HyperAI
Command Palette
Search for a command to run...
一键部署 VideoLLaMA3-7B
一、教程简介


该教程算力资源采用单卡 RTX 4090,部署的模型为 VideoLLaMA3-7B-Image,提供了视频理解和图像理解两个例子。此外还提供「单图理解」、「多图理解」、「视觉指代表达与定位」和「视频理解」4 个 notebook 的运行脚本教程。
VideoLLaMA3 是由阿里巴巴达摩院自然语言处理团队(DAMO-NLP-SG)于 2025 年 2 月开源多模态基础模型,专注于图像与视频理解任务。通过以视觉为中心的架构设计与高质量数据工程,显著提升了视频理解的精度与效率。其轻量化版本(2 B)兼顾端侧部署需求,而 7 B 模型则为研究级应用提供顶级性能。 7 B 模型在通用视频理解、时间推理、长视频分析三大任务中均达 SOTA 。相关论文成果为 VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding 。
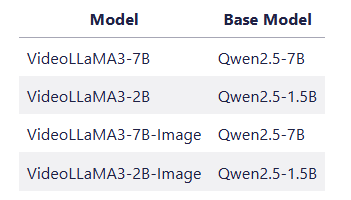
👉 该项目提供了 4 种型号的模型:
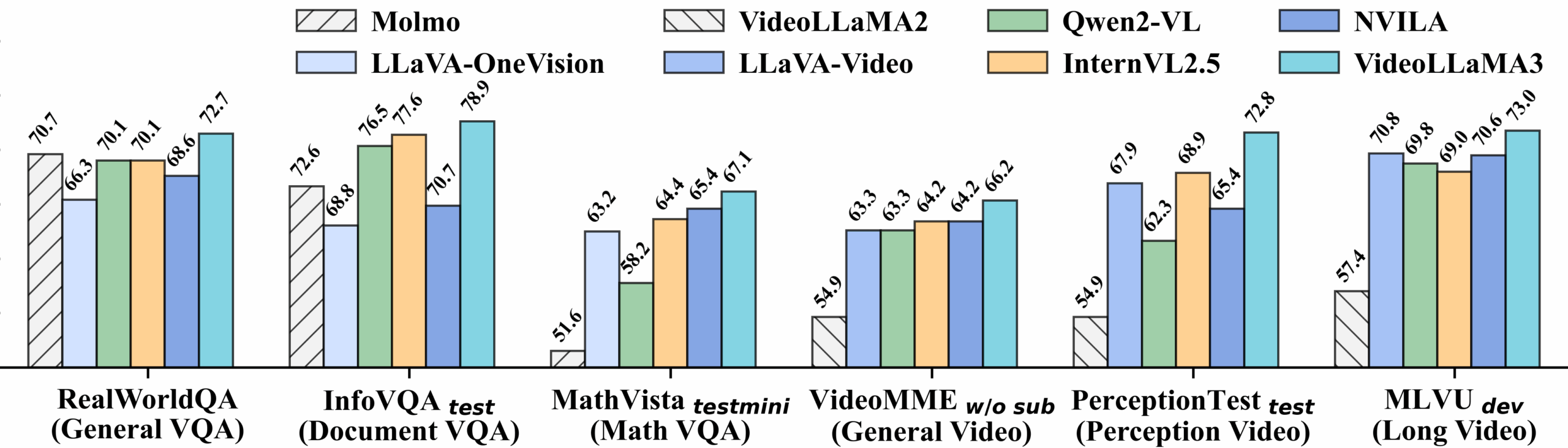
视频基准测试详细性能:
查看图像基准测试详细性能:
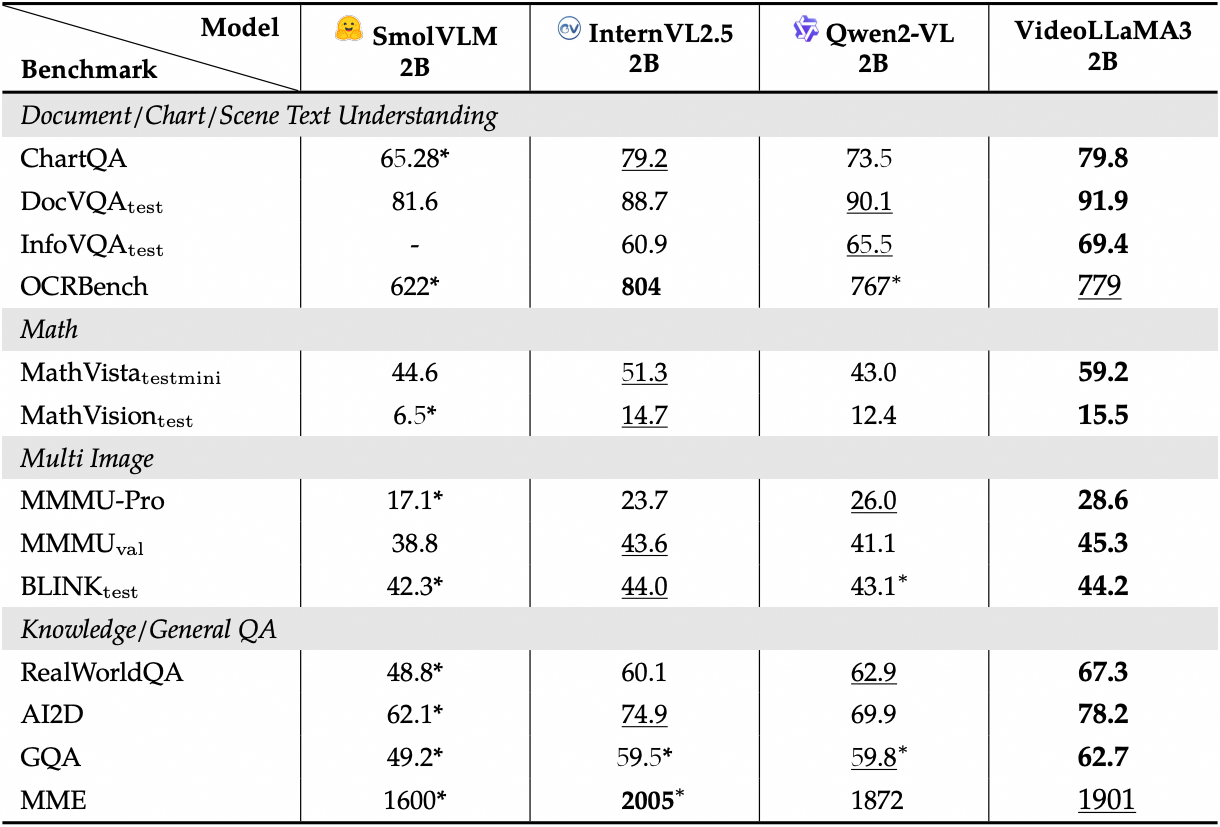
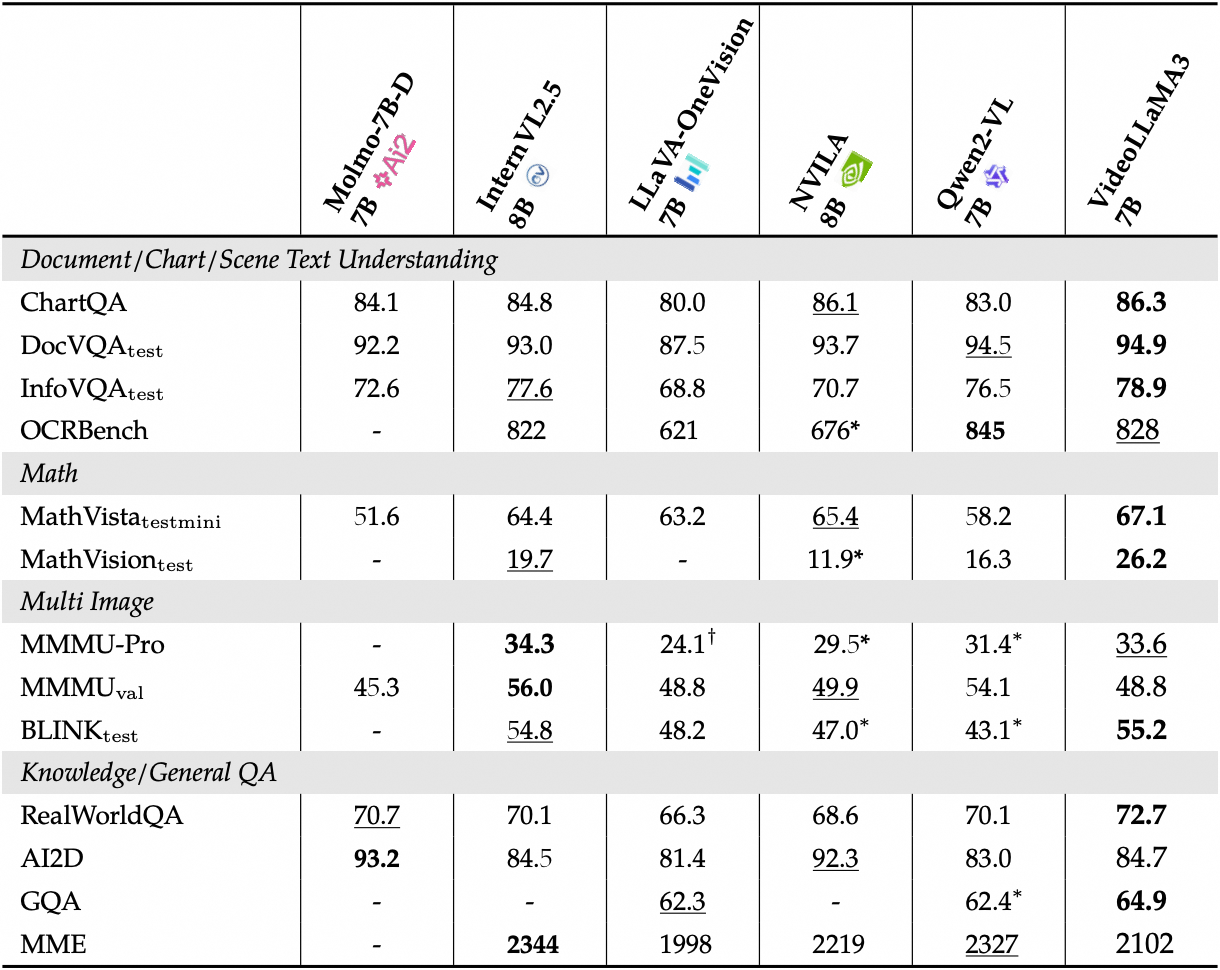
二、运行步骤
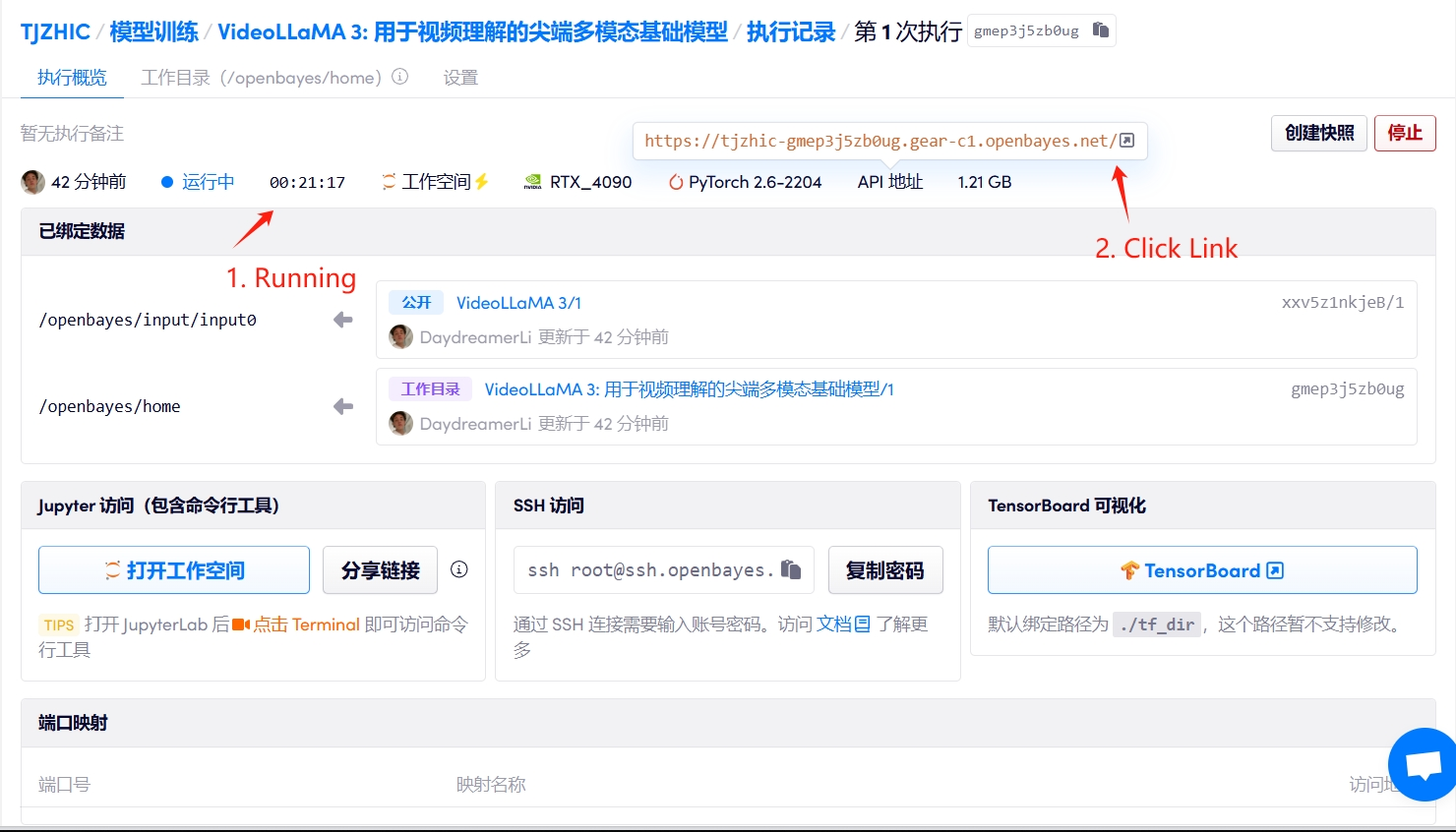
1. 启动容器
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
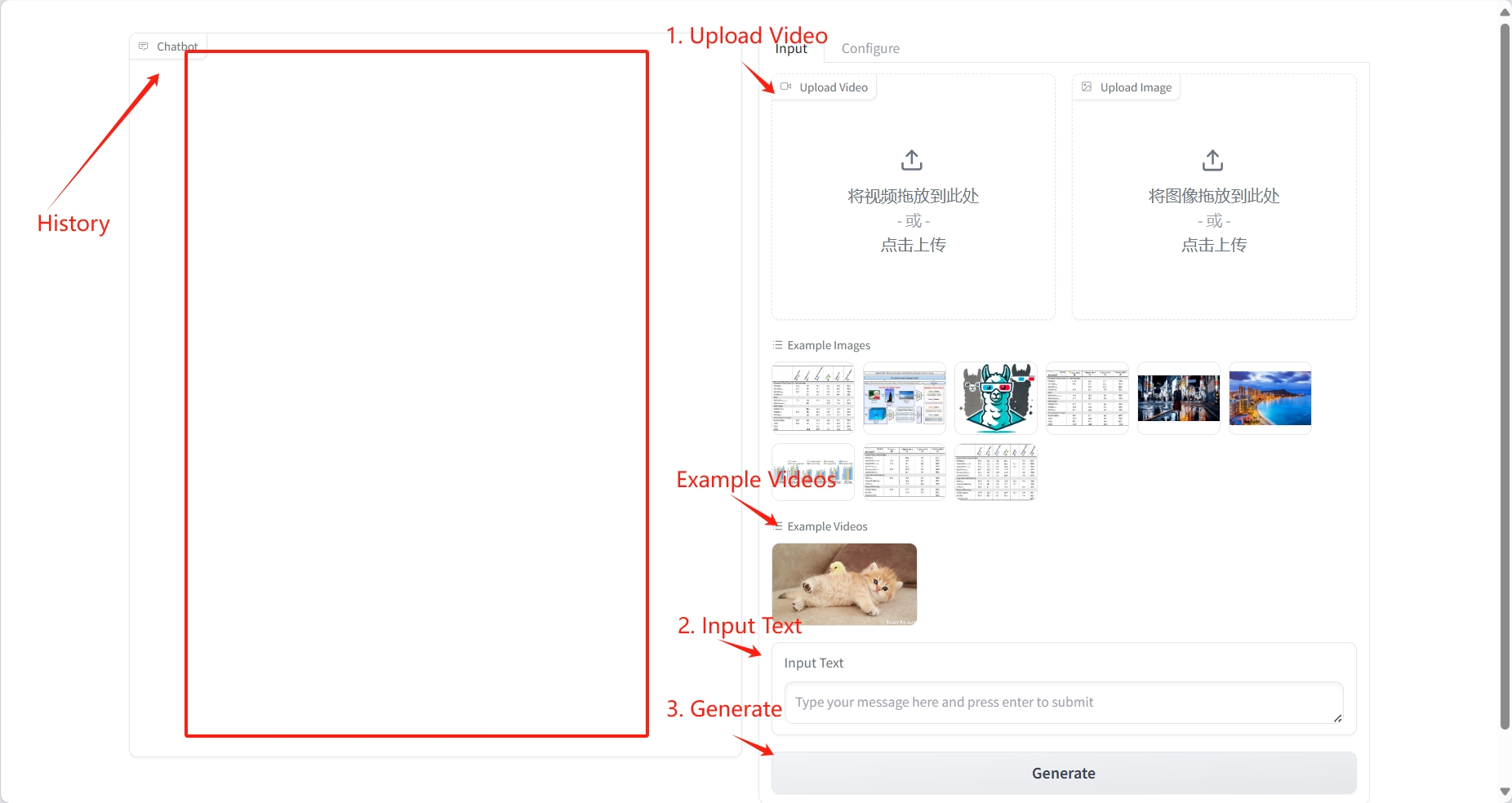
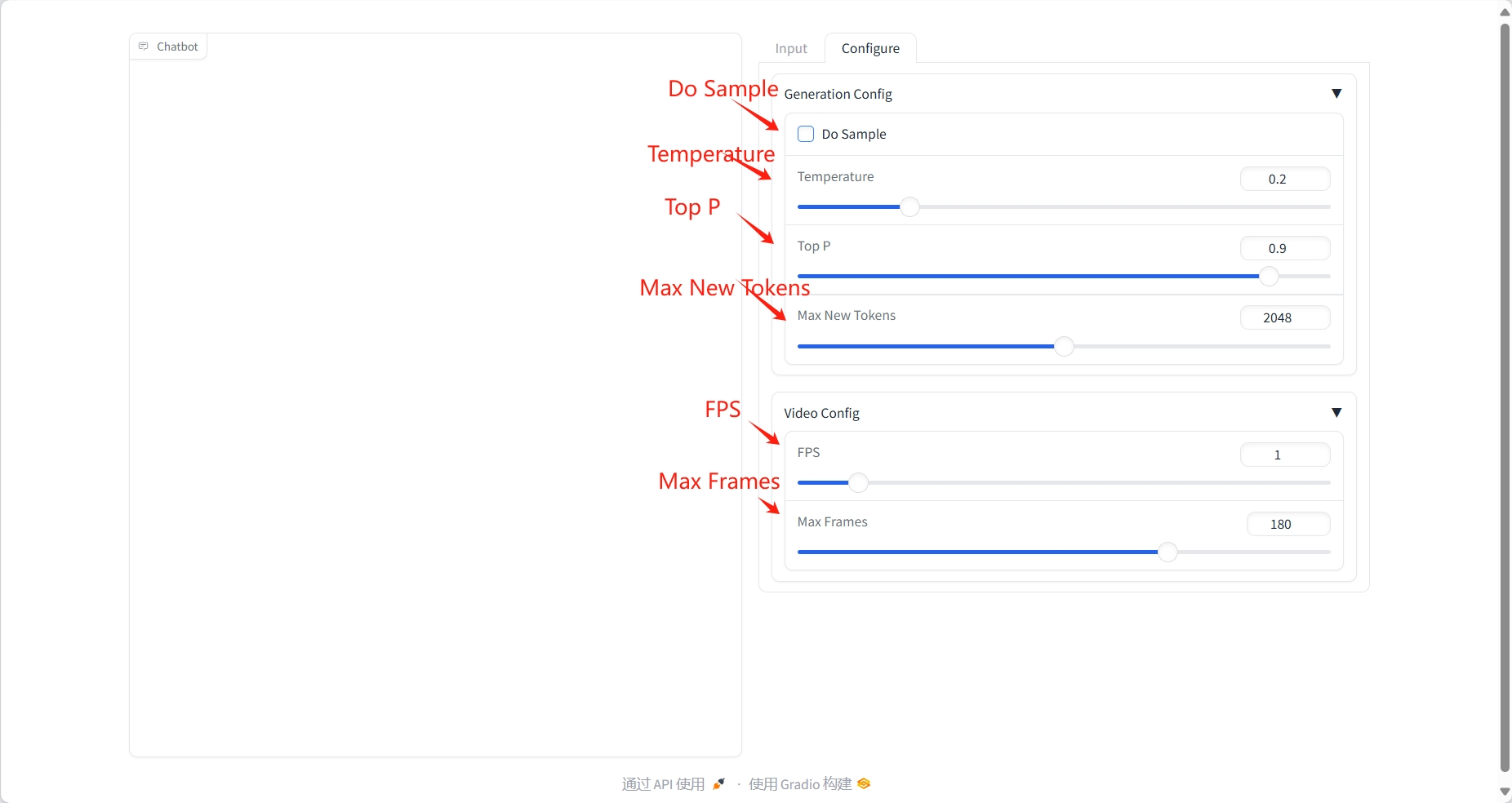
2. 使用步骤
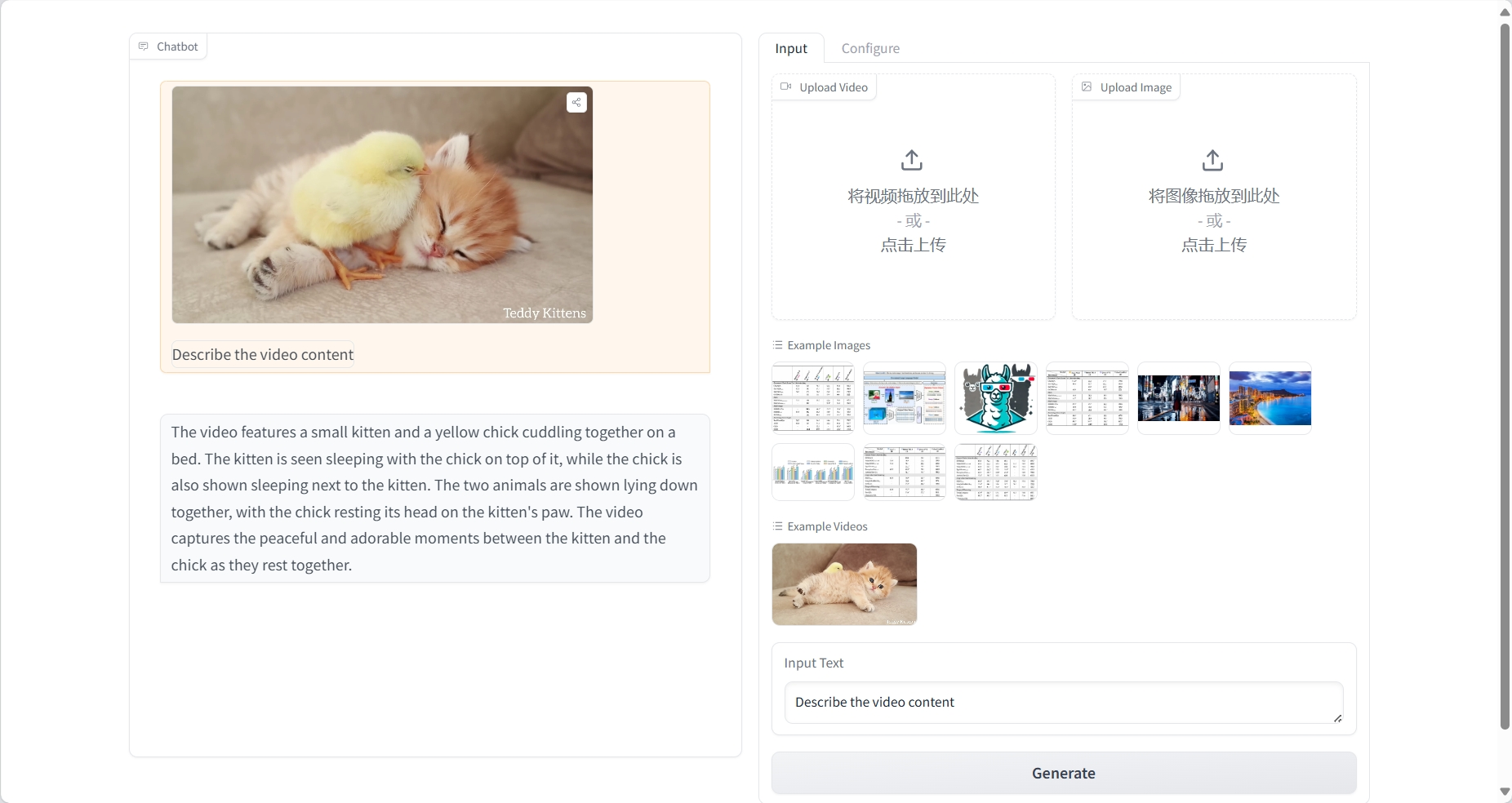
视频理解
结果
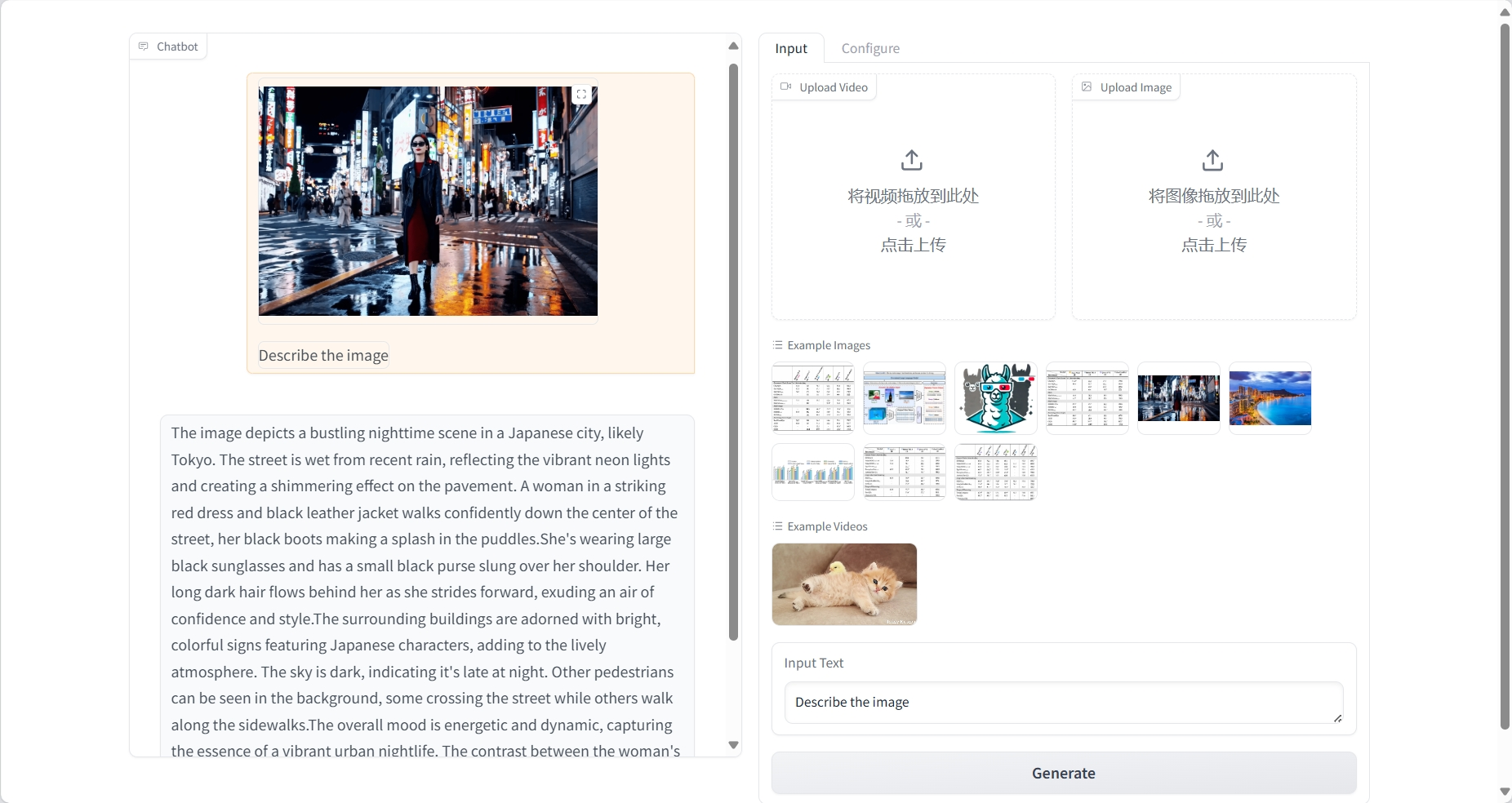
图片理解
结果
三、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@article{damonlpsg2025videollama3,
title={VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding},
author={Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao},
journal={arXiv preprint arXiv:2501.13106},
year={2025},
url = {https://arxiv.org/abs/2501.13106}
}
@article{damonlpsg2024videollama2,
title={VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs},
author={Cheng, Zesen and Leng, Sicong and Zhang, Hang and Xin, Yifei and Li, Xin and Chen, Guanzheng and Zhu, Yongxin and Zhang, Wenqi and Luo, Ziyang and Zhao, Deli and Bing, Lidong},
journal={arXiv preprint arXiv:2406.07476},
year={2024},
url = {https://arxiv.org/abs/2406.07476}
}
@article{damonlpsg2023videollama,
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
journal = {arXiv preprint arXiv:2306.02858},
year = {2023},
url = {https://arxiv.org/abs/2306.02858}
}教程预览
该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。