教程使用模型为 17B,采用资源为单卡 RTX pro 6000 。
→点击跳转体验「HuMo 1.7B:多模态视频生成框架」。
二、项目示例
VideoGen from Text-Image-Audio,TIA
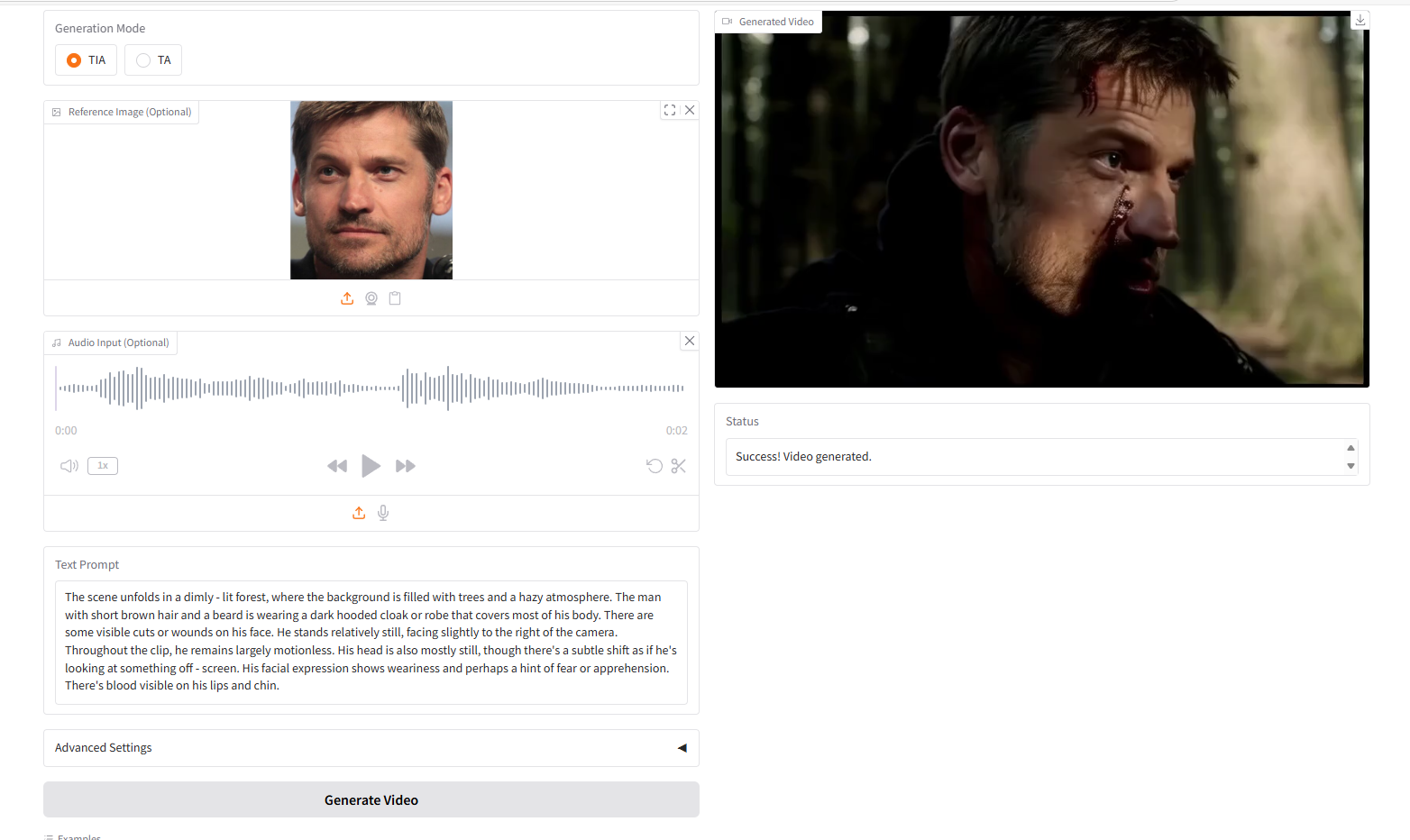
VideoGen from Text-Audio,TA
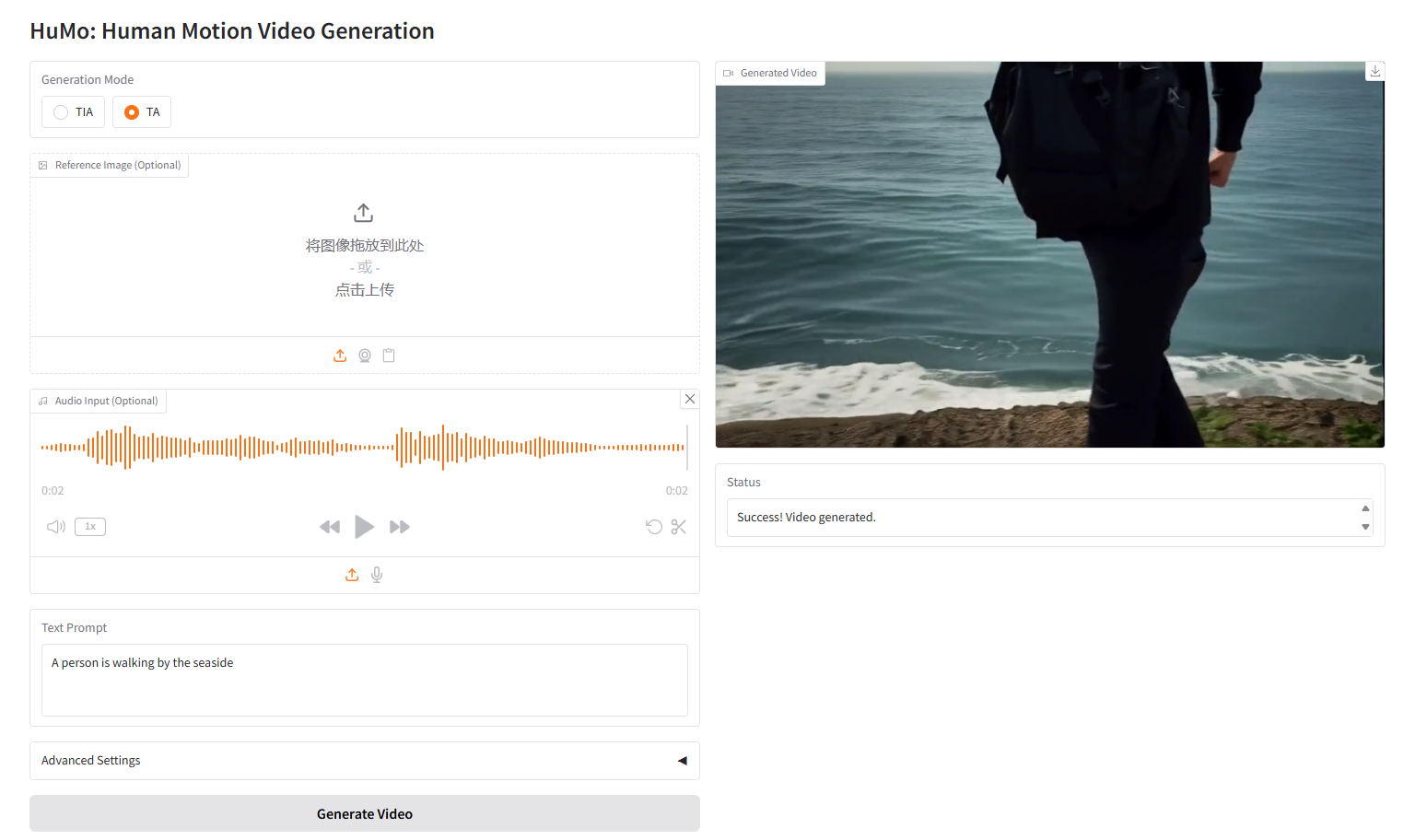
三、运行步骤
1. 启动容器后点击 API 地址即可进入 Web 界面
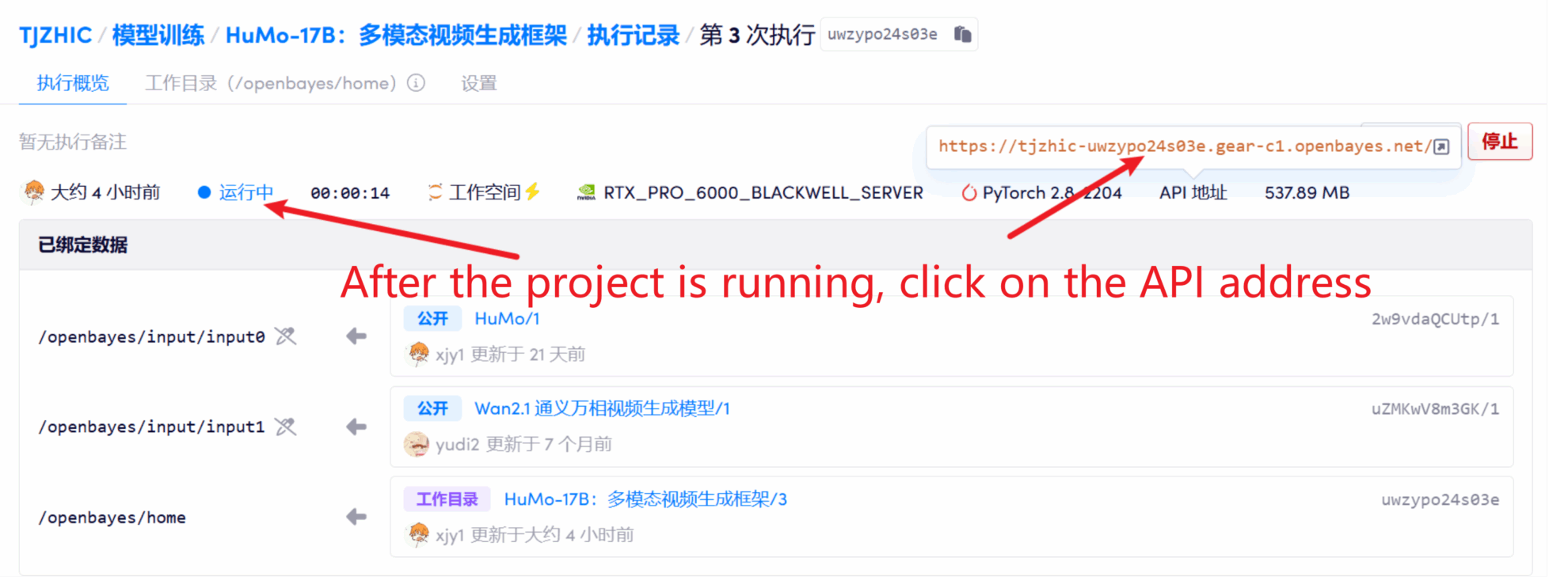
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。 注意:当 Sampling Steps 设置为 10 时,生成结果大约需要 3-5 分钟。
TIA
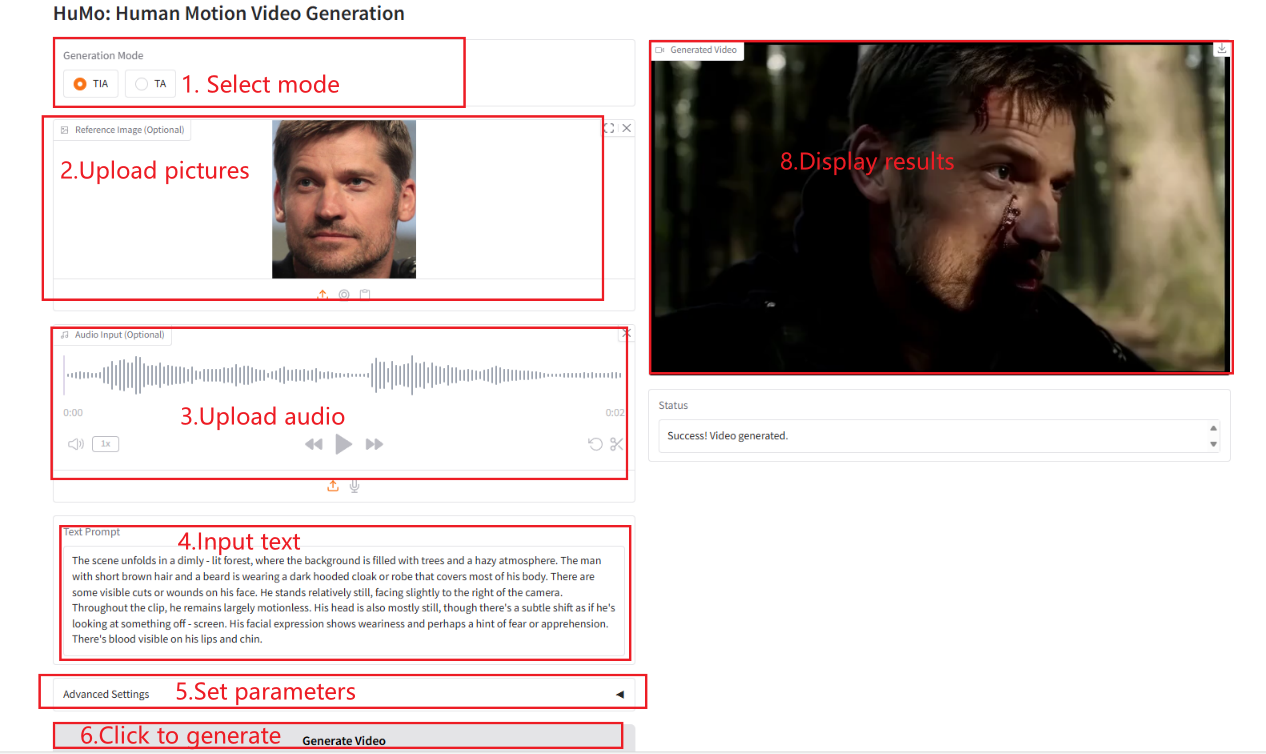
TA
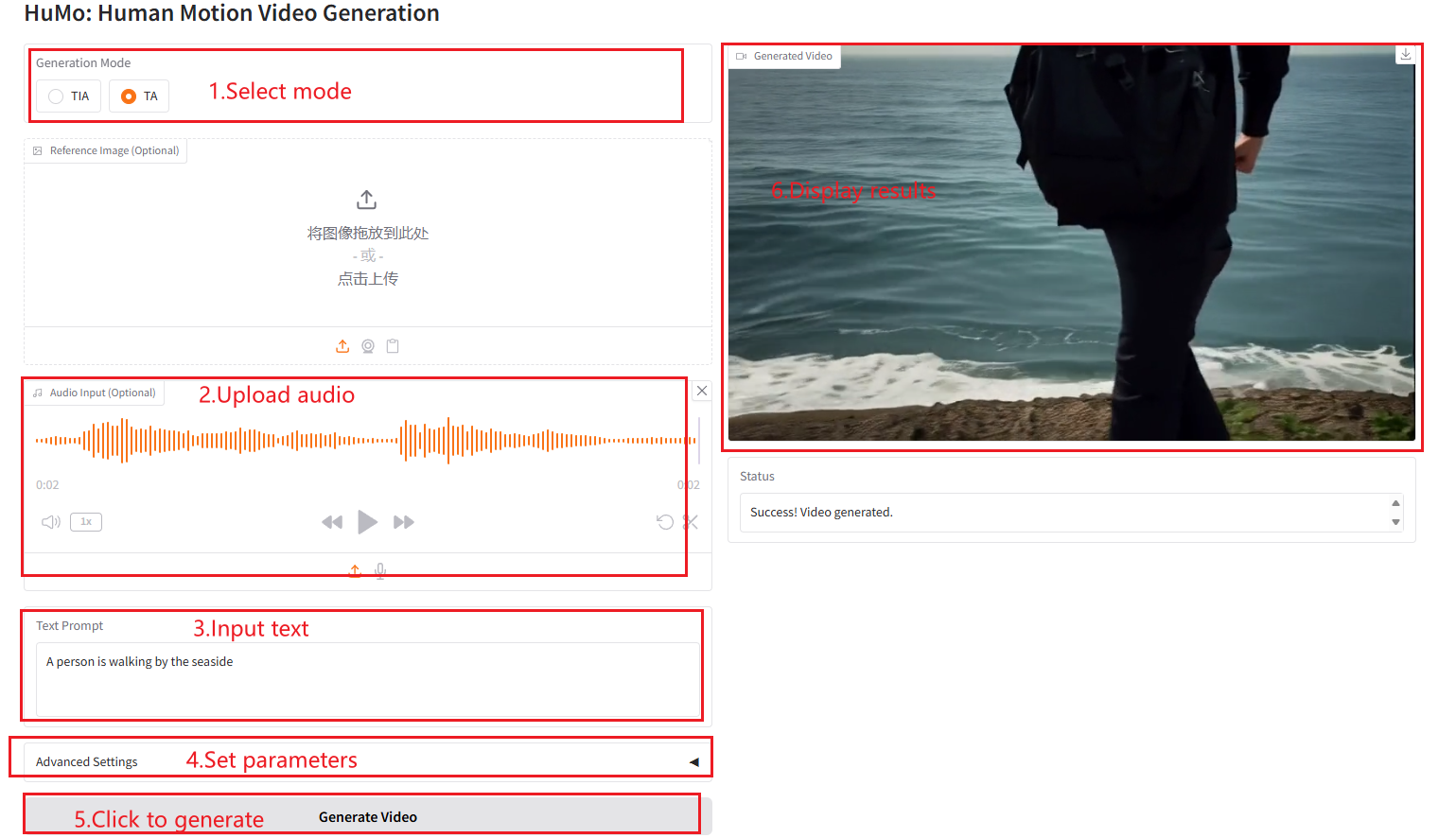
参数说明
- Height:设置视频的高度。
- Width:设置视频的宽度。
- Frames:设置视频的帧数。
- Text Guidance Scale:文本引导缩放比例,用于控制文本提示对视频生成的影响。
- Image Guidance Scale:图像引导缩放比例,用于控制图像提示对视频生成的影响。
- Audio Guidance Scale:音频引导缩放比例,用于控制音频提示对视频生成的影响。
- Sampling Steps:采样步数,用于控制视频生成的质量和细节。
- Random Seed:随机种子,用于控制视频生成的随机性。
引用信息
本项目引用信息如下:
@misc{chen2025humo,
title={HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning},
author={Liyang Chen and Tianxiang Ma and Jiawei Liu and Bingchuan Li and Zhuowei Chen and Lijie Liu and Xu He and Gen Li and Qian He and Zhiyong Wu},
year={2025},
eprint={2509.08519},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.08519},
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。