Command Palette
Search for a command to run...
MAGI-1:全球首个自回归视频生成大模型
一、教程简介

Magi-1 是由中国人工智能公司 Send AI 于 2025 年 4 月 21 日正式发布开发的全球首个自回归视频生成大模型,通过自回归预测一系列视频块来生成视频,定义为连续帧的固定长度片段。 MAGI-1 经过训练,可以对随时间单调增加的每块噪声进行降噪,支持因果时间建模,并自然支持流式生成。它在以文本指令为条件的图像到视频任务上实现了强大的性能,提供了高度的时间一致性和可扩展性,这可以通过多项算法创新和专用基础设施堆栈实现。相关论文成果为 MAGI-1: Autoregressive Video Generation at Scale 。
本教程采用资源为单卡 RTX 4090,文本仅支持英文。
二、项目示例
Text to Video 模式
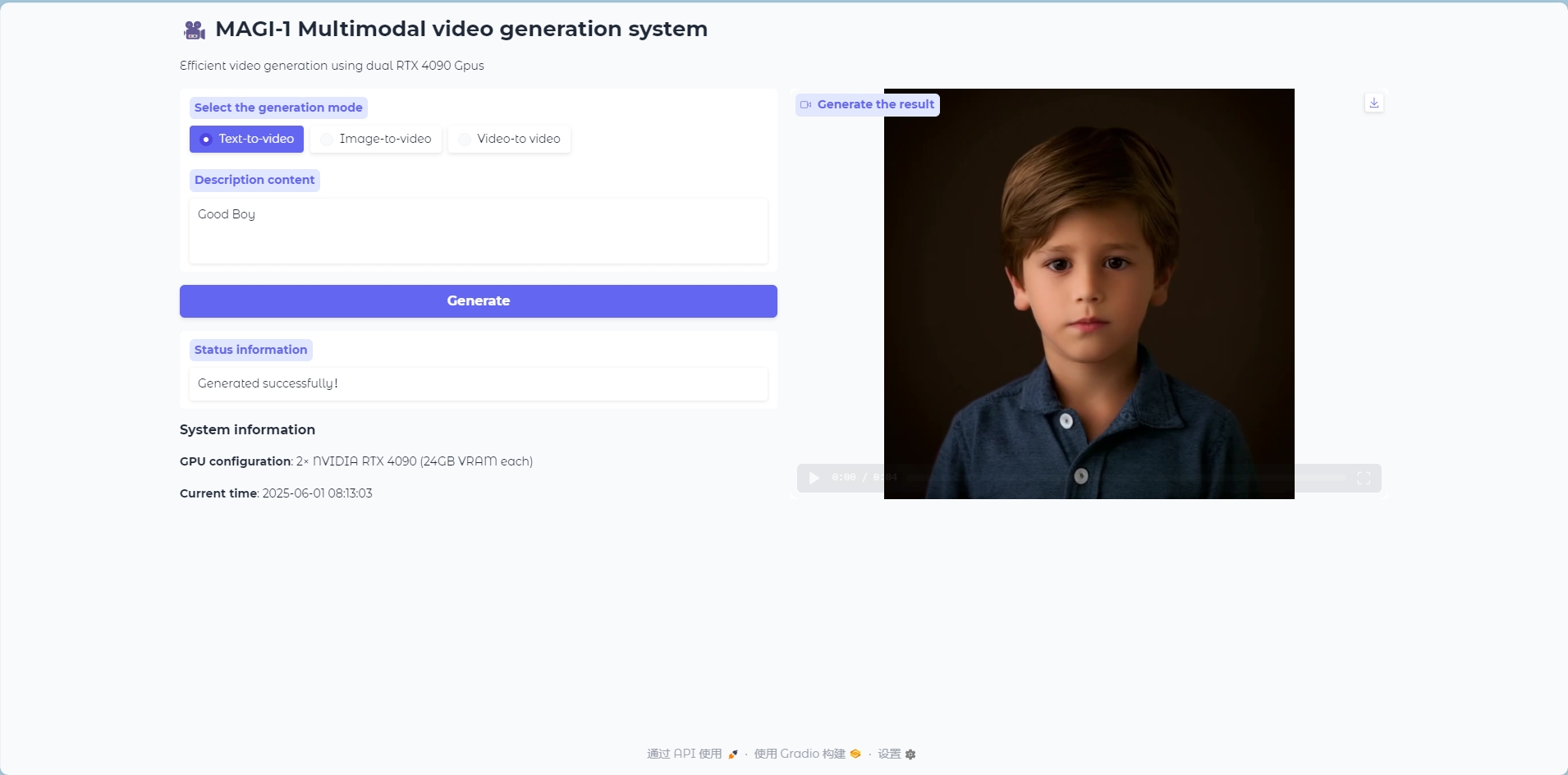
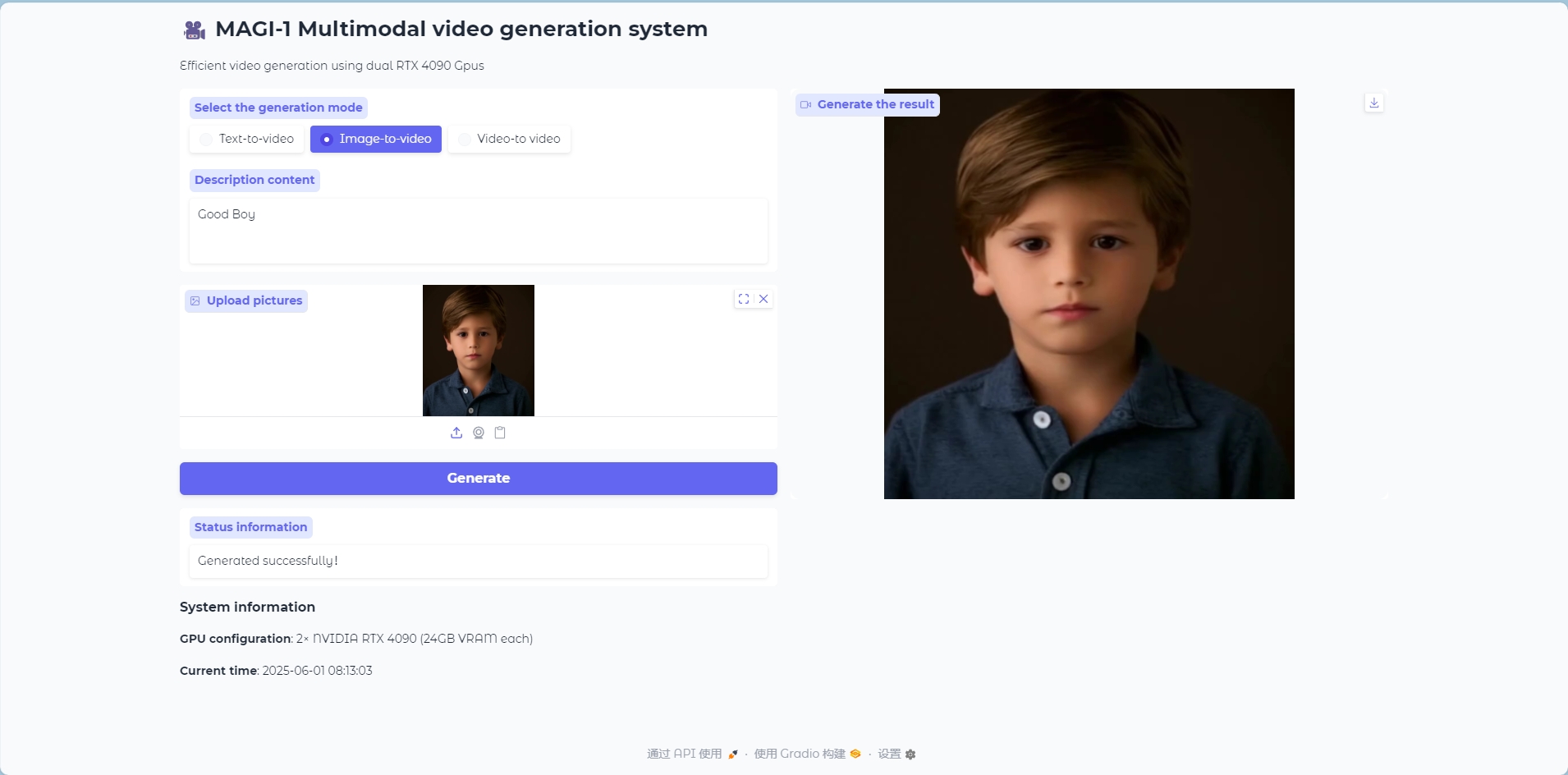
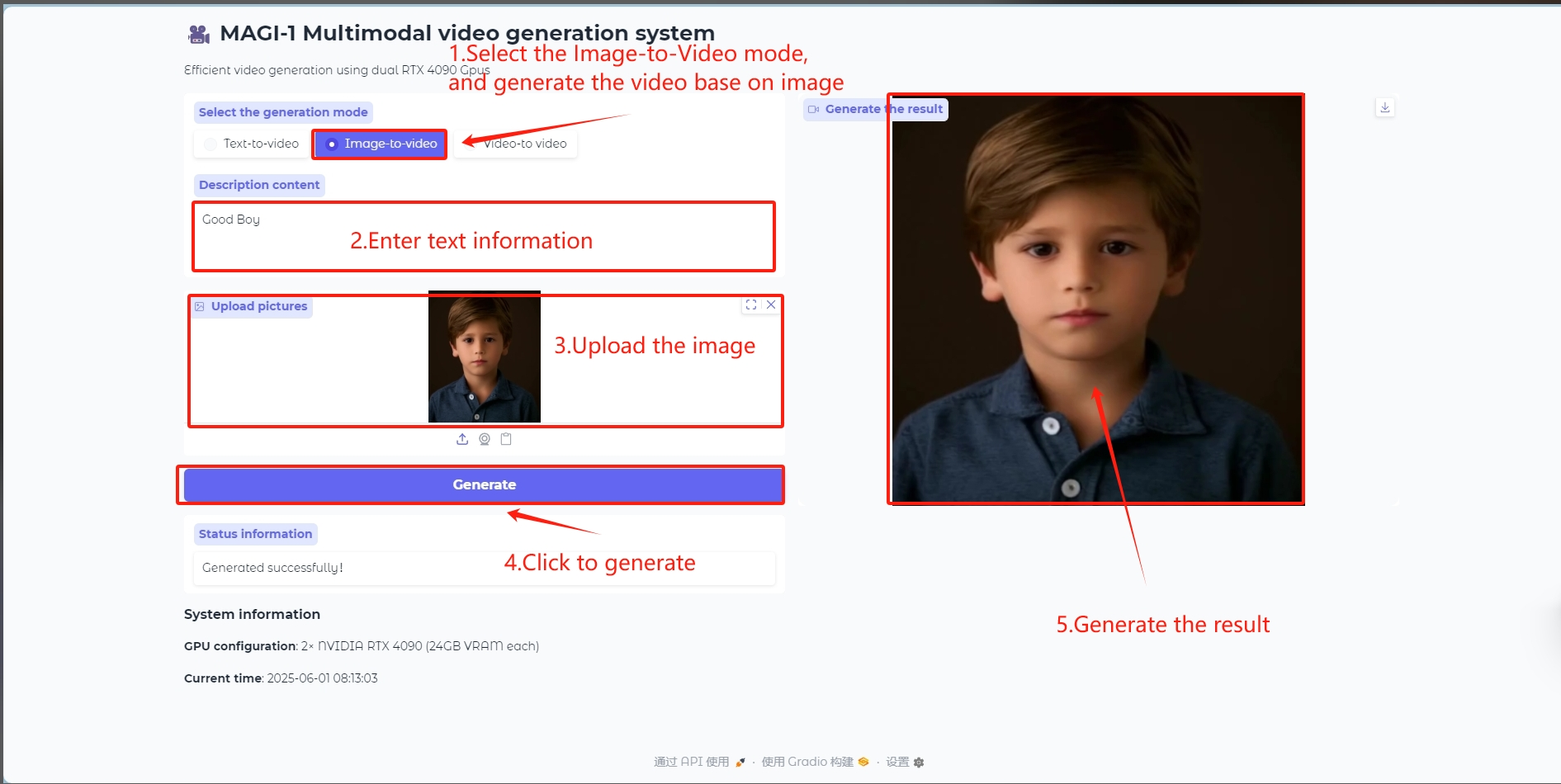
Image to Video 模式
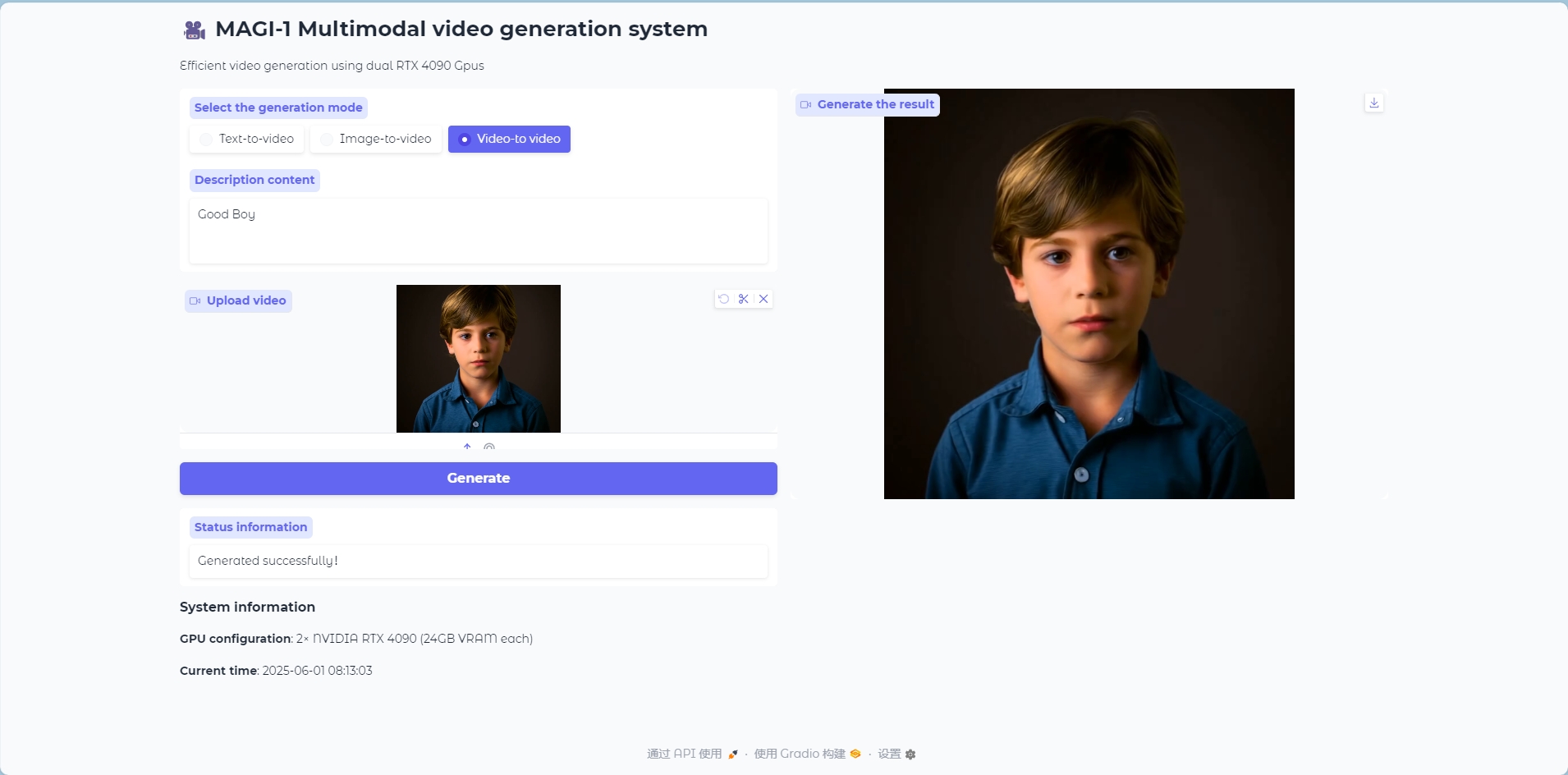
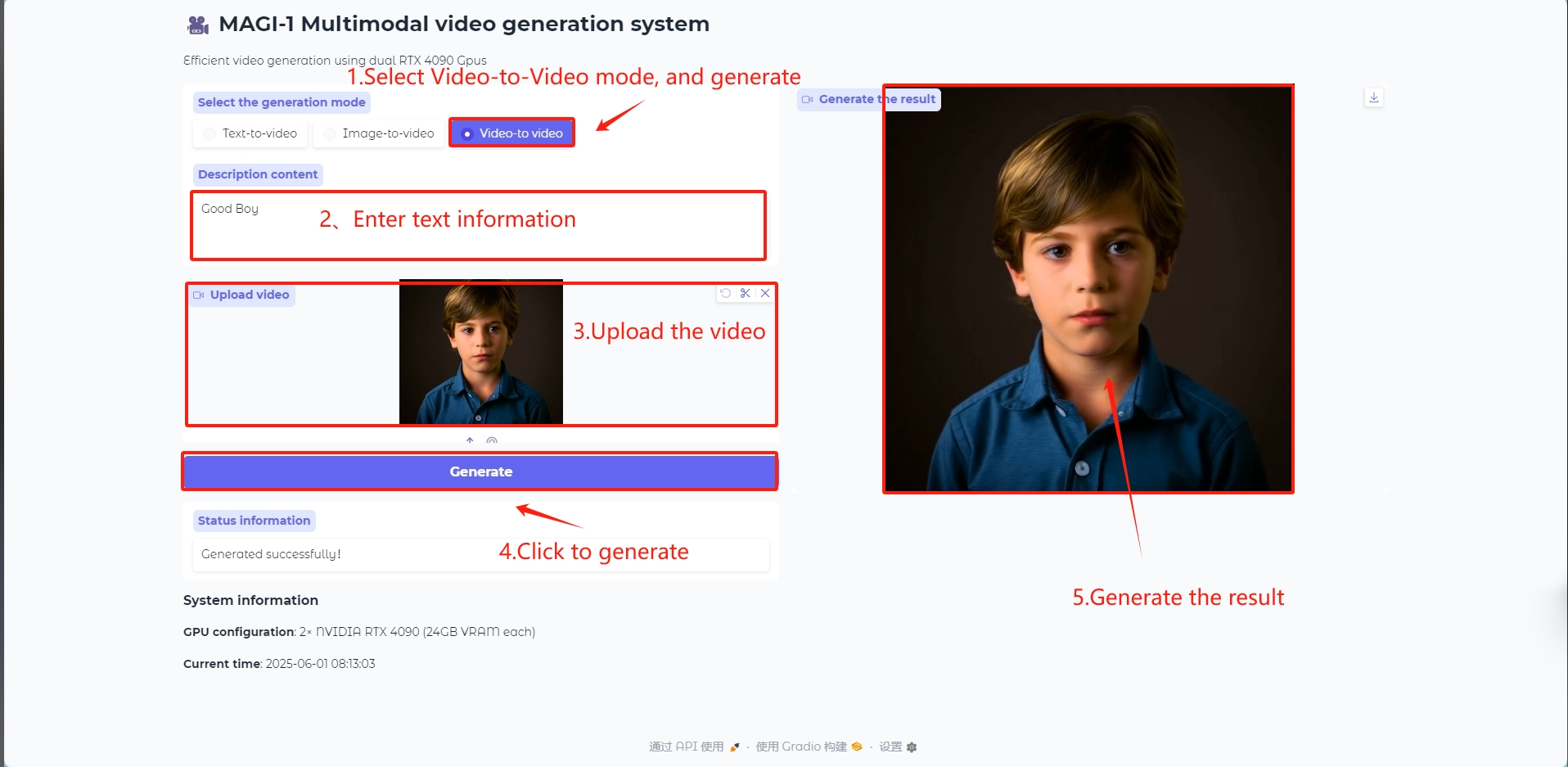
Video to Video 模式
三、运行步骤
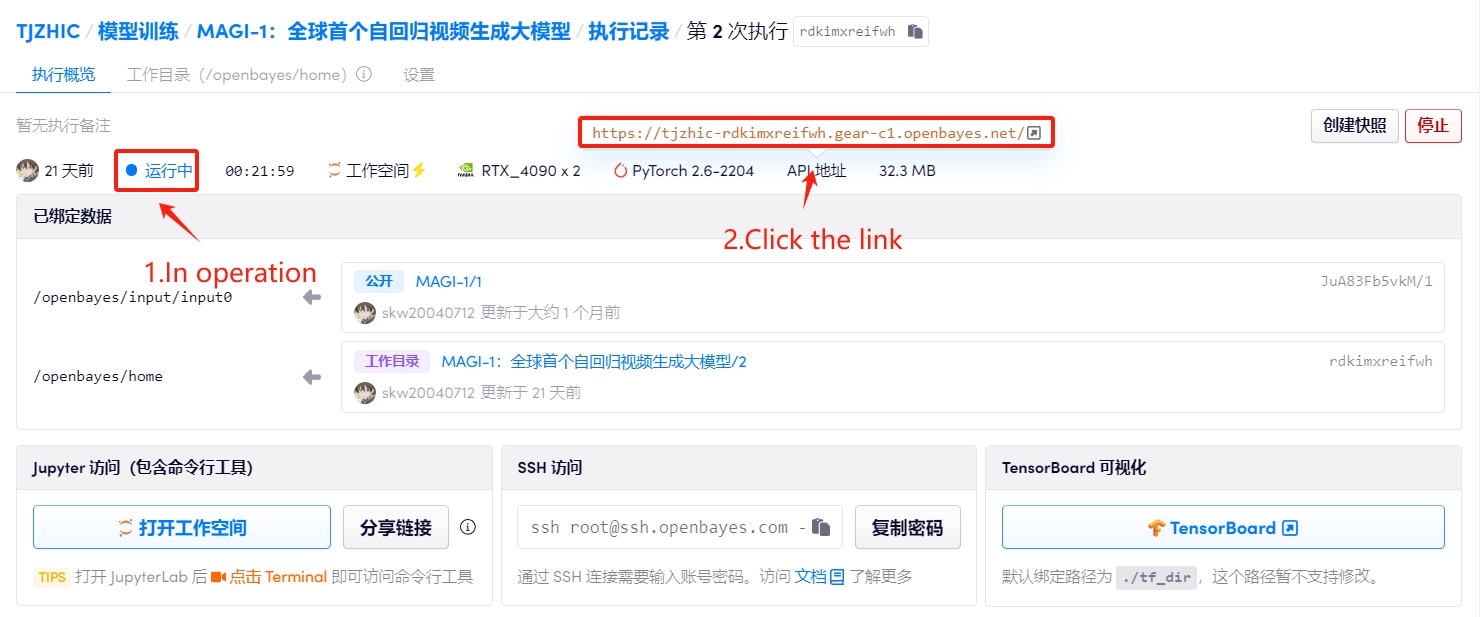
1. 启动容器后点击 API 地址即可进入 Web 界面
2. 进入网页后,即可与模型展开语言对话
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待 1-2 分钟后刷新页面,该模型生成视频需五分钟左右,请耐心等待。
使用步骤
Text to Video 模型
以文本内容生成视频帧
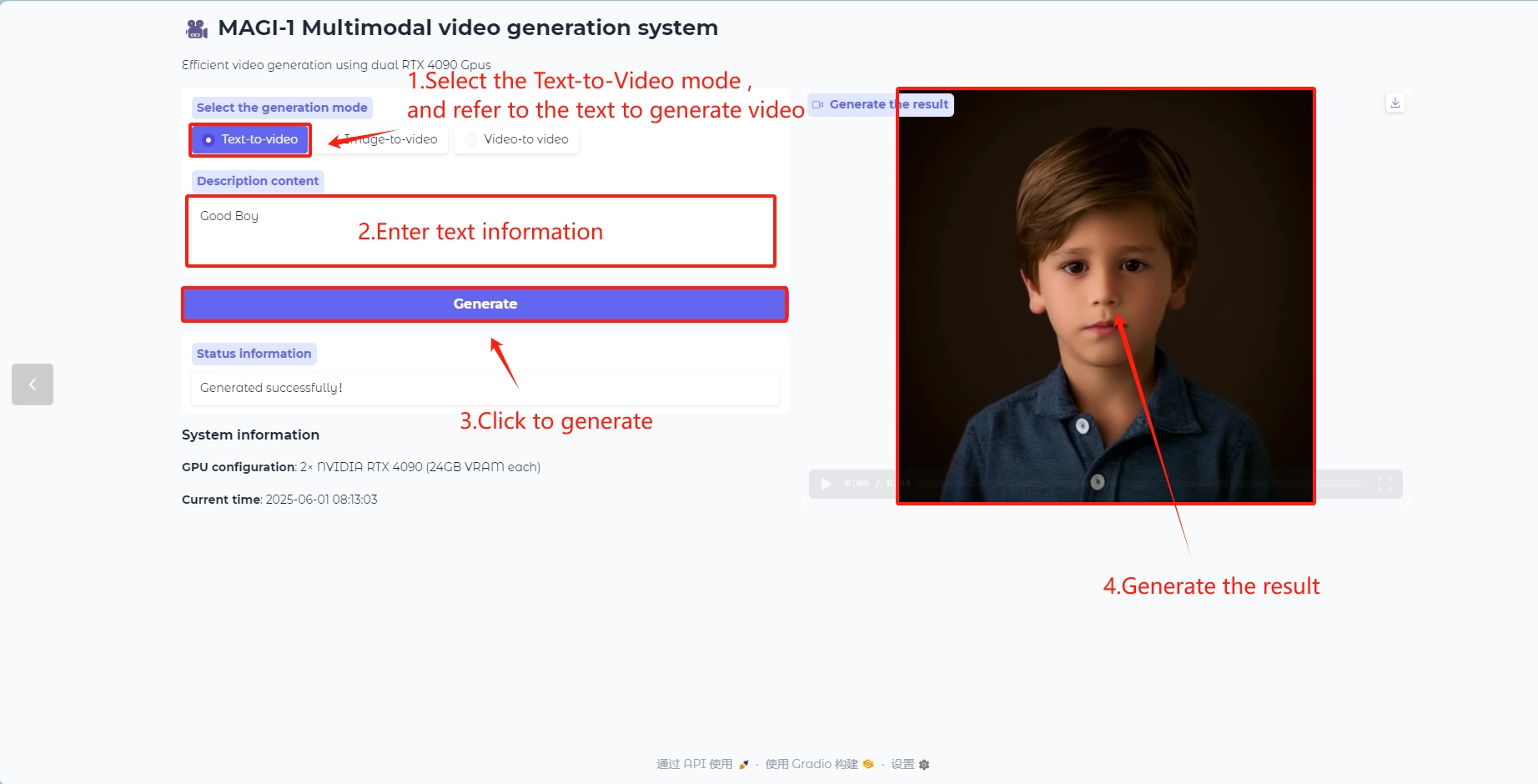
Image to Video 模型
输入一张图像作为参考生成视频帧
Video to Video 模型
输入一个视频作为参考生成视频帧
在 /openbayes/home/MAGI-1/example/4.5B 路径下的 4.5B_distill_quant_config.json 文件中的 runtime_config 下,可以更改生成视频的 num_frames 、 video_size_h 、 video_size_w 以及 fps 等参数。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

五、引用信息
感谢 GitHub 用户 kjasdkj 对本教程的部署,本项目引用信息如下:
@misc{ai2025magi1autoregressivevideogeneration,
title={MAGI-1: Autoregressive Video Generation at Scale},
author={Sand. ai and Hansi Teng and Hongyu Jia and Lei Sun and Lingzhi Li and Maolin Li and Mingqiu Tang and Shuai Han and Tianning Zhang and W. Q. Zhang and Weifeng Luo and Xiaoyang Kang and Yuchen Sun and Yue Cao and Yunpeng Huang and Yutong Lin and Yuxin Fang and Zewei Tao and Zheng Zhang and Zhongshu Wang and Zixun Liu and Dai Shi and Guoli Su and Hanwen Sun and Hong Pan and Jie Wang and Jiexin Sheng and Min Cui and Min Hu and Ming Yan and Shucheng Yin and Siran Zhang and Tingting Liu and Xianping Yin and Xiaoyu Yang and Xin Song and Xuan Hu and Yankai Zhang and Yuqiao Li},
year={2025},
eprint={2505.13211},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.13211},
}