HyperAI
Command Palette
Search for a command to run...
Sa2VA:实现图像和视频的密集感知理解
一、教程简介

Sa2VA 由加州大学默塞德分校(UC Merced)、字节跳动 Seed 团队(ByteDance Seed)、武汉大学和北京大学的研究团队联合开发,于 2025 年 1 月 7 日发布。 Sa2VA 是第一个用于图像和视频密集感知理解的统一模型。与现有的多模态大型语言模型不同,这些模型通常仅限于特定的模态和任务,Sa2VA 支持广泛的图像和视频任务,包括指代分割和对话,只需最少的单次指令微调。相关论文成果为 Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos 。
本教程采用资源为单卡 A6000 。
二、项目示例



三、运行步骤
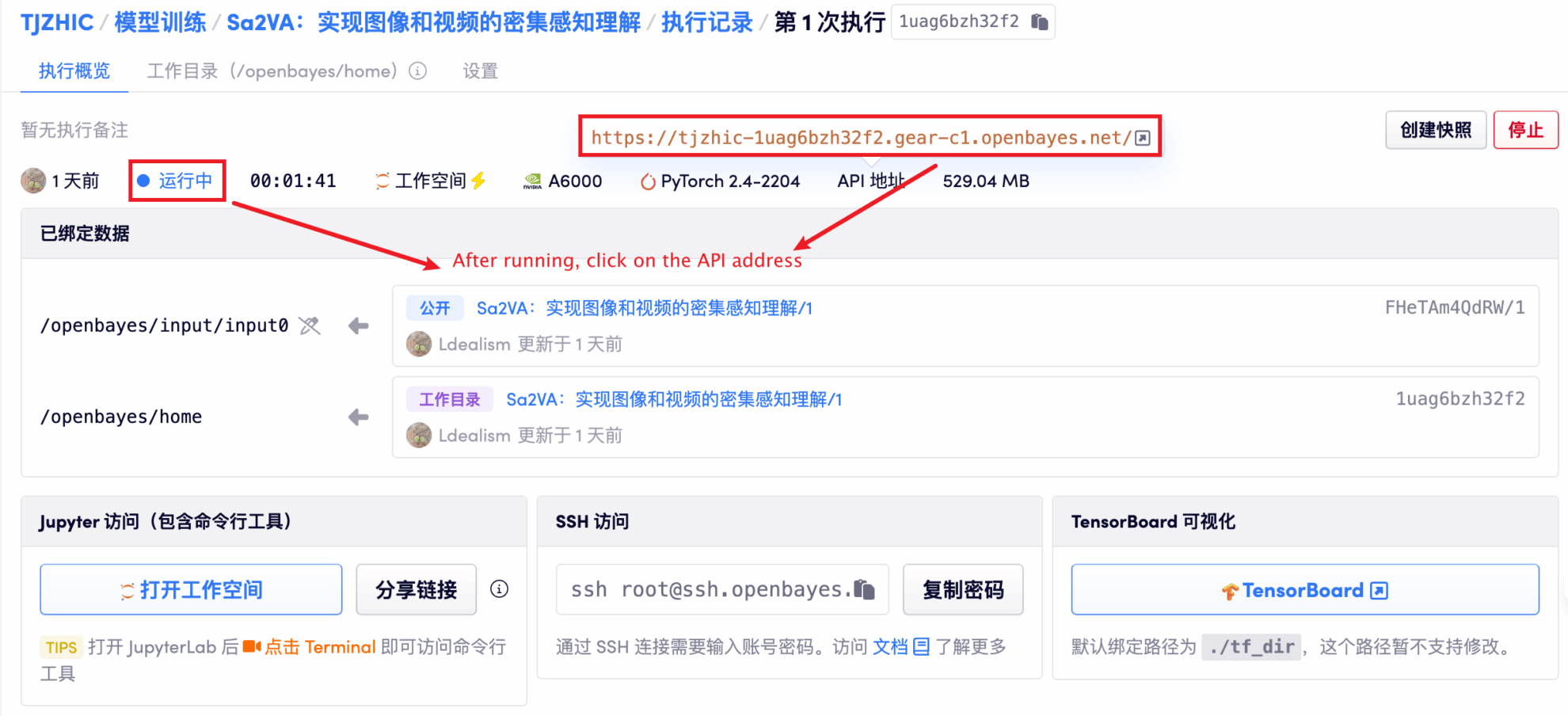
1. 启动容器后点击 API 地址即可进入 Web 界面
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
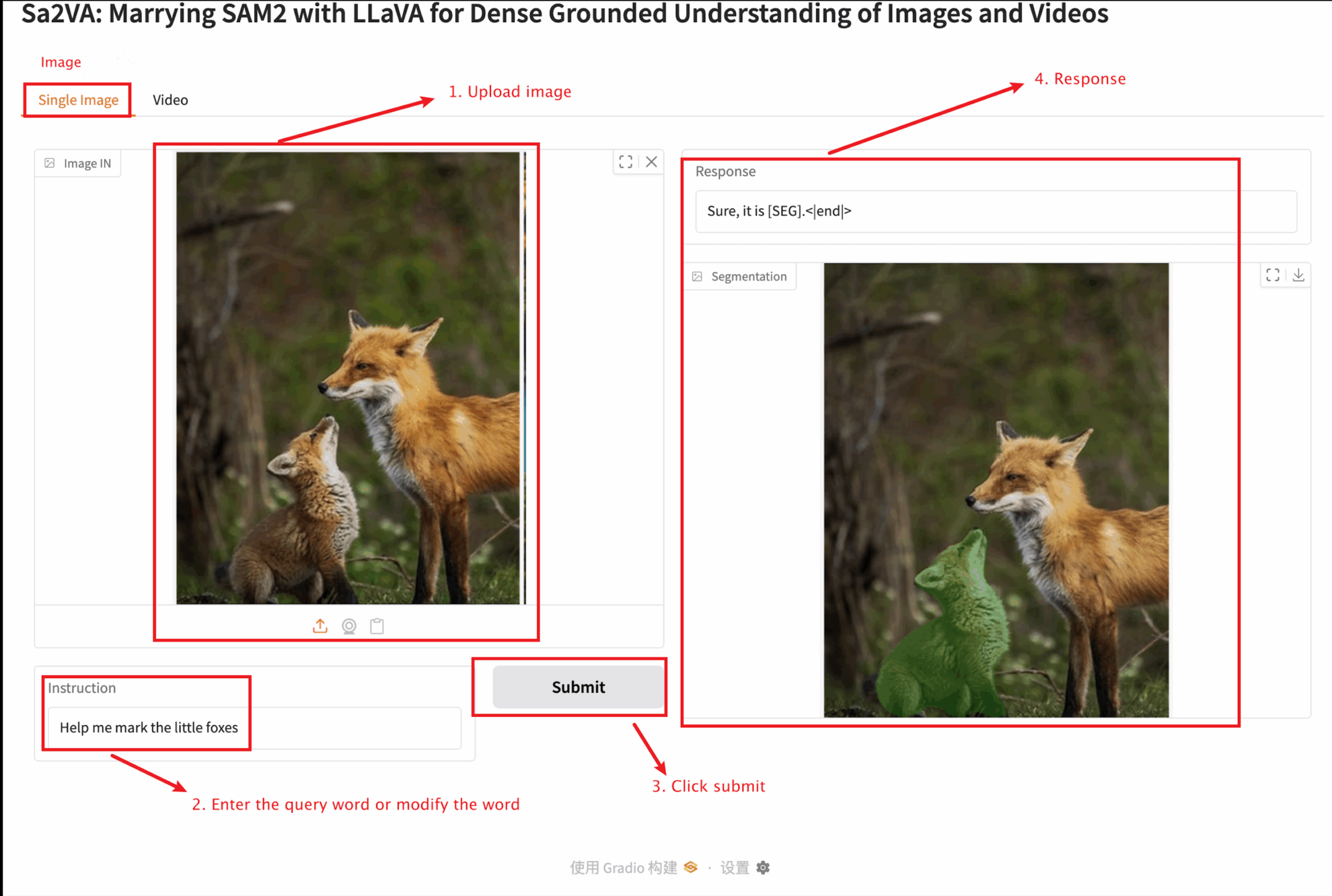
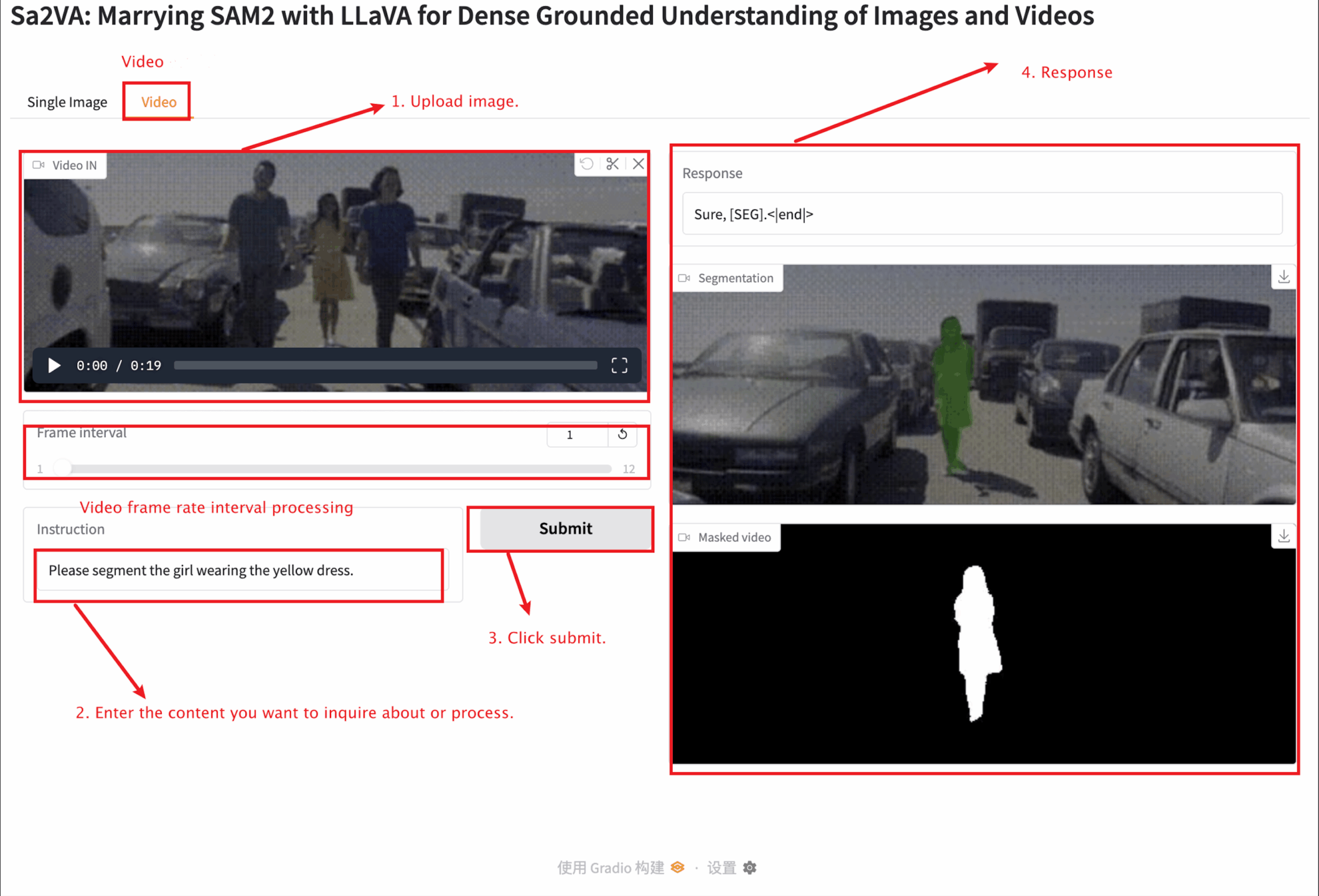
2. 进入网页后,即可与模型进行交互
本教程提供两种模块测试:Single image 和 video 模块。
上传图片大小不宜超过 10 MB , 上传视频时长不宜超过 1 分钟,视频大小不宜超过 50 MB,否则可能导致模型运行缓慢或报错。
重要参数说明:
Single image
Video
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

五、引用信息
感谢 Github 用户 zhangjunchang 对本教程的部署,本项目引用信息如下:
@article{pixel_sail,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Zhang, Tao and Li, Xiangtai and Huang, Zilong and Li, Yanwei and Lei, Weixian and Deng, Xueqing and Chen, Shihao and Ji, Shunping and and Feng, Jiashi},
journal={arXiv},
year={2025}
}
@article{sa2va,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Yuan, Haobo and Li, Xiangtai and Zhang, Tao and Huang, Zilong and Xu, Shilin and Ji, Shunping and Tong, Yunhai and Qi, Lu and Feng, Jiashi and Yang, Ming-Hsuan},
journal={arXiv},
year={2025}
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。