Command Palette
Search for a command to run...
Pusa-VidGen 视频生成模型 Demo
一、教程简介

Pusa V1 是由 Yaofang-Liu 团队于 2025 年 7 月 25 日提出的高效多模态视频生成模型,基于向量化时间步适应(VTA)技术,解决了传统视频生成模型训练成本高、推理效率低、时序一致性差的核心问题。与依赖大规模数据和算力的传统方法不同,Pusa V1 通过轻量级微调策略,在 Wan2.1-T2V-14B 基础上实现了突破性优化:其训练成本仅 500 美元(为同类模型的 1/200),数据集仅需 4 K 样本(为同类模型的 1/2500),在 8 张 80 GB GPU 上即可完成训练,大幅降低了视频生成技术的应用门槛。同时,它具备强大的多任务能力,不仅支持文本驱动视频(T2V)和图像引导视频(I2V),还能实现视频补全、首尾帧生成、跨场景转场等零样本任务,无需针对特定场景额外训练。更重要的是,其生成性能尤为突出,采用少步推理策略(10 步即可超越基线模型),VBench-I2V 总得分达 87.32%,在动态细节还原(如肢体运动、光影变化)和时序连贯性上表现优异。此外,通过 VTA 技术实现的非破坏性适配机制,既能向基础模型注入时序动态能力,又能保留原模型的图像生成质量,实现「1+1>2」的效果。在部署层面,推理延迟低,可满足从快速预览到高清输出的多样化需求,适用于创意设计、短视频制作等场景。相关论文成果为 PUSA V1.0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation 。
本教程采用资源为双卡 RTX A6000 。
二、项目示例
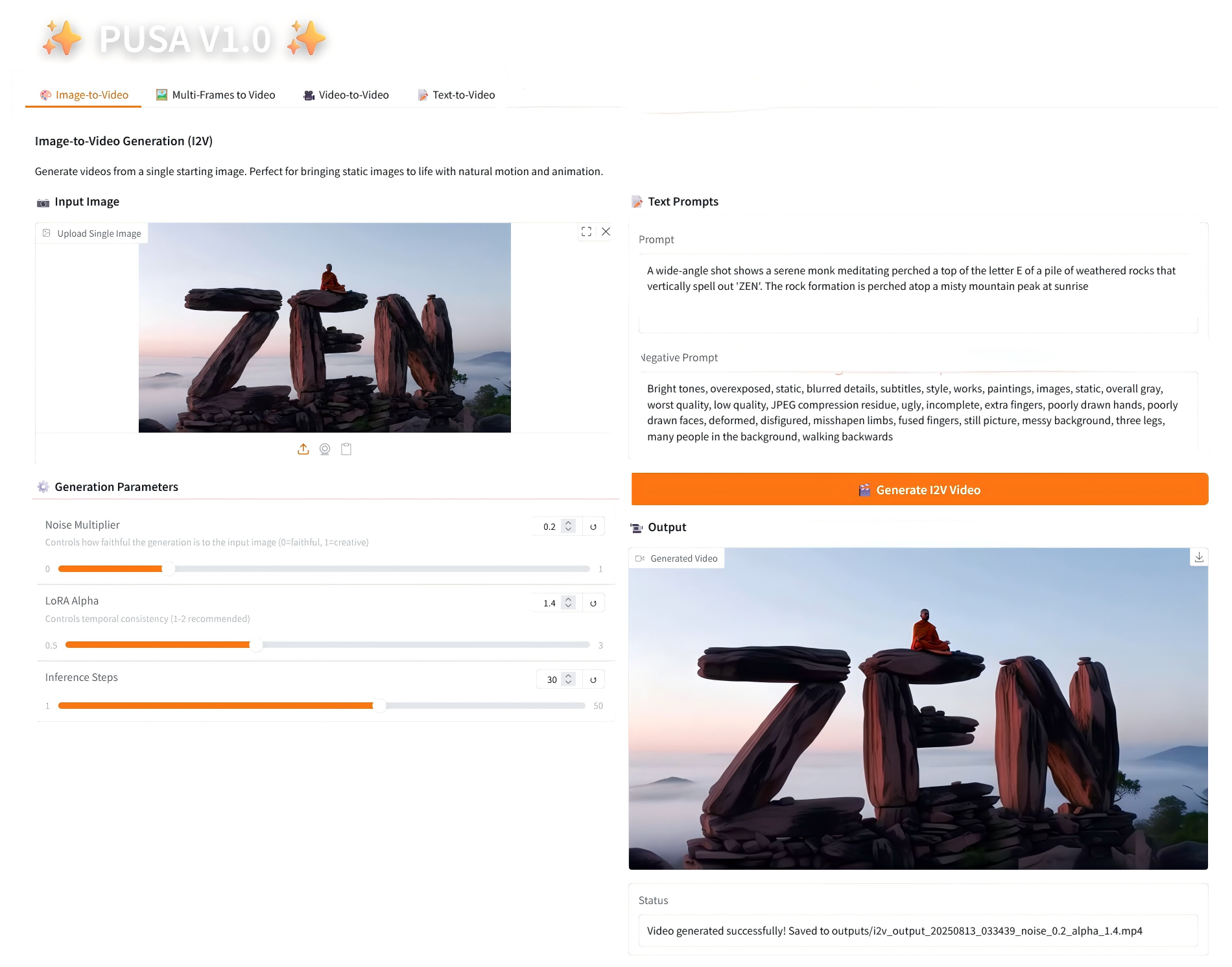
1. Image-to-Video
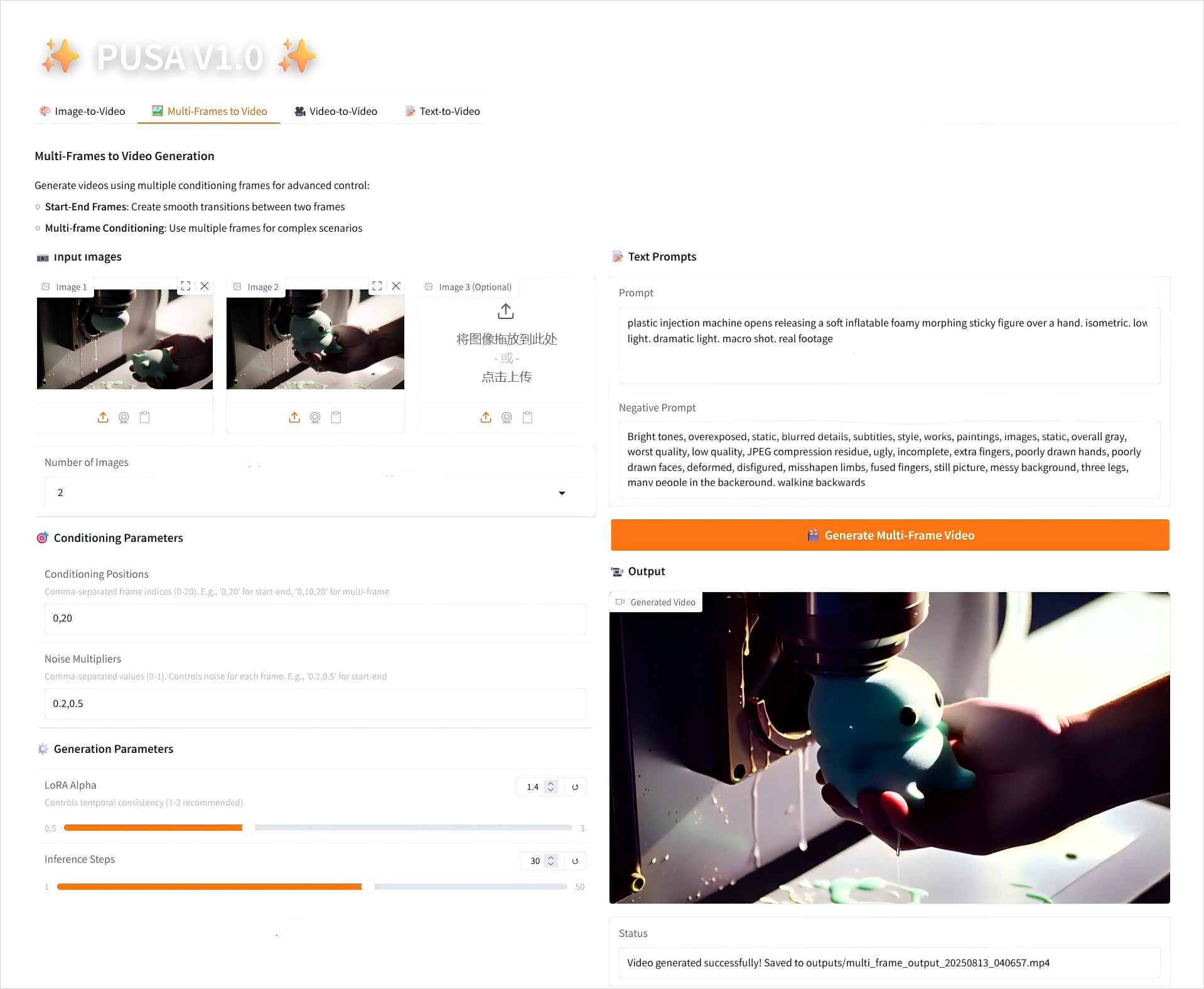
2. Multi-Frames to Video
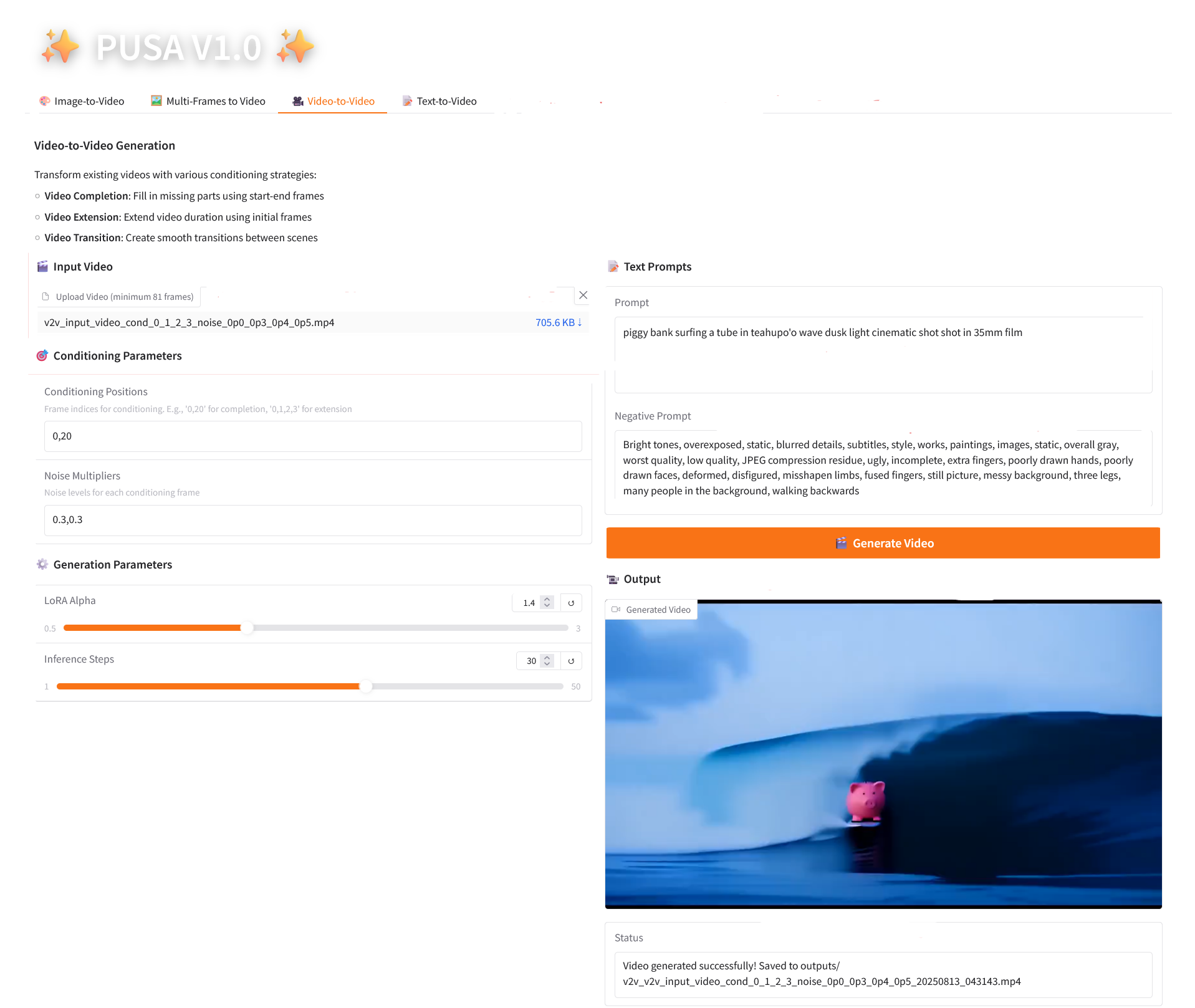
3. Video-to-Video
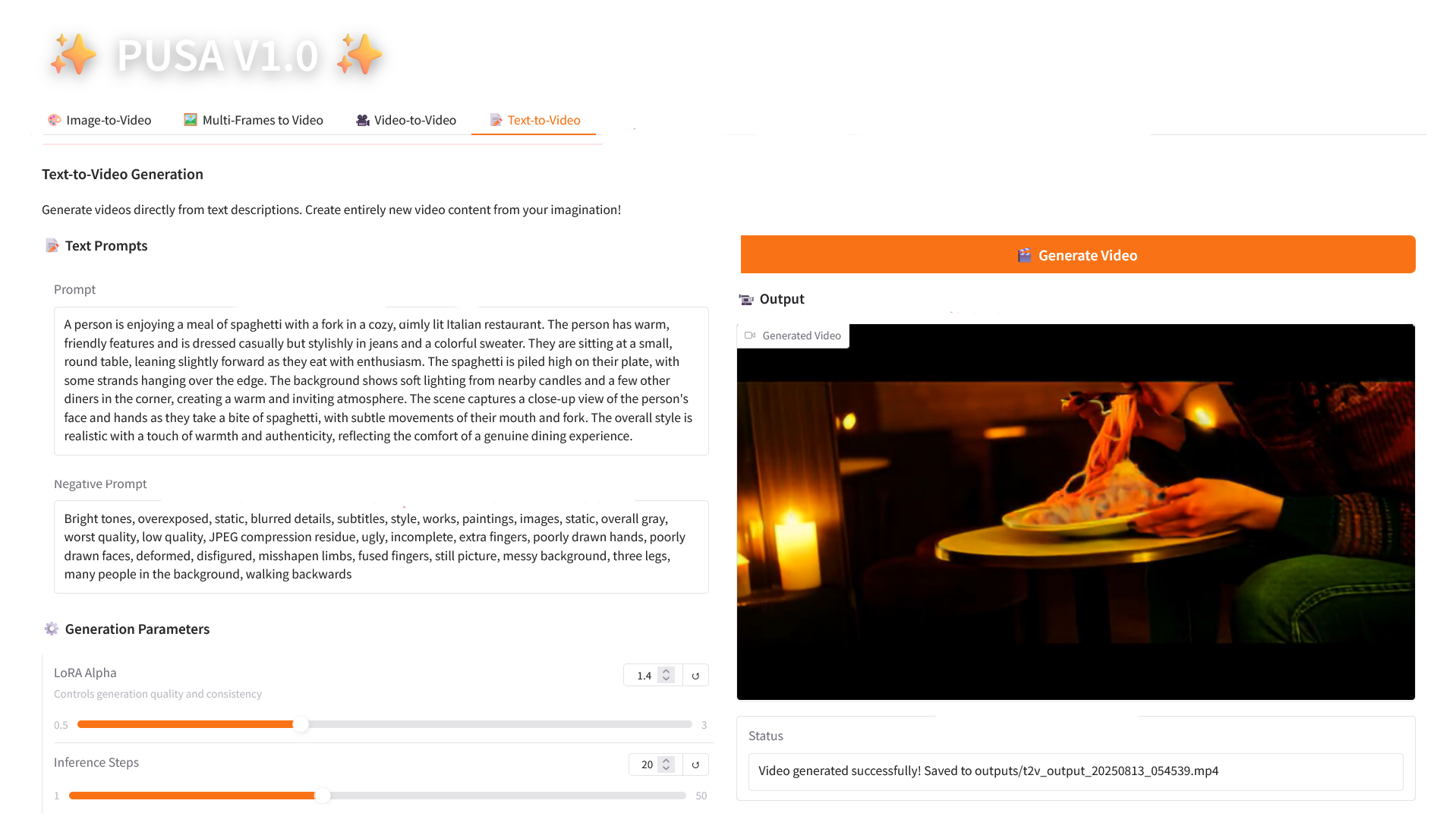
4. Text-to-Video
三、运行步骤
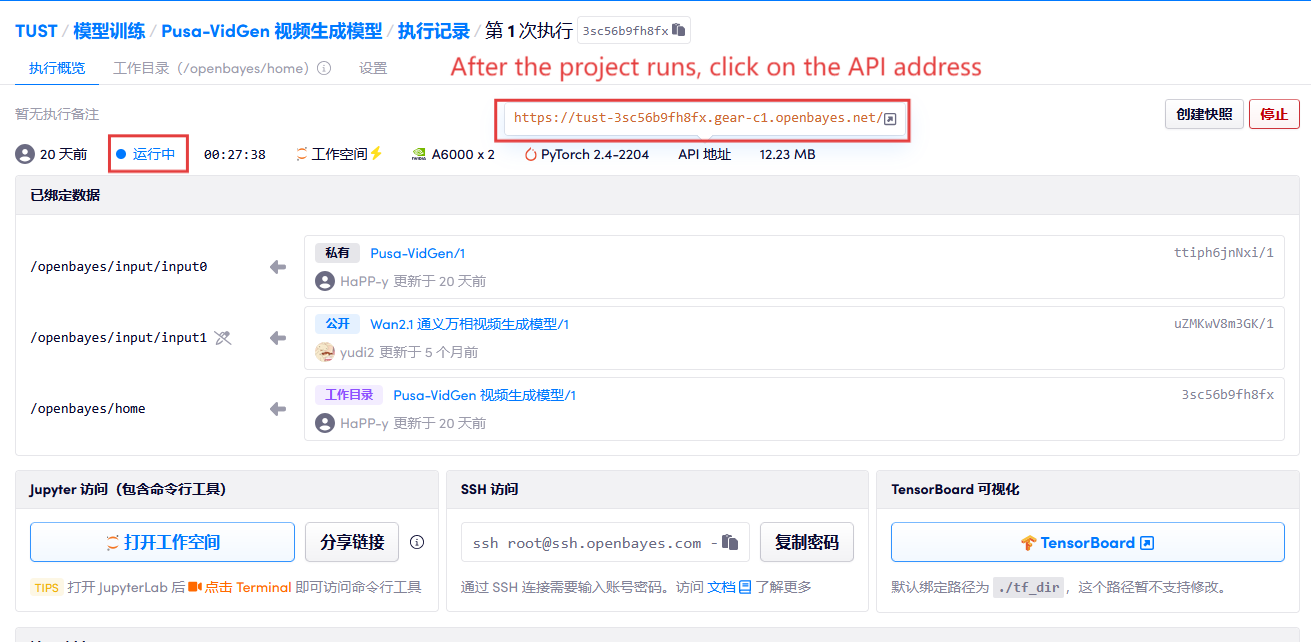
1. 启动容器后点击 API 地址即可进入 Web 界面
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
2.1 Image-to-Video
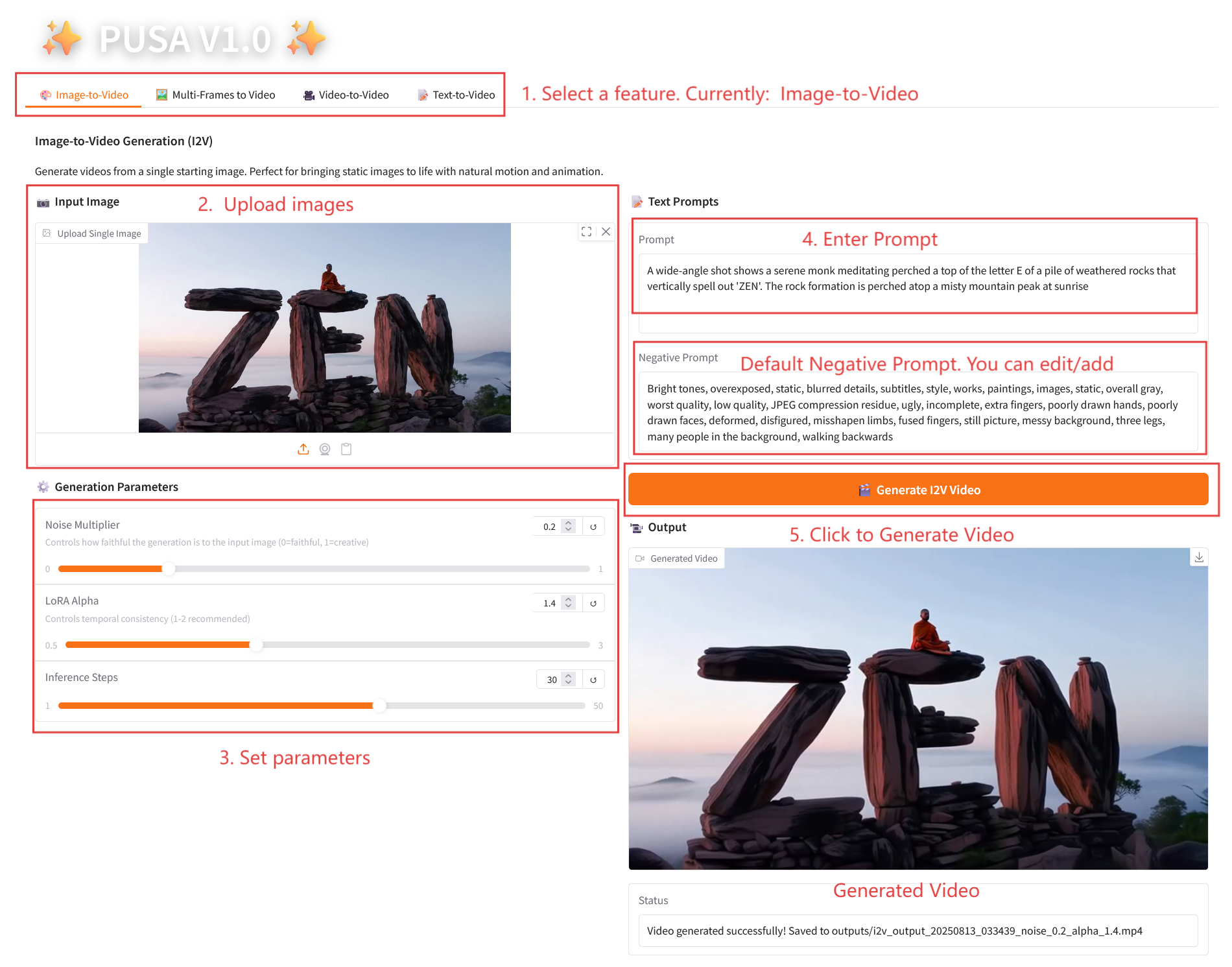
参数说明
- Generation Parameters
- Noise Multiplier:0.0-1.0 可调,默认 0.2(值低更忠实输入图像,值高更具创意变化)。
- LoRA Alpha:0.1-5.0 可调,默认 1.4(控制风格一致性,过高易僵硬,过低易失连贯)。
- Inference Steps:1-50 可调,默认 10(步数越高细节越丰富,但耗时线性增加)。
2.2 Multi-Frames to Video
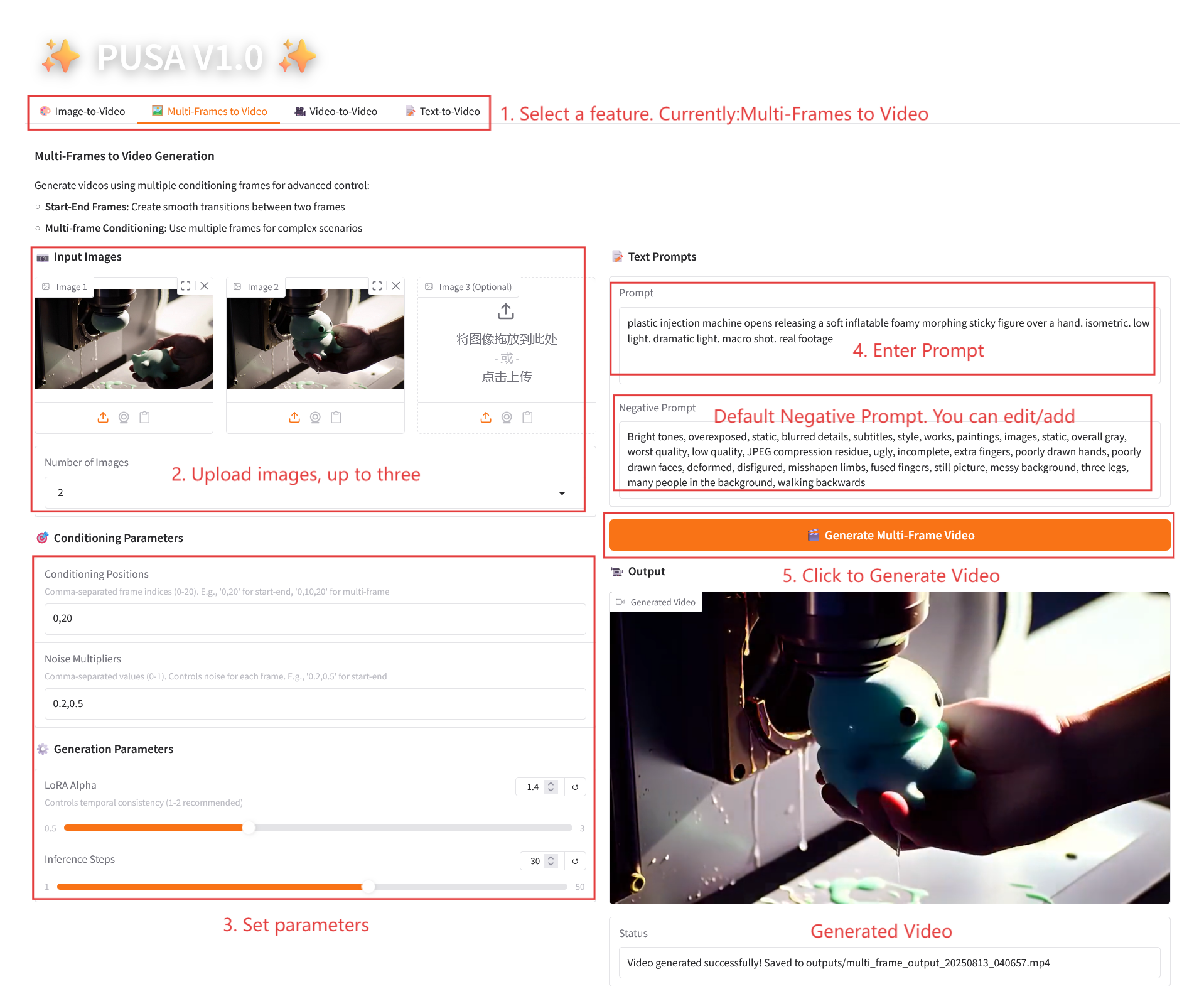
参数说明
- Conditioning Parameters
- Conditioning Positions:逗号分隔帧索引(如「0,20」,定义关键帧在视频中的时间点)。
- Noise Multipliers:逗号分隔的 0.0-1.0 值(如「0.2,0.5」,对应每个关键帧的创意自由度,值低更忠实该帧,值高更具变化)。
- Generation Parameters
- LoRA Alpha:0.1-5.0 可调,默认 1.4(控制风格一致性,过高易僵硬,过低易失连贯)。
- Inference Steps:1-50 可调,默认 10(步数越高细节越丰富,但耗时线性增加)。
2.3 Video-to-Video
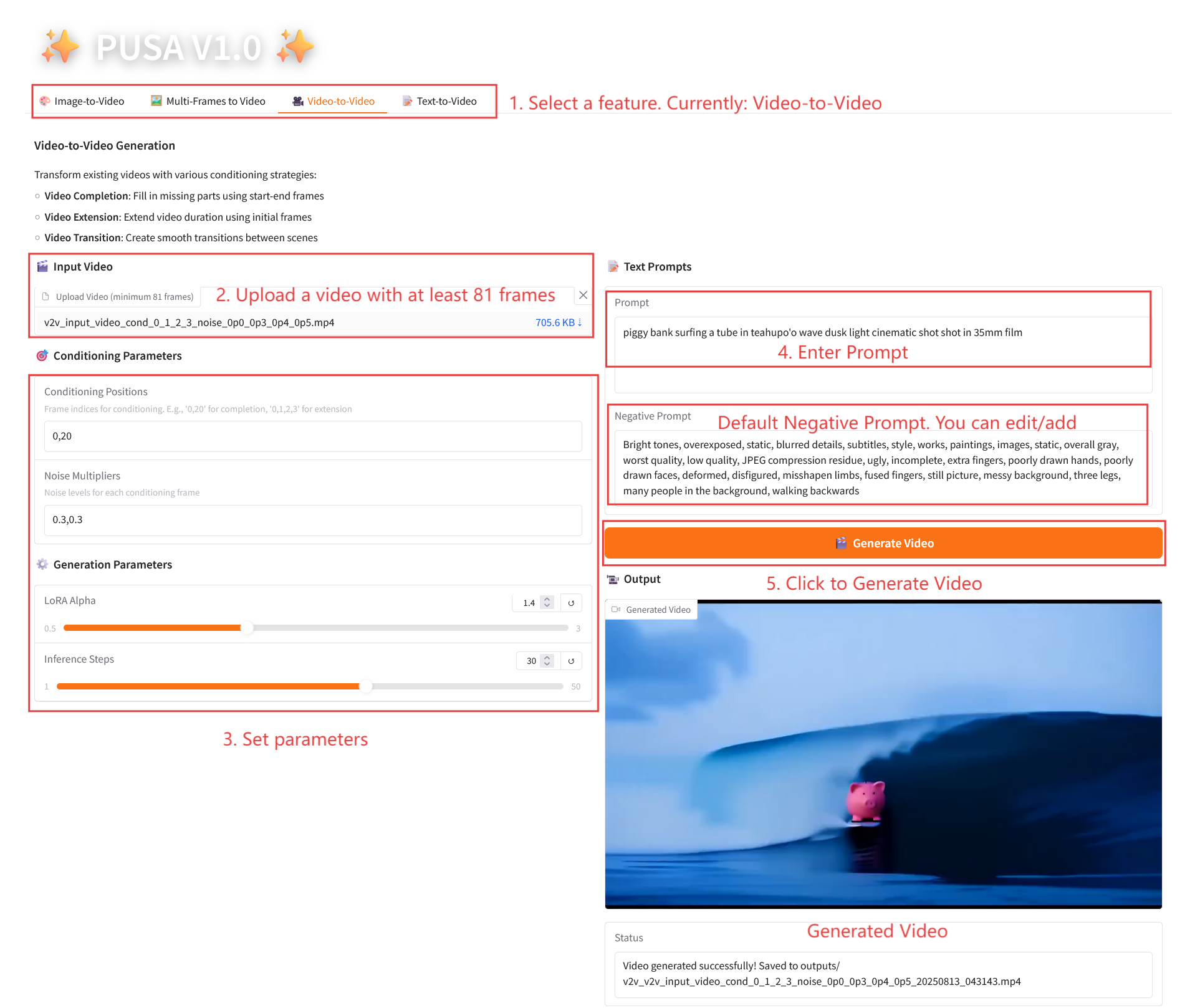
参数说明
- Conditioning Parameters
- Conditioning Positions:逗号分隔的帧索引(如「0,1,2,3」,指定原视频中用于约束生成的关键帧位置,必填)。
- Noise Multipliers:逗号分隔的 0.0-1.0 值(如「0.0,0.3」,对应每个条件帧的影响程度,值低更贴近原帧,值高转换更自由)。
- Generation Parameters
- LoRA Alpha:0.1-5.0 可调,默认 1.4(控制风格一致性,过高易僵硬,过低易失连贯)。
- Inference Steps:1-50 可调,默认 10(步数越高细节越丰富,但耗时线性增加)。
2.4 Text-to-Video
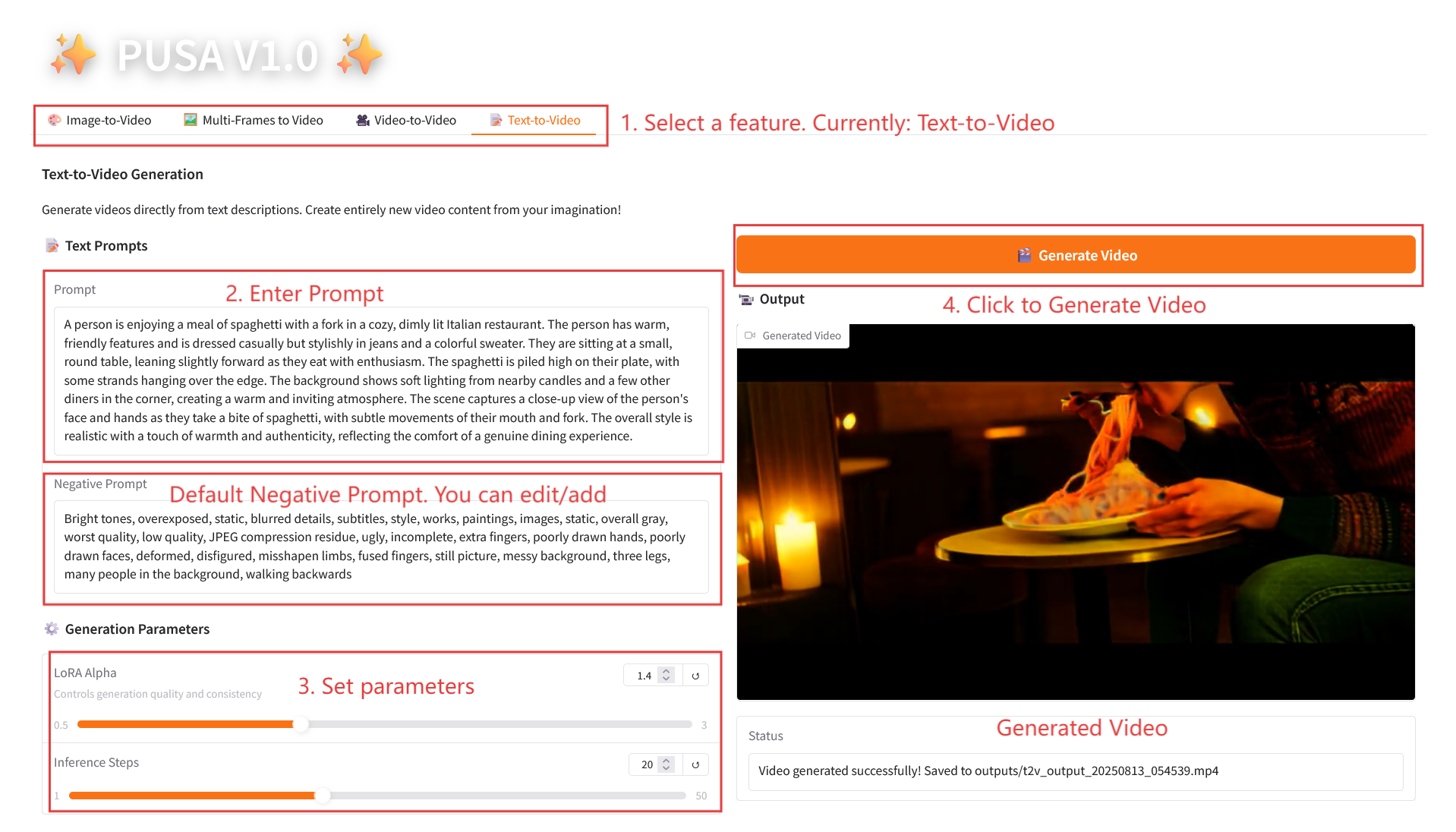
参数说明
- Generation Parameters
- LoRA Alpha:0.1-5.0 可调,默认 1.4(控制风格一致性,过高易僵硬,过低易失连贯)。
- Inference Steps:1-50 可调,默认 10(步数越高细节越丰富,但耗时线性增加)。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@article{liu2025pusa,
title={PUSA V1. 0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation},
author={Liu, Yaofang and Ren, Yumeng and Artola, Aitor and Hu, Yuxuan and Cun, Xiaodong and Zhao, Xiaotong and Zhao, Alan and Chan, Raymond H and Zhang, Suiyun and Liu, Rui and others},
journal={arXiv preprint arXiv:2507.16116},
year={2025}
}
@misc{Liu2025pusa,
title={Pusa: Thousands Timesteps Video Diffusion Model},
author={Yaofang Liu and Rui Liu},
year={2025},
url={https://github.com/Yaofang-Liu/Pusa-VidGen},
}
@article{liu2024redefining,
title={Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach},
author={Liu, Yaofang and Ren, Yumeng and Cun, Xiaodong and Artola, Aitor and Liu, Yang and Zeng, Tieyong and Chan, Raymond H and Morel, Jean-michel},
journal={arXiv preprint arXiv:2410.03160},
year={2024}
}