HyperAI
Command Palette
Search for a command to run...
VIRES:草图与文本双引导的视频重绘
一、教程简介

VIRES 是由北京大学相机智能实验室(施柏鑫团队)联合 OpenBayes 贝式计算,以及北京邮电大学人工智能学院模式识别实验室李思副教授团队,于 2025 年共同提出的一种结合草图与文本引导的视频实例重绘方法,支持对视频主体的重绘、替换、生成与移除等多种编辑操作。该方法利用文本生成视频模型的先验知识,确保时间上的一致性,同时还提出了带有标准化自适应缩放机制的 Sequential ControlNet,能够有效提取结构布局并自适应捕捉高对比度的草图细节。更进一步地,研究团队在 DiT(diffusion transformer)backbone 中引入草图注意力机制,以解读并注入细颗粒度的草图语义。实验结果表明,VIRES 在视频质量、时间一致性、条件对齐和用户评分等多方面均优于现有 SOTA 模型。
相关研究以 VIRES: Video Instance Repainting via Sketch and Text Guided Generation 为题,已入选 CVPR 2025 。
本教程采用资源为单卡 A6000 。
二、项目示例

三、运行步骤
1. 启动容器后点击 API 地址即可进入 Web 界面

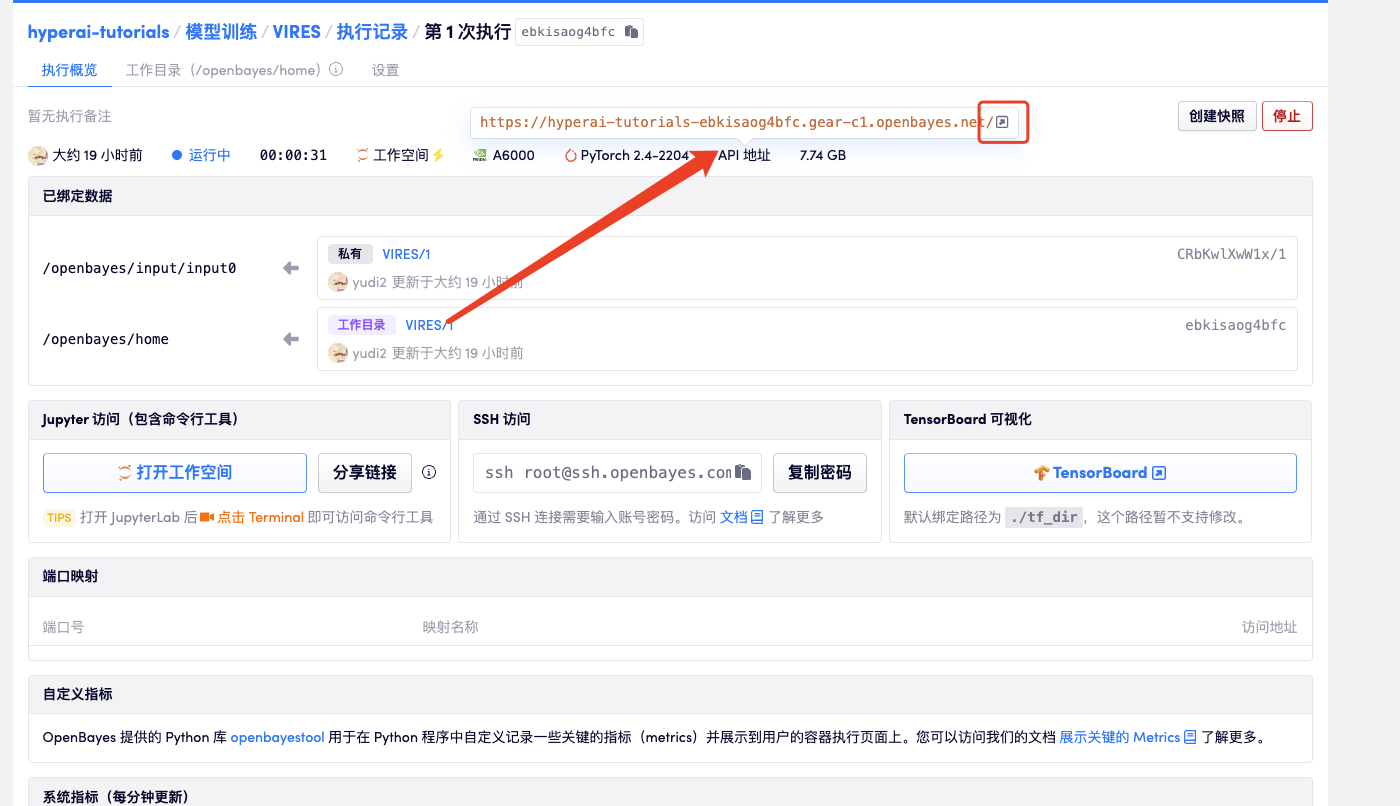
2. 进入网页后,即可使用模型
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
使用步骤
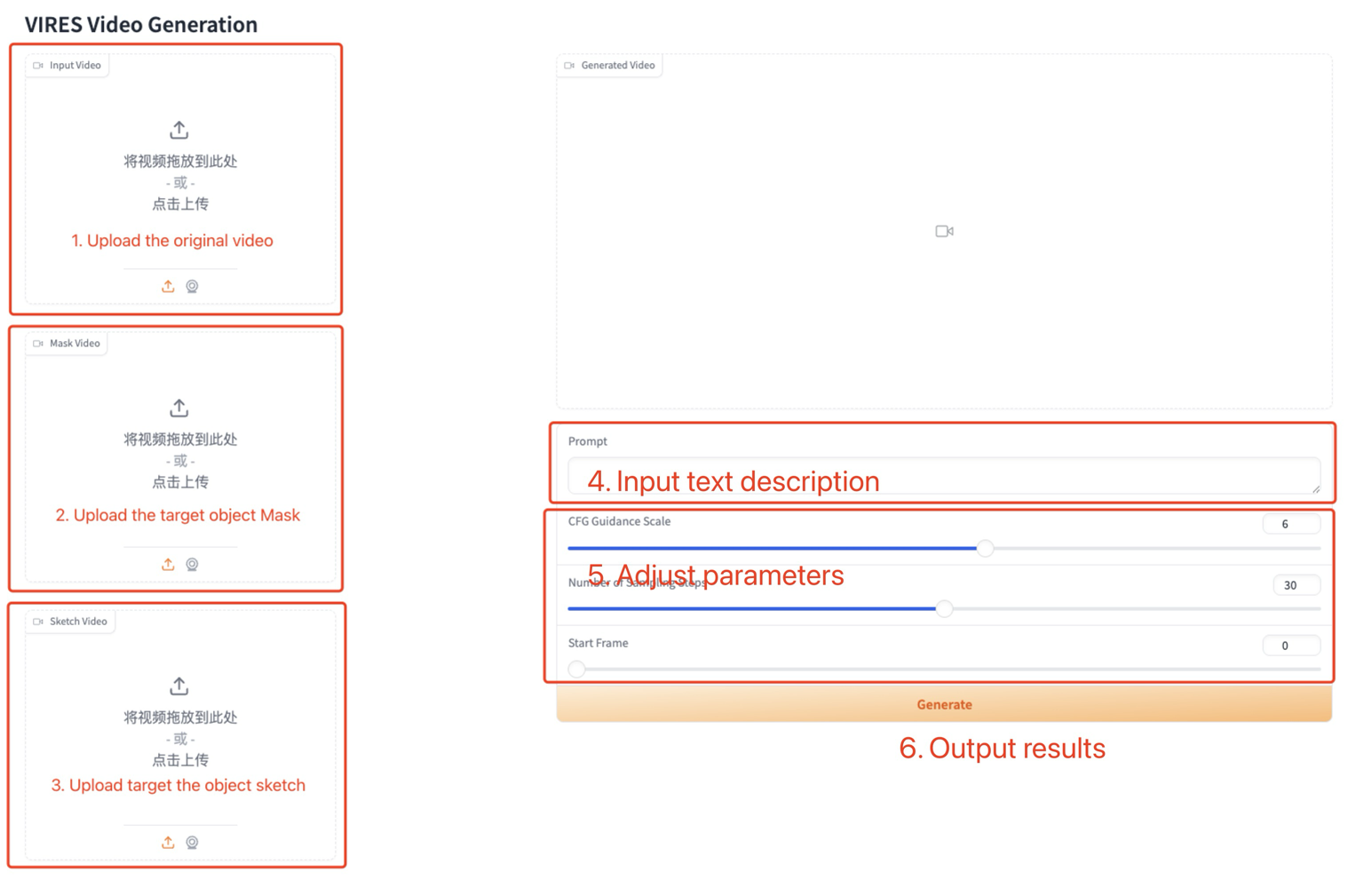
参数说明:
- CFG Guidance Scale:无条件引导强度。
- Number of Sampling Steps:采样步数。
- Start Frame:编辑起始帧。
引用信息
@article{vires,
title={VIRES: Video Instance Repainting via Sketch and Text Guided Generation},
author={Weng, Shuchen and Zheng, Haojie and Zhang, Peixuan and Hong, Yuchen and Jiang, Han and Li, Si and Shi, Boxin},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={28416--28425},
year={2025}
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。