HyperAI
Command Palette
Search for a command to run...
PlayDiffusion:开源音频局部编辑模型
一、教程简介

主要功能:
- 音频局部编辑:支持对音频进行局部替换、修改或删除,无需重生成整段音频,保持语音自然、无缝衔接。
- 高效 TTS:在掩码整个音频时,作为高效 TTS 模型,推理速度比传统 TTS 提高 50 倍,语音自然度和一致性更优。
- 保持语音连贯性:编辑时保留上下文,确保语音连贯性和说话者音色一致。
- 动态语音修改:根据新文本自动调整语音发音、语气和节奏,适用实时互动等场景。
技术原理:
- 音频编码:将输入的音频序列编码为离散的标记序列,每个标记代表音频的一个单元。适用于真实语音和由文本到语音模型生成的音频。
- 掩码处理:当需要修改音频的某个部分时,将该部分标记为掩码,便于后续处理。
- 扩散模型去噪:基于更新文本的扩散模型对掩码区域进行去噪。扩散模型基于逐步去除噪声,生成高质量的音频标记序列。用非自回归方法,同时生成所有标记基于固定数量的去噪步骤进行细化。
- 解码为音频波形:将生成的标记序列基于 BigVGAN 解码器模型转换回语音波形,确保最终输出的语音自然且连贯。
该教程算力资源采用单卡 RTX A6000,提供 Inpaint 、 Text to Speech 、 Voice Conversion 三个示例供测试,本教程仅支持英语。
二、效果展示
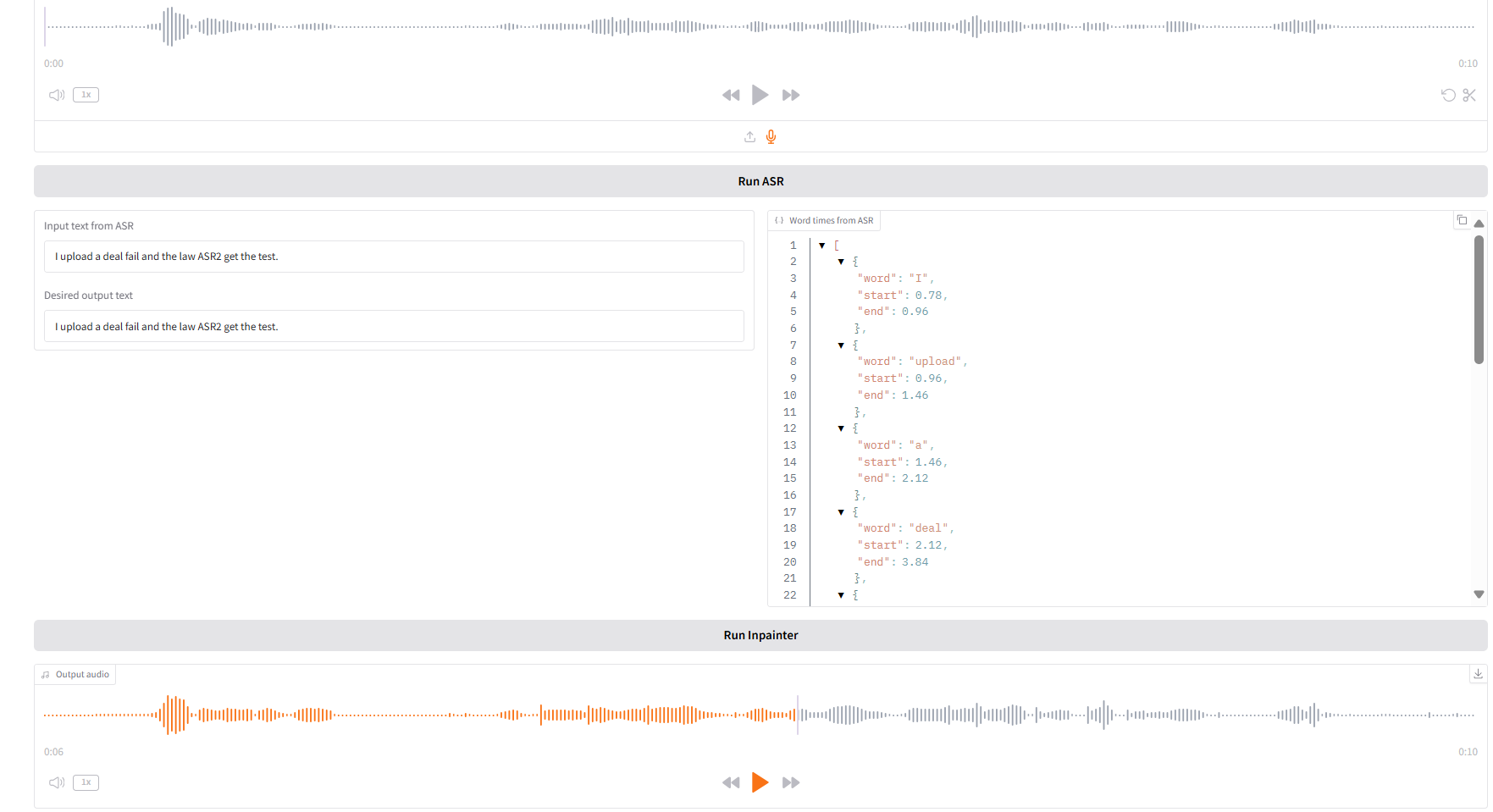
1. Inpaint
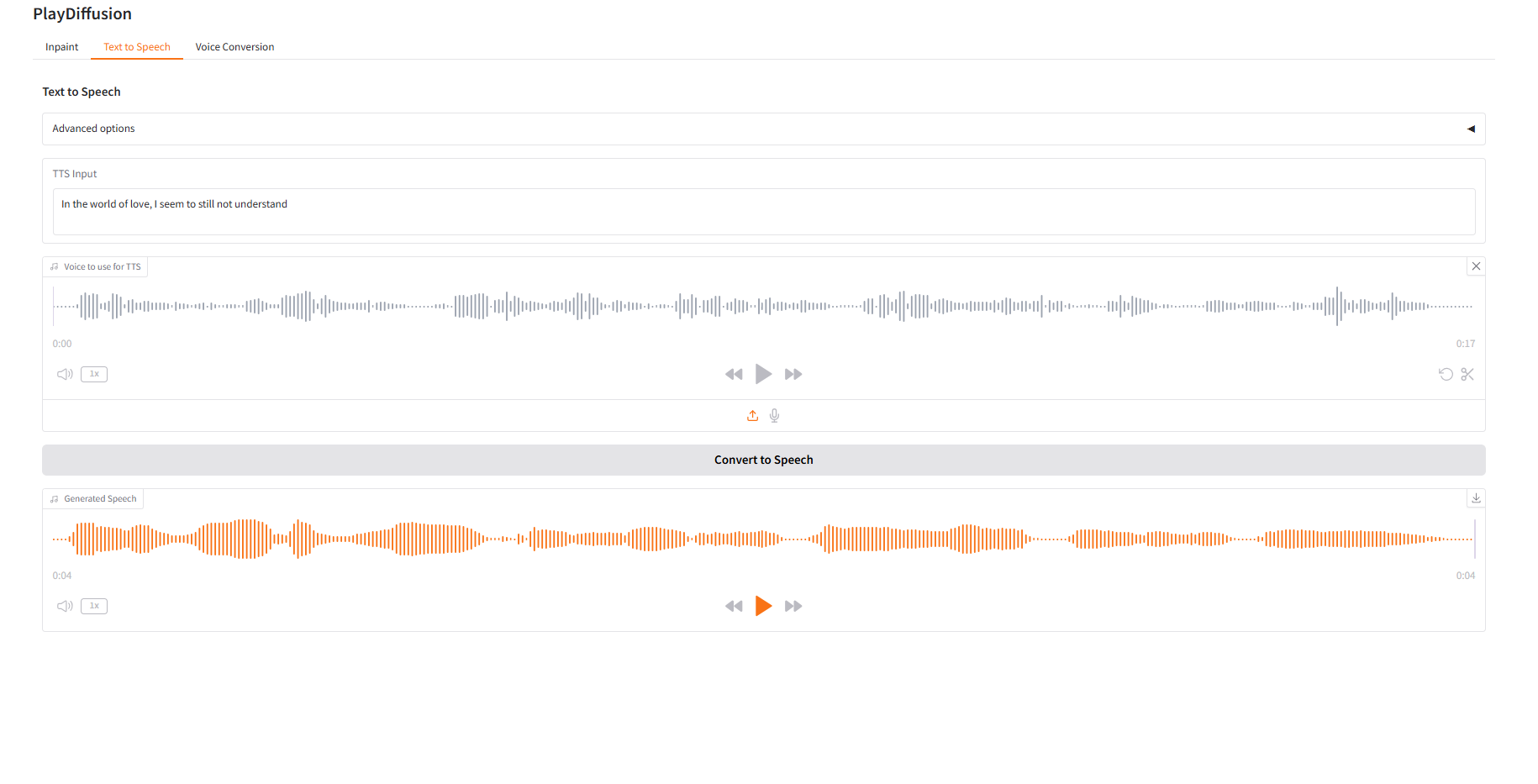
2. Text to Speech
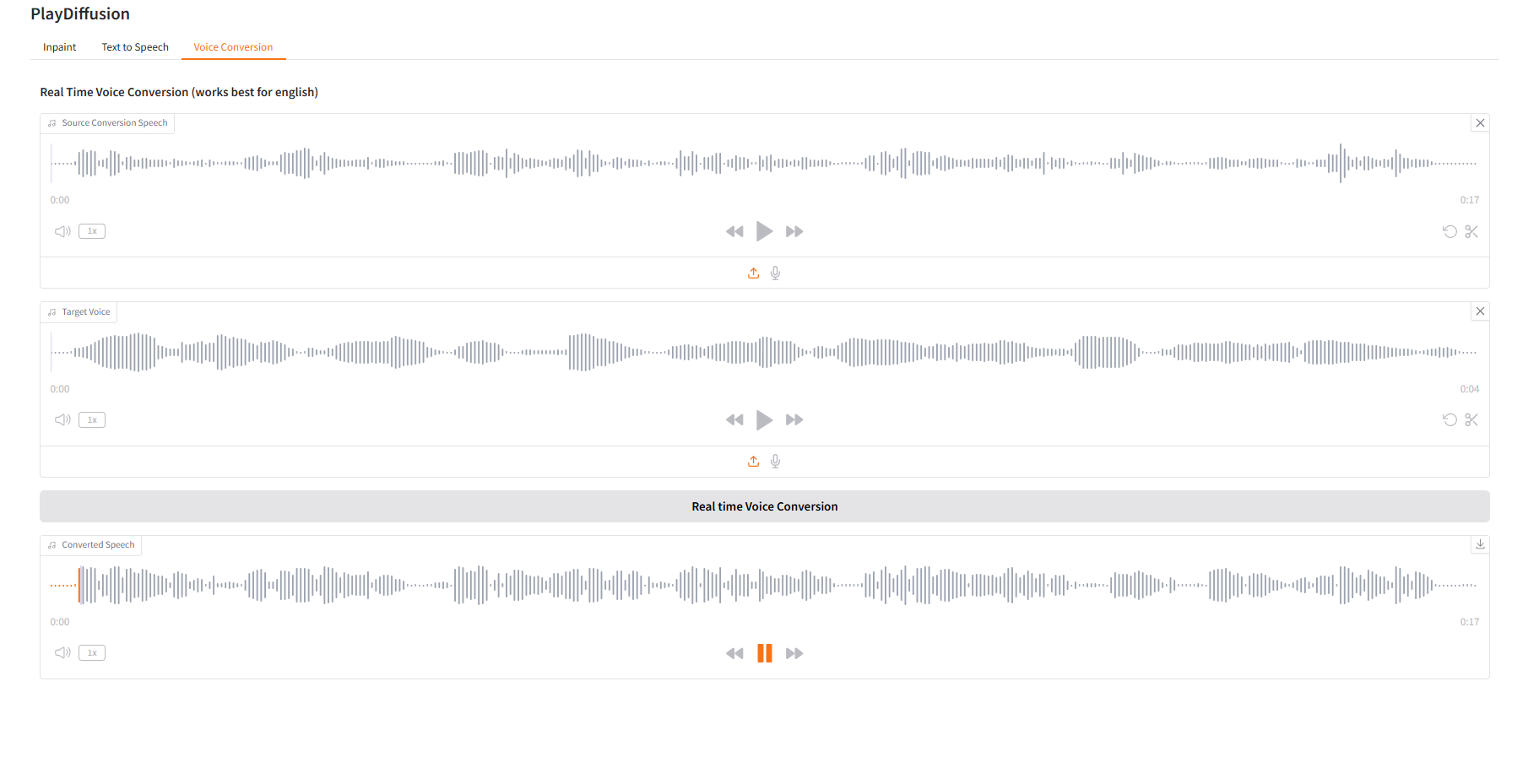
3. Voice Conversion
三、运行步骤
1. 启动容器
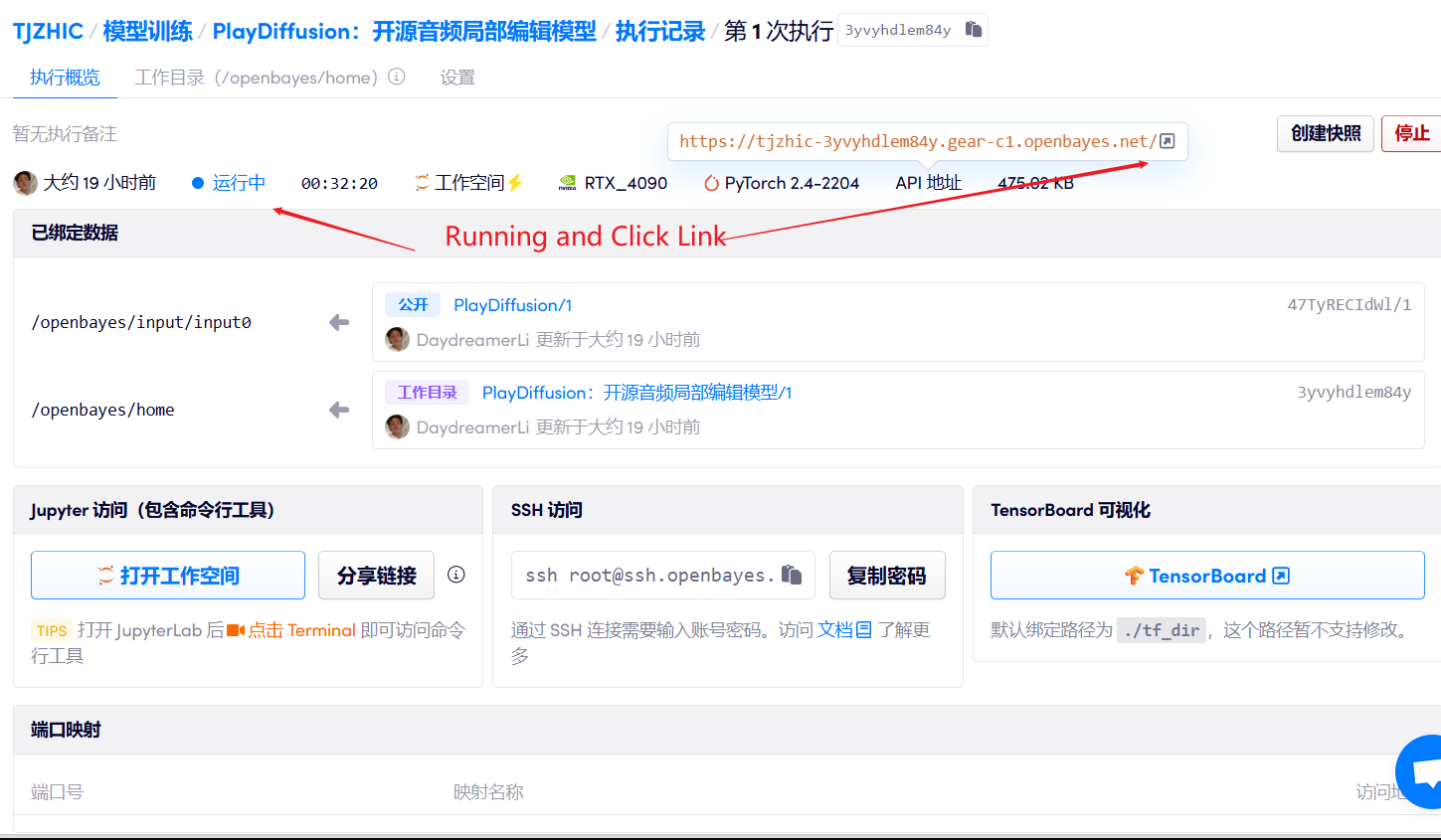
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
1. Inpaint
该模块可以将音频进行局部替换、修改或删除,无需重生成整段音频,保持语音自然、无缝衔接。
- 上传原始音频,点击「Run SAR」运行后,在「Desired output text」处修改编辑想要输出的音频内容。
- 再点击「Run Inpainter」,即可生成编辑后的音频。
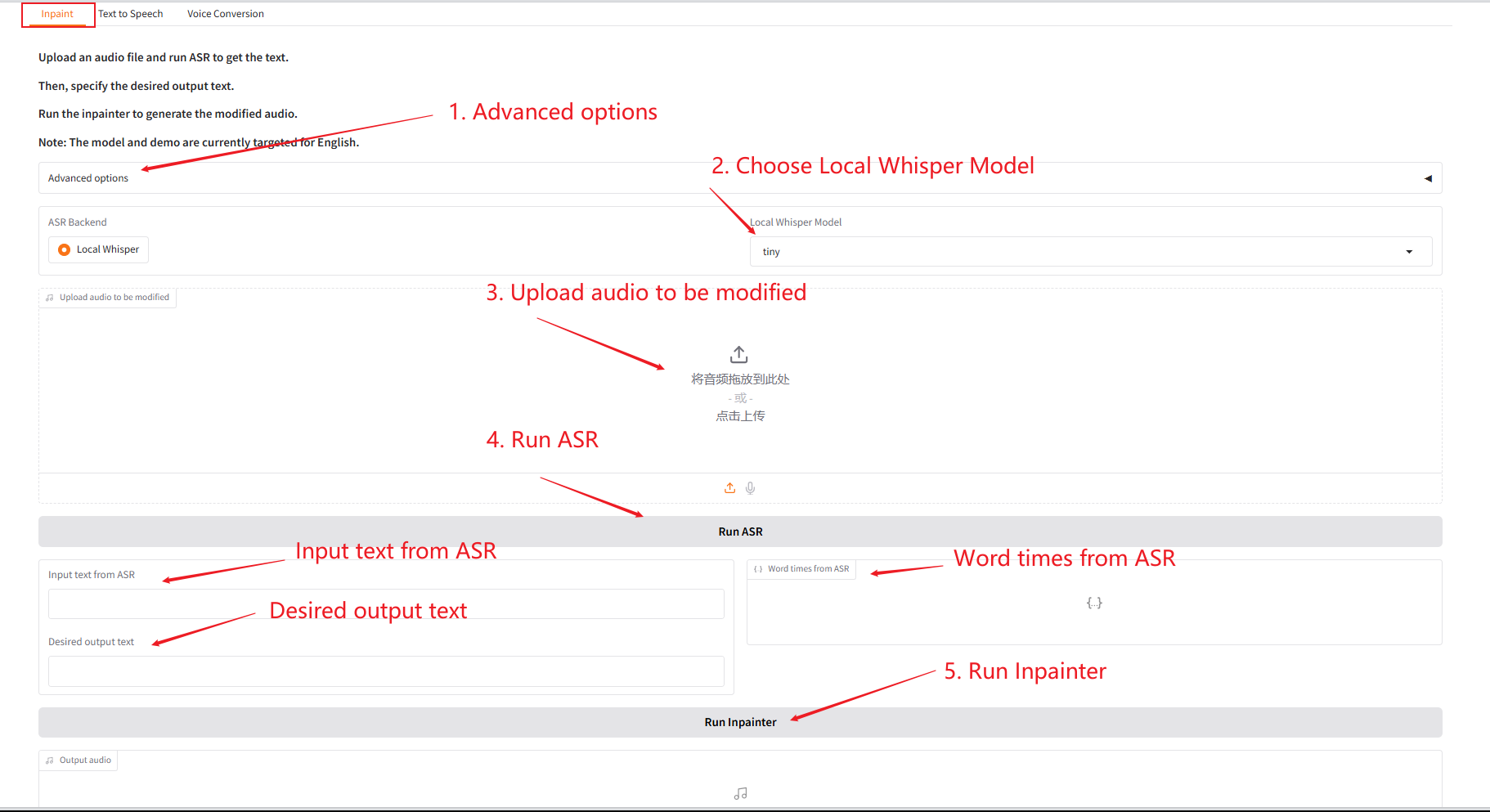
参数说明:
- Number of sampling steps:扩散模型生成过程中的迭代次数,步数越多生成质量越高但耗时越长。
- Codebook:向量量化层中的离散符号字典,用于将连续特征映射为离散表示。
- Initial temperature:控制采样随机性的参数,值越高多样性越强,值越低结果越确定。
- Initial diversity:控制生成样本变异程度的参数,避免生成结果过于相似。
- Guidance :调节条件信息(如文本)对生成结果的影响程度。
- Guidance rescale factor:用于平衡条件引导和无条件生成的权重比例。
- Sampling from top-k logits:仅从概率最高的 K 个候选中选择,提高生成质量。
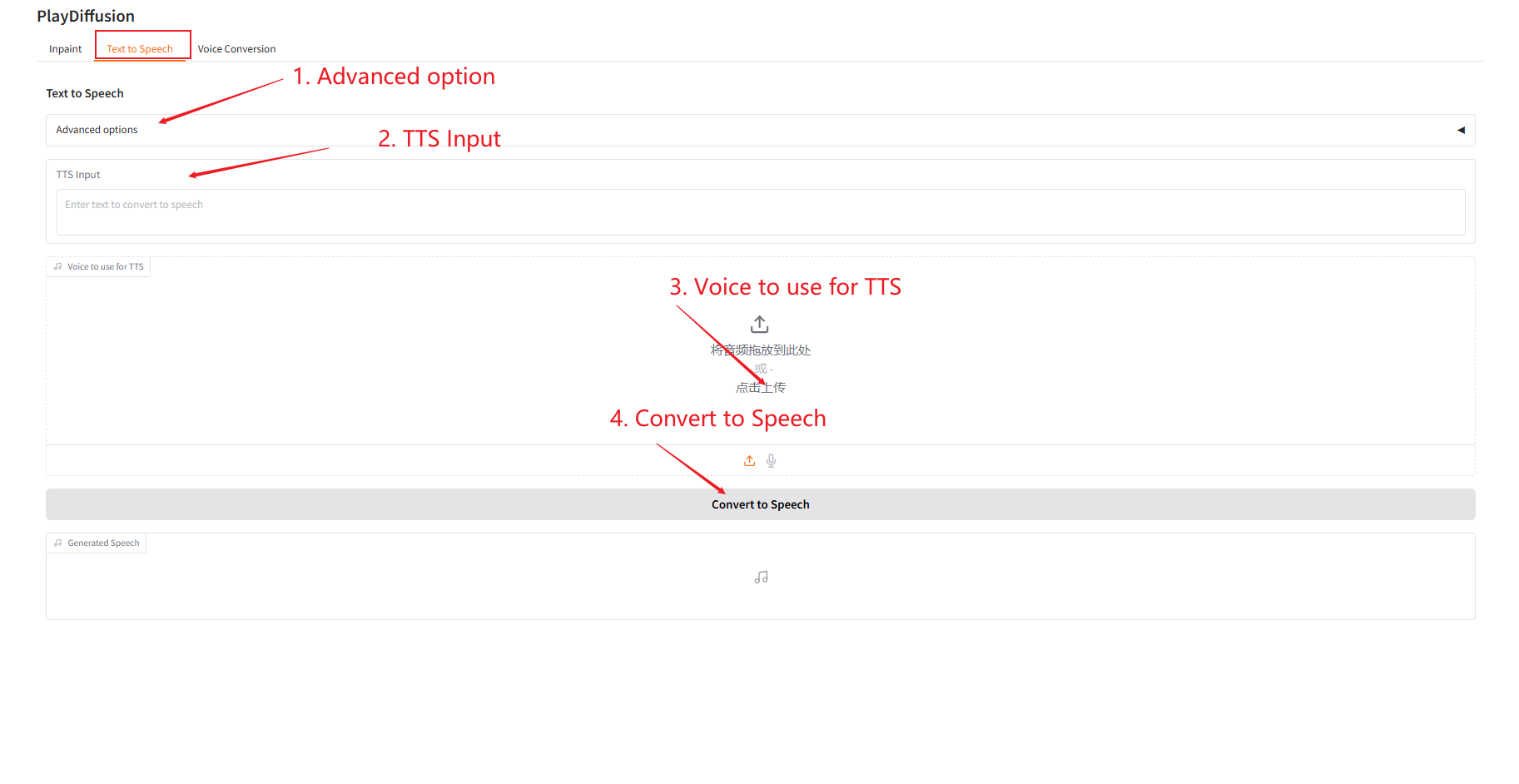
2. Text to Speech
作为高效 TTS 模型,推理速度比传统 TTS 提高 50 倍,语音自然度和一致性更优。
- 在「TTS Input」中输入想要生成音频的文本内容,然后上传目标音频。
- 再点击「Convert to Speech」,即可生成音频。
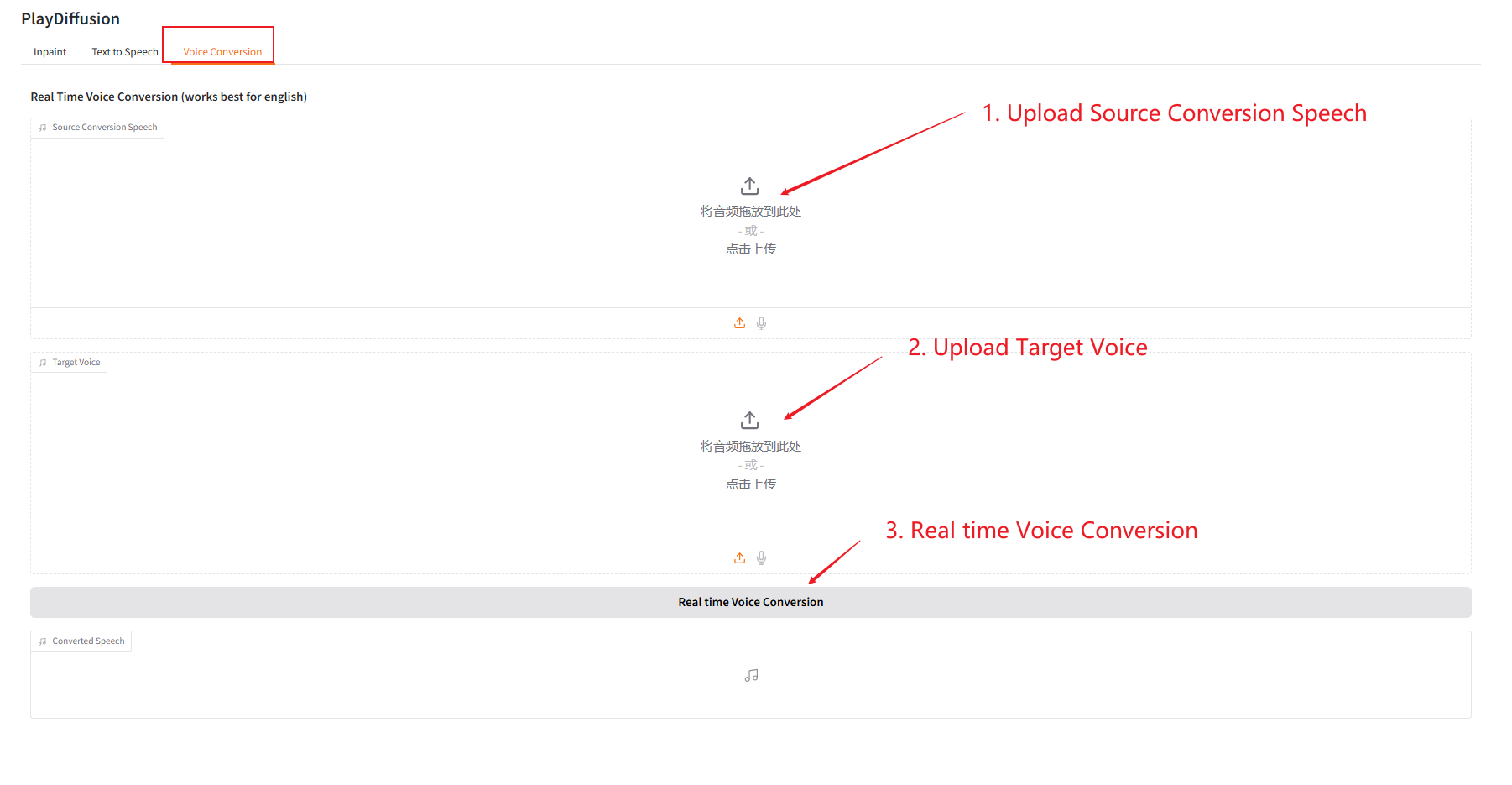
3. Voice Conversion
动态调整语音内容,可以直接将原始音频内容克隆到目标音色。
- 上传原始音频,然后上传目标音色音频。
- 再点击「Real time Voice Conversion」,即可直接生成目标音色的原音频内容。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。