HyperAI
Command Palette
Search for a command to run...
dots.ocr:多语言文档解析模型
一、教程简介
dots.ocr 是由小红书 hi lab 于 2025 年 8 月发布的多语言文档布局解析模型。模型基于 17 亿参数的视觉语言模型(VLM),能统一进行布局检测和内容识别,保持良好的阅读顺序。模型规模虽小,但性能达到业界领先水平(SOTA),在 OmniDocBench 等基准测试中表现优异,公式识别效果能与 Doubao-1.5 和 gemini2.5-pro 等更大规模模型相媲美,在小语种解析方面优势显著。 dots.ocr 提供简洁高效的架构,任务切换仅需更改输入提示词,推理速度快,适用多种文档解析场景。
本教程采用资源为单卡 RTX 5090 。
二、项目示例
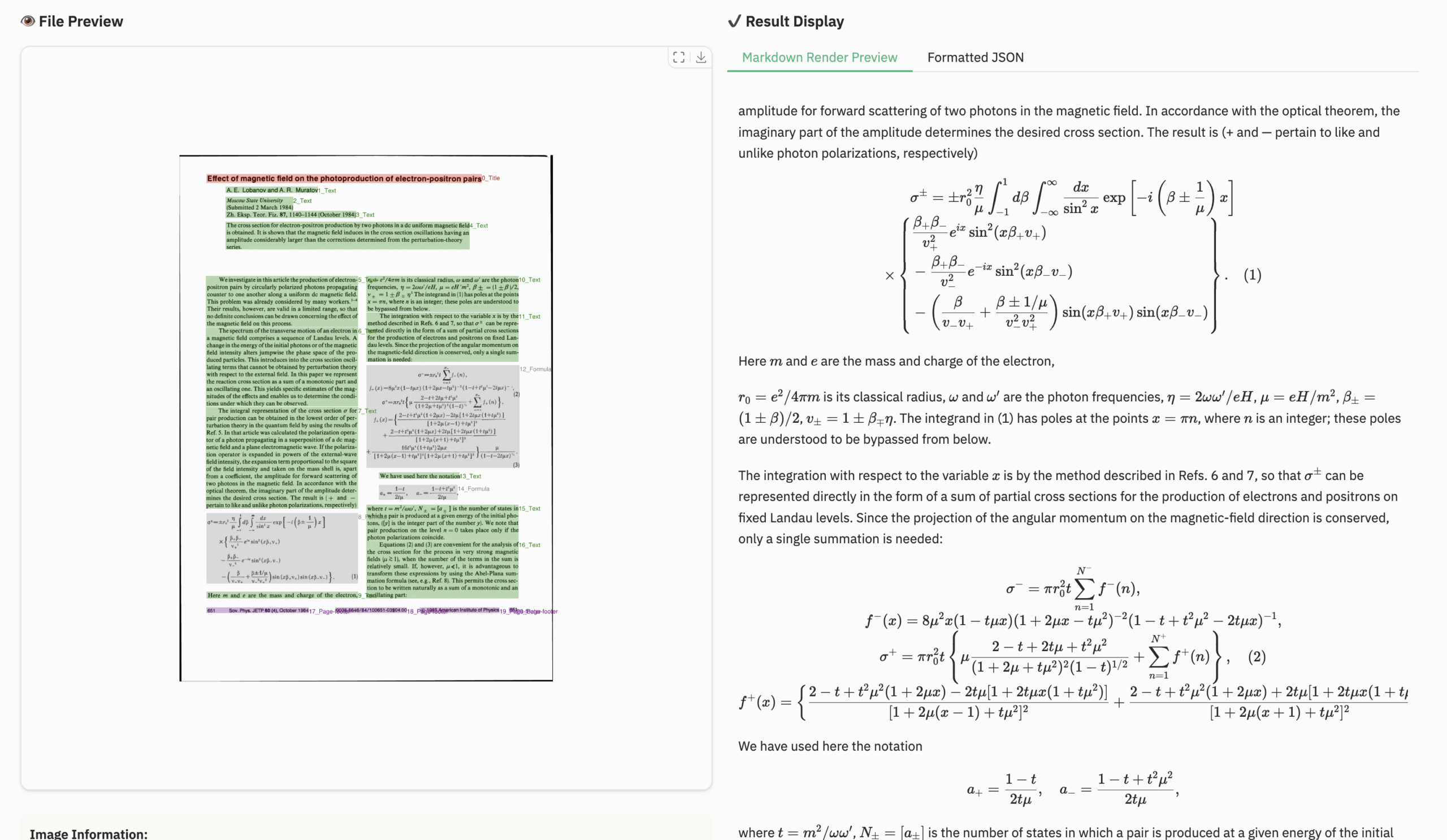
公式文档示例
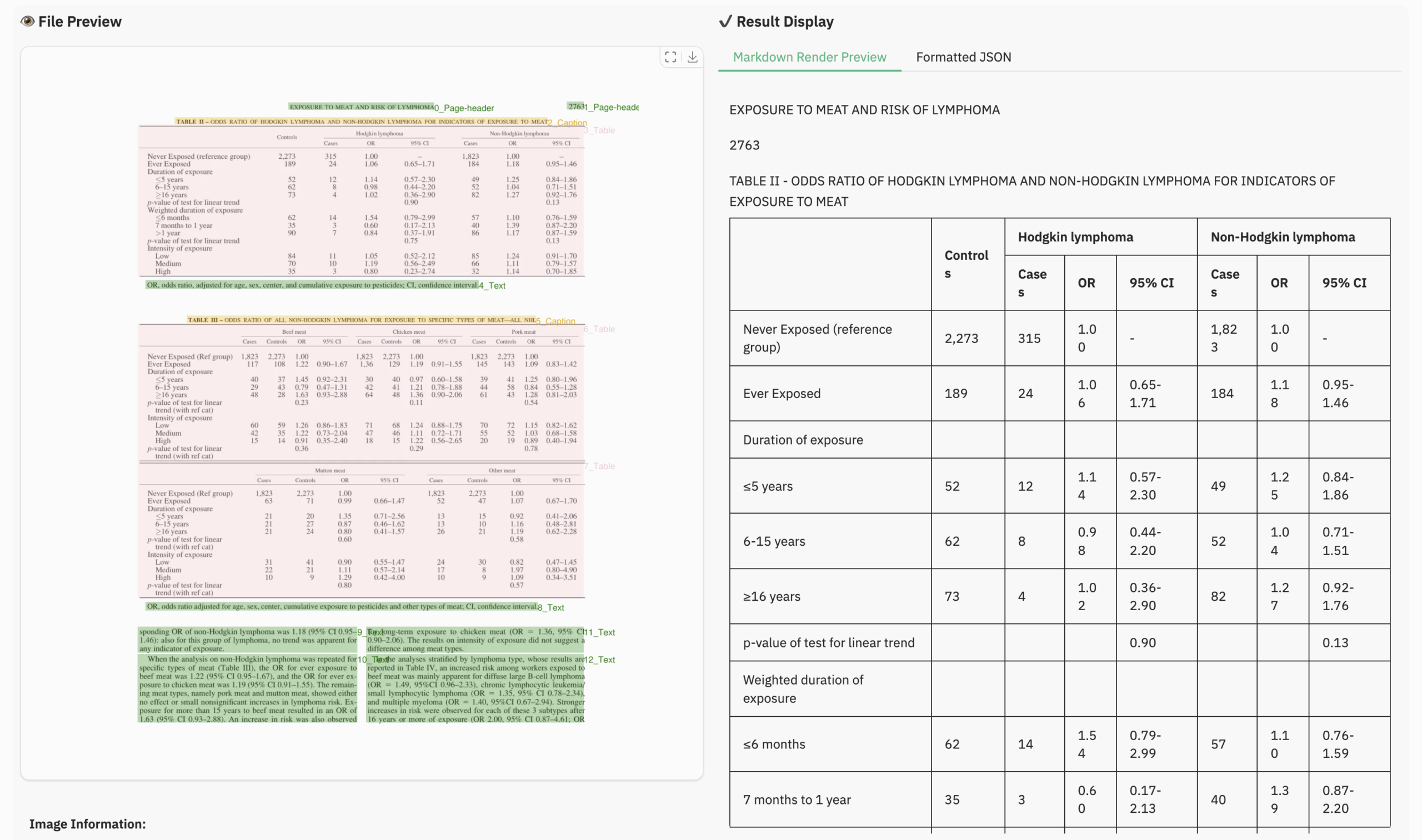
表格文档示例
多语言文档示例



三、运行步骤
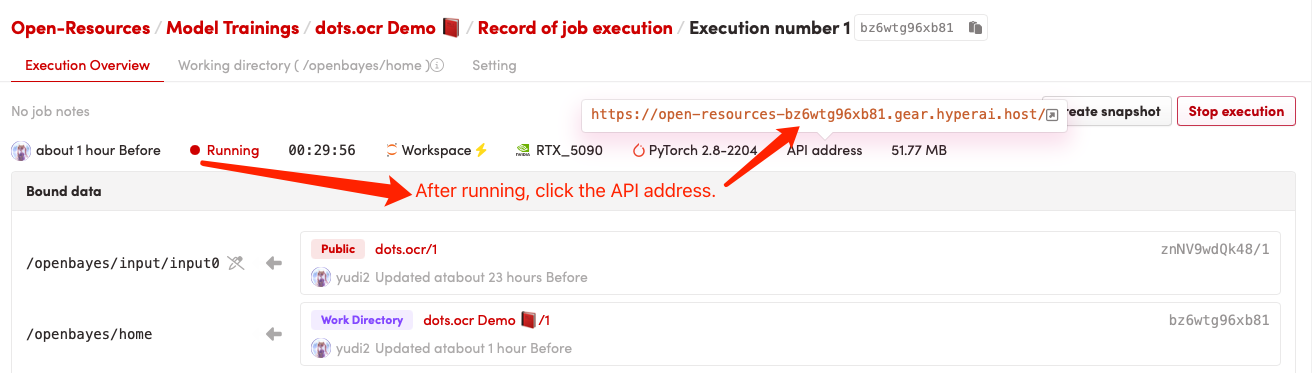
1. 启动容器后点击 API 地址即可进入 Web 界面
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
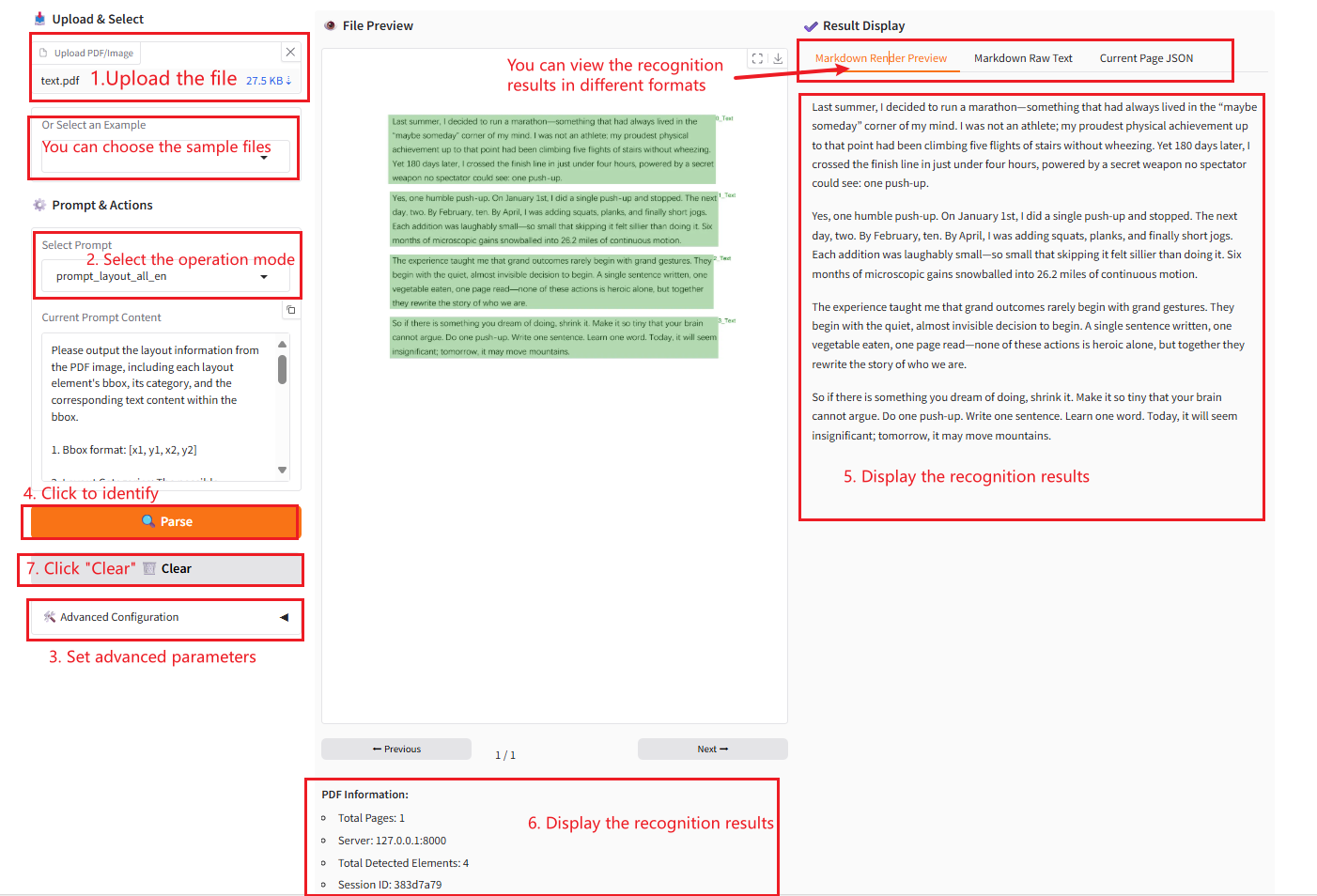
参数说明
- Select Prompt:
- layout_all_en:识别图像中所有文本,并保留原始布局结构。
- layout_only_en:只识别图像中的英文文本,忽略其他语言。
- ocr:识别图像中的文本,不需要保留结构。
- Advanced Settings:
- Enable fitz_preprocess for images:是否为图像启用 fitz_preprocess 预处理。如果图像 DPI 较低,建议使用。
- Min Pixels:图像的最小像素数,用于过滤掉过小的图像。
- Max Pixels:图像的最大像素数,用于过滤掉过大的图像。
本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。