HyperAI
Command Palette
Search for a command to run...
MMaDA:多模态大型扩散语言模型
一、教程简介

MMaDA-8B-Base 是由普林斯顿大学、字节跳动 Seed 团队、北京大学和清华大学联合研发并于 2025 年 5 月 23 日的发布多模态扩散大语言模型。该模型是首个系统性探索扩散架构作为多模态基础范式的统一模型,旨在通过文本推理、多模态理解和图像生成的深度融合,实现跨模态任务的通用智能能力。相关论文成果为 MMaDA: Multimodal Large Diffusion Language Models 。
该教程算力资源采用单卡 A6000,本教程部署的模型为 MMaDA-8B-Base 。提供 Text Generation 、 Multimodal Understanding 和 Text-to-Image Generation 三个示例供测试。
二、运行步骤
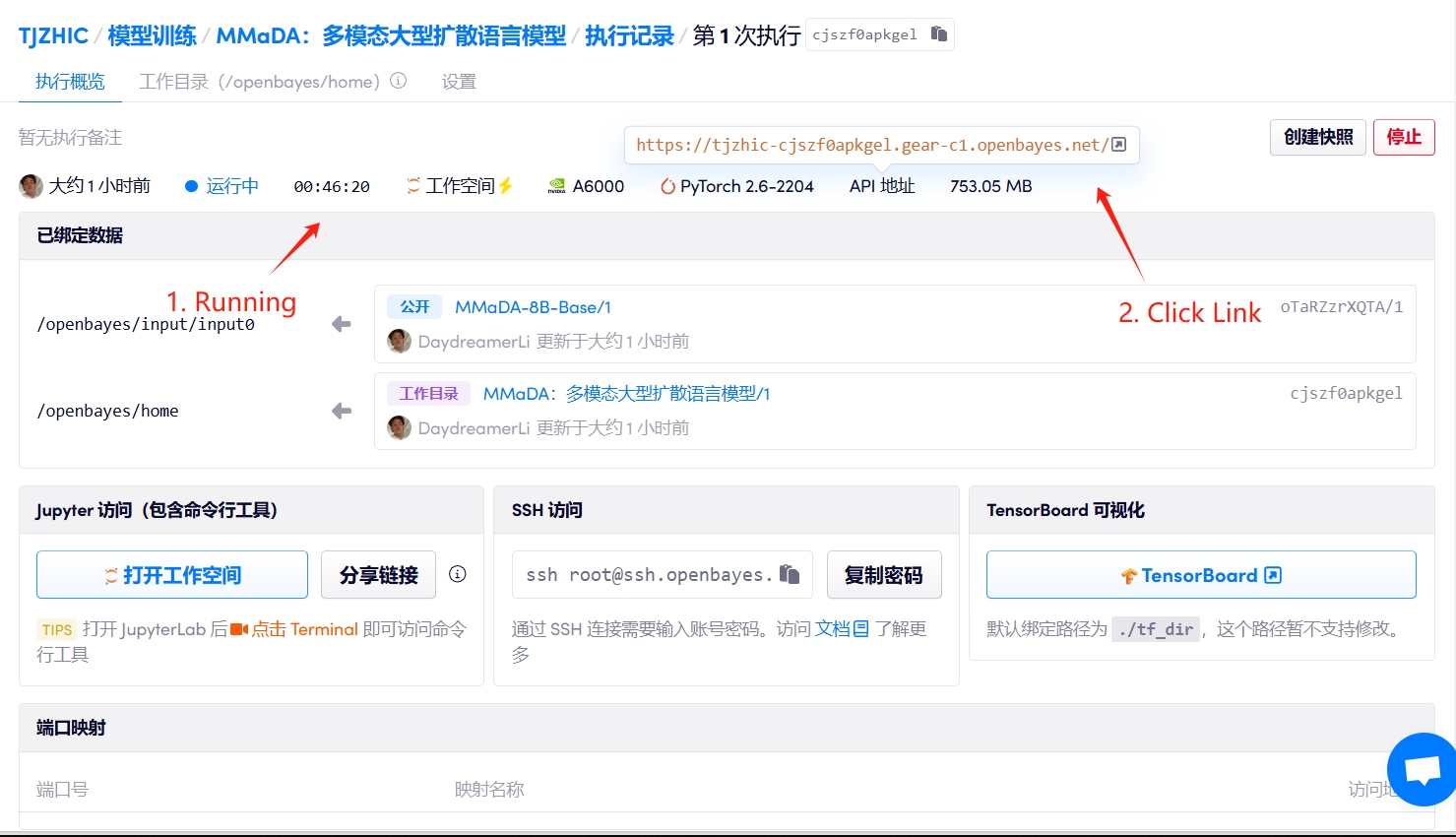
1. 启动容器
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
2. 使用步骤
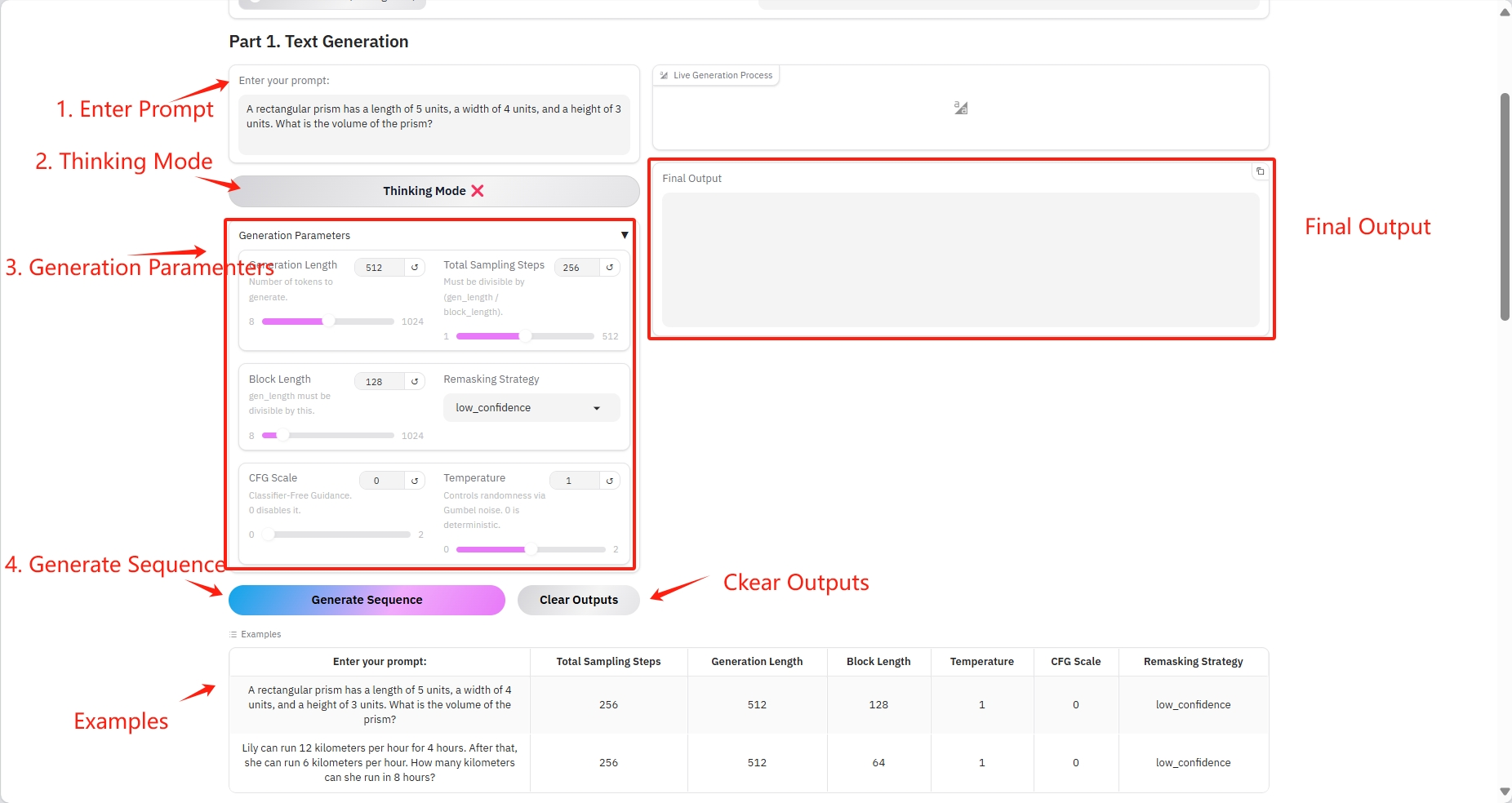
1. Text Generation
具体参数:
- Prompt:这里可以输入文本文字。
- Generation Length:生成 tokens 的数量。
- Total Sampling Steps:必须能被(gen_length / block_length)整除。
- Block Length:gen_length 必须能被这个数整除。
- Remasking Strategy:重新掩码策略。
- CFG Scale:无分类器指南。 0 禁用它。
- Temperature:通过 Gumbel 噪声控制随机性。 0 是确定性的。
结果输出
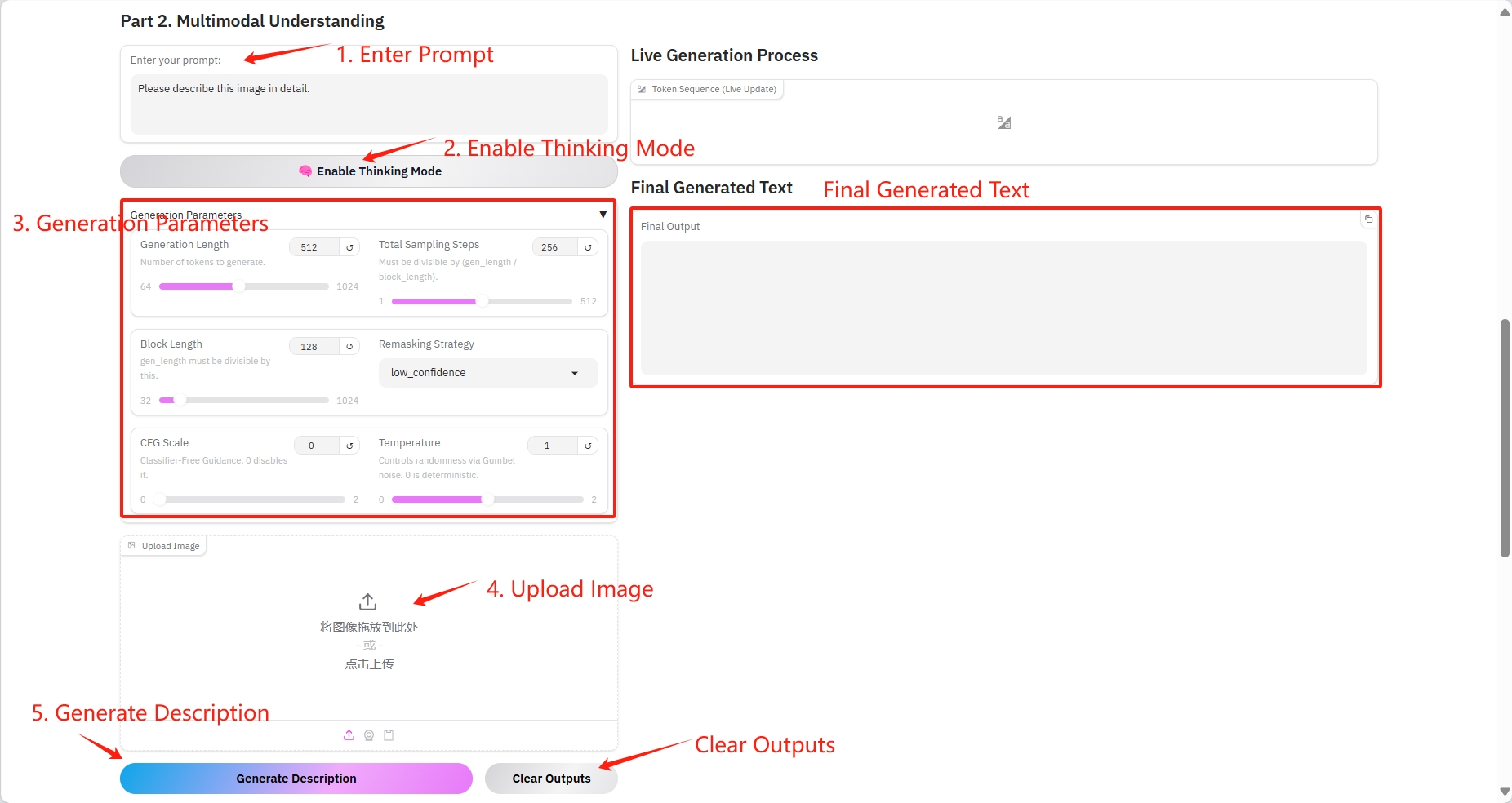
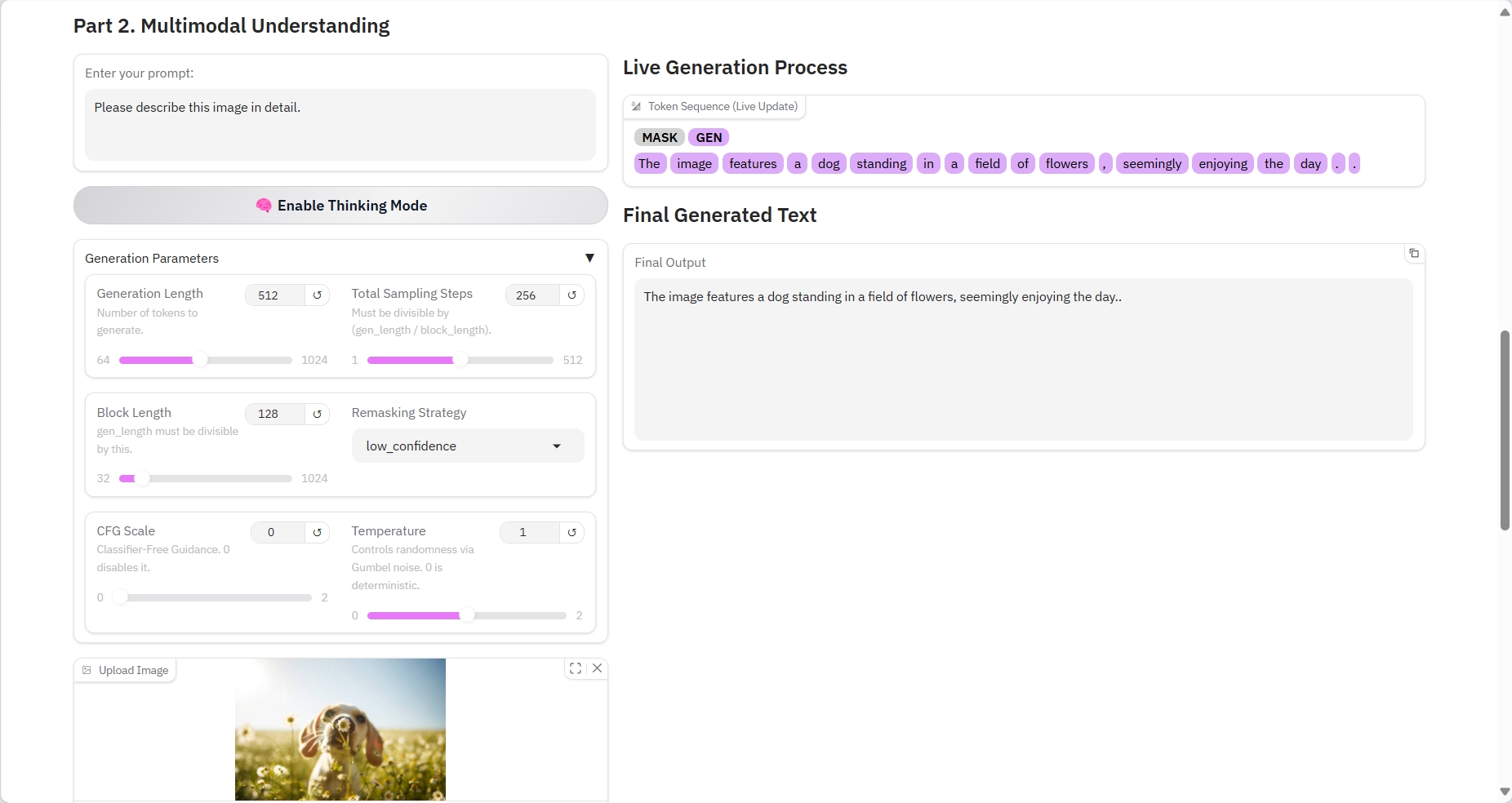
2. Multimodal Understanding
具体参数:
- Prompt:这里可以输入文本文字。
- Generation Length:生成 tokens 的数量。
- Total Sampling Steps:必须能被(gen_length / block_length)整除。
- Block Length:gen_length 必须能被这个数整除。
- Remasking Strategy:重新掩码策略。
- CFG Scale:无分类器指南。 0 禁用它。
- Temperature:通过 Gumbel 噪声控制随机性。 0 是确定性的。
- Image:图片。
结果输出
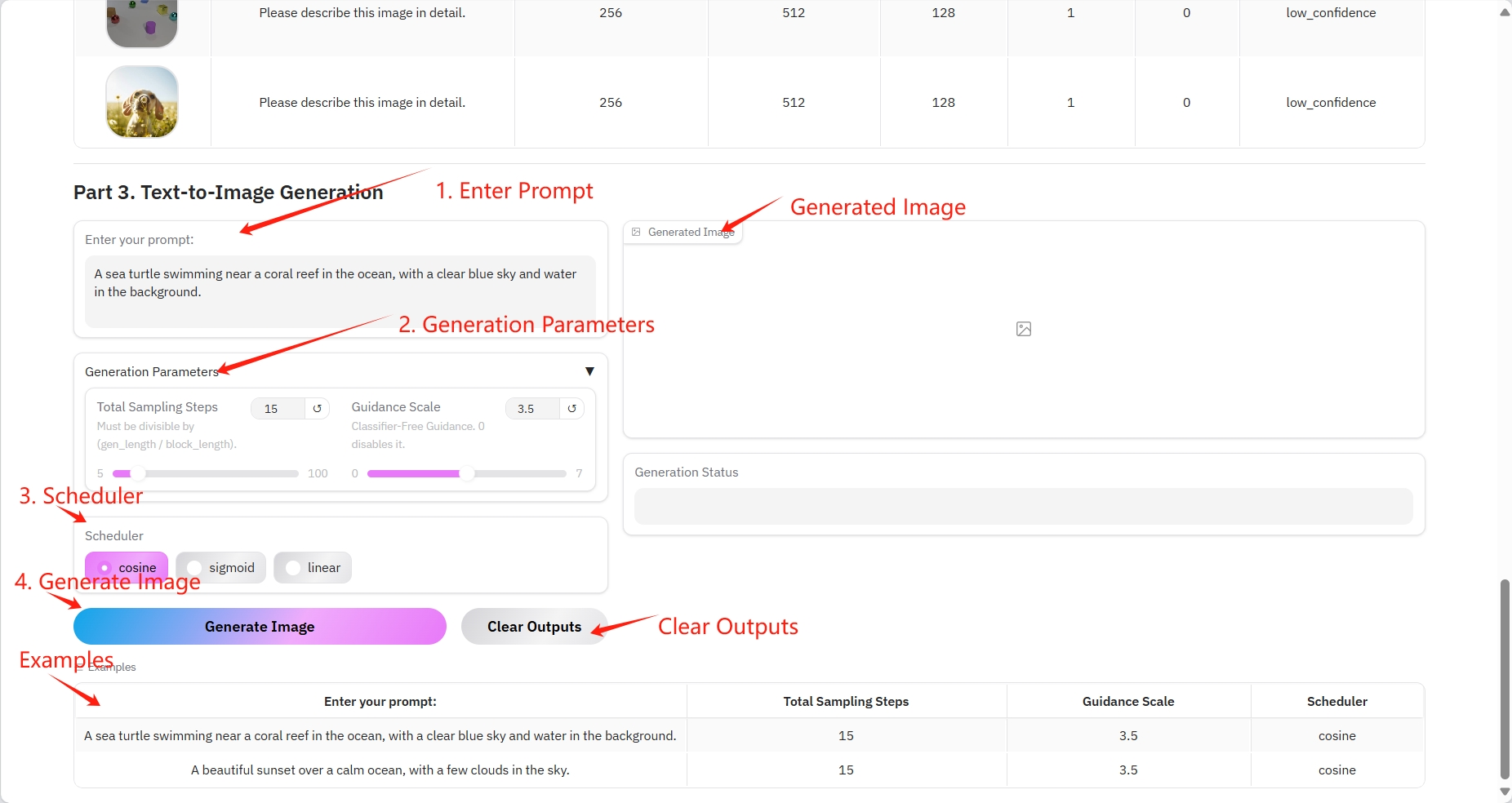
3. Text-to-Image Generation
具体参数:
- Prompt:这里可以输入文本文字。
- Total Sampling Steps:必须能被(gen_length / block_length)整除。
- Guidance Scale:无分类器指南。 0 禁用它。
- Scheduler:
- cosine:余弦相似度计算句子对的相似性,优化嵌入向量。
- sigmoid:多标签分类。
- linear:线性层将图像块嵌入向量映射到更高维度进行注意力计算。
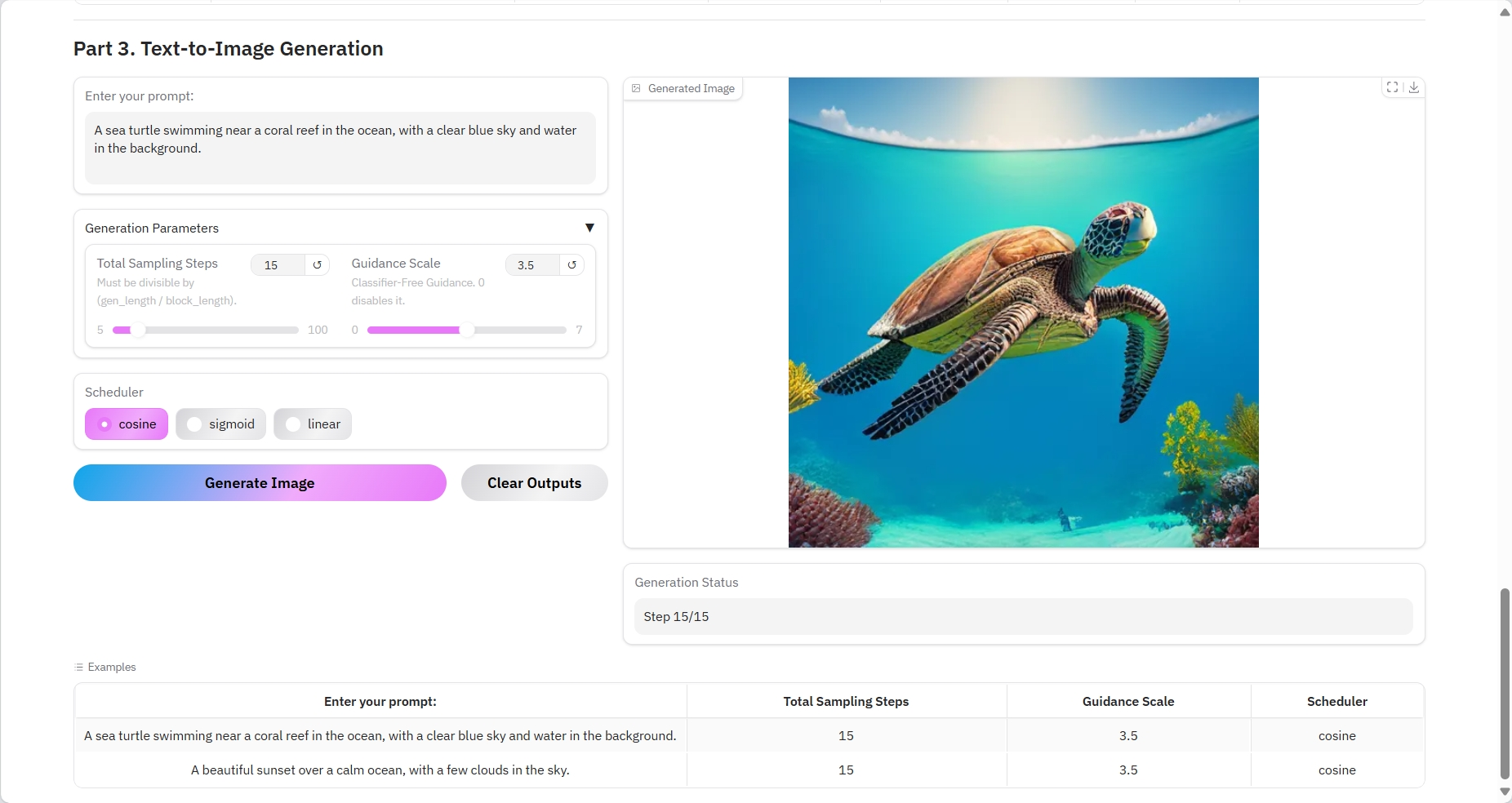
结果输出
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
感谢 Github 用户 SuperYang 对本教程的部署。本项目引用信息如下:
@article{yang2025mmada,
title={MMaDA: Multimodal Large Diffusion Language Models},
author={Yang, Ling and Tian, Ye and Li, Bowen and Zhang, Xinchen and Shen, Ke and Tong, Yunhai and Wang, Mengdi},
journal={arXiv preprint arXiv:2505.15809},
year={2025}
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。