HyperAI
Command Palette
Search for a command to run...
Describe Anything「描述一切」模型 Demo
项目概述

Describe Anything Model(DAM)是由 NVIDIA 、 UC Berkeley 和 UCSF 团队联合开发,于 2025 年发布的创新图像和视频描述模型。该模型能够根据用户指定的区域(点、框、涂鸦或蒙版)生成详细的描述。对于视频内容,只需在任意帧上标注区域即可获得完整的描述。相关论文成果为 Describe Anything: Detailed Localized Image and Video Captioning 。
本教程采用资源为单卡 RTX 4090 。
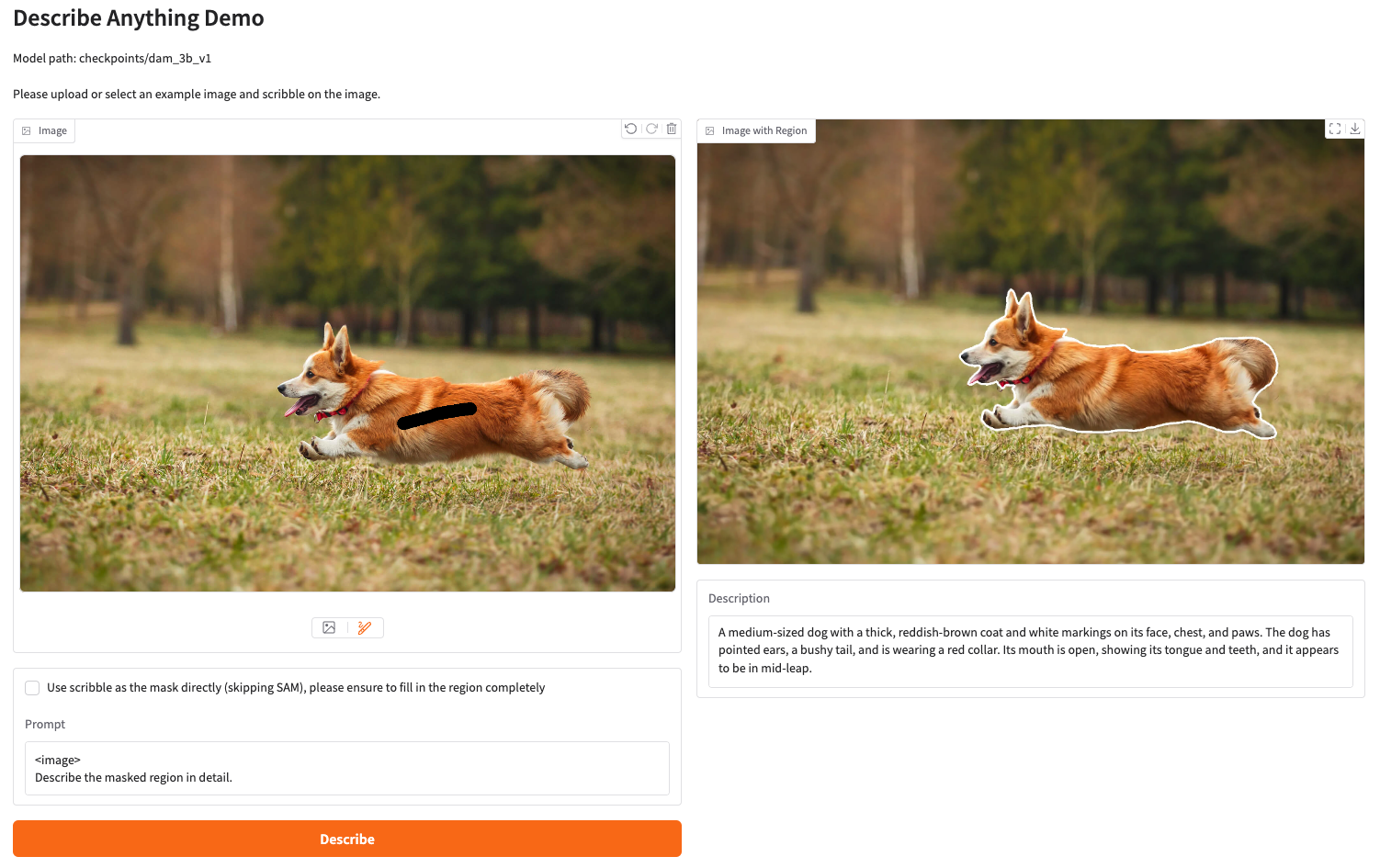
项目示例
运行步骤
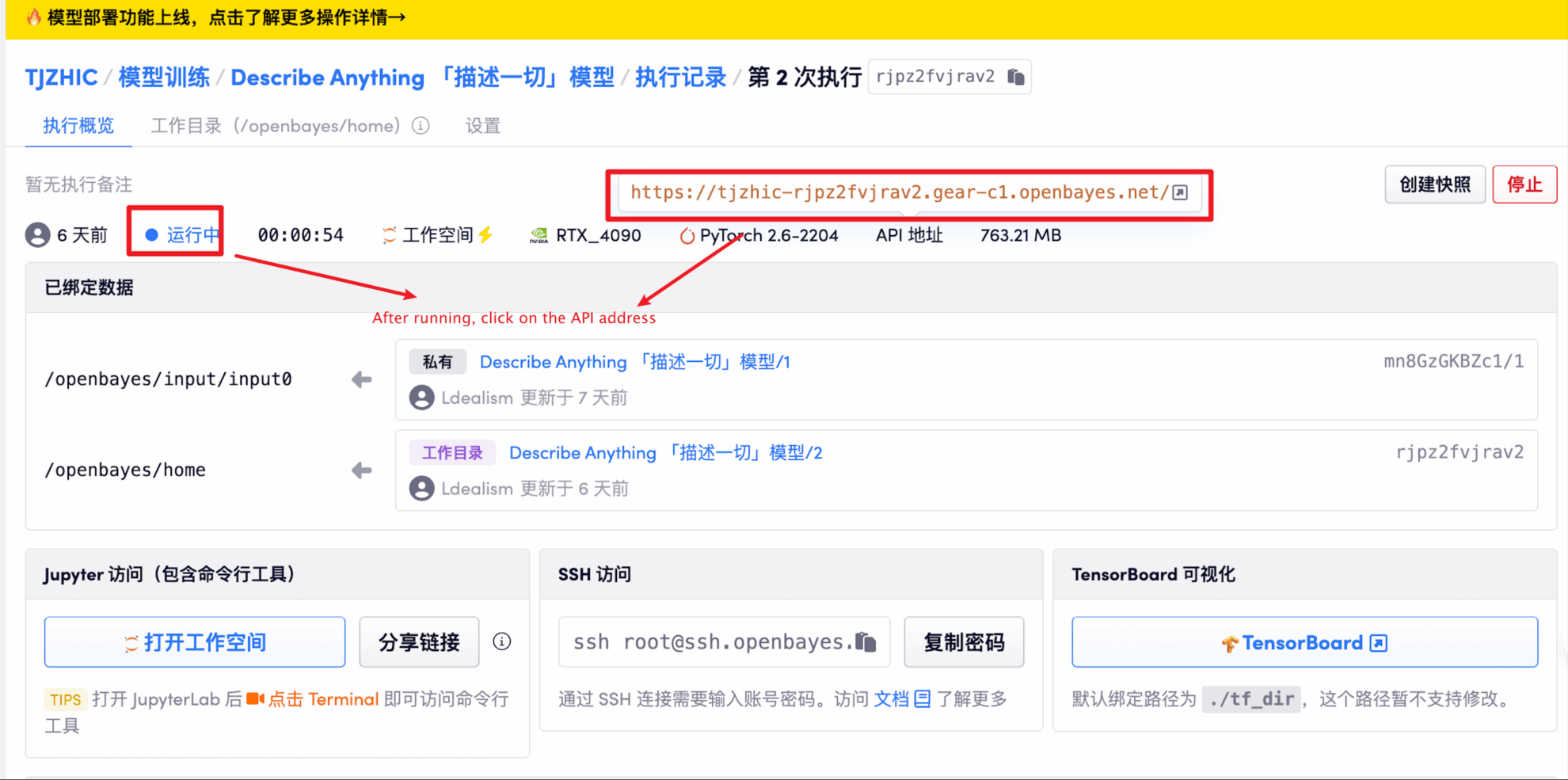
1. 启动容器后点击 API 地址即可进入 Web 界面
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
2. 进入网页后,即可与模型进行交互
图片大小不宜超过 5 MB , 视频时长不宜超过 20 秒,视频大小不宜超过 5 MB ,否则可能会导致模型运行缓慢或报错,请合理选择区域进行描述。
本教程提供两种模块测试: image mode 和 video mode 模块。
各模块功能如下:
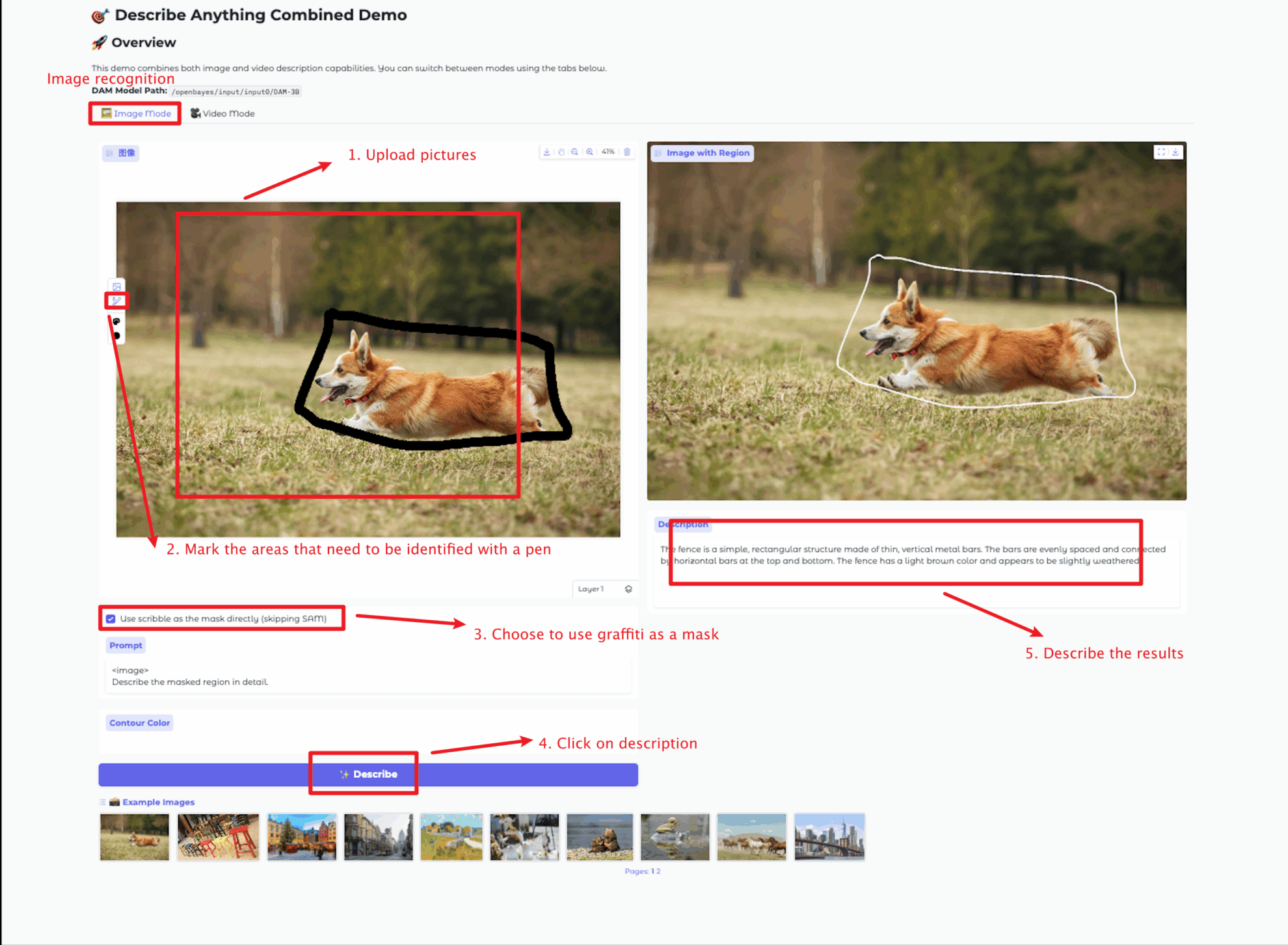
Image Mode
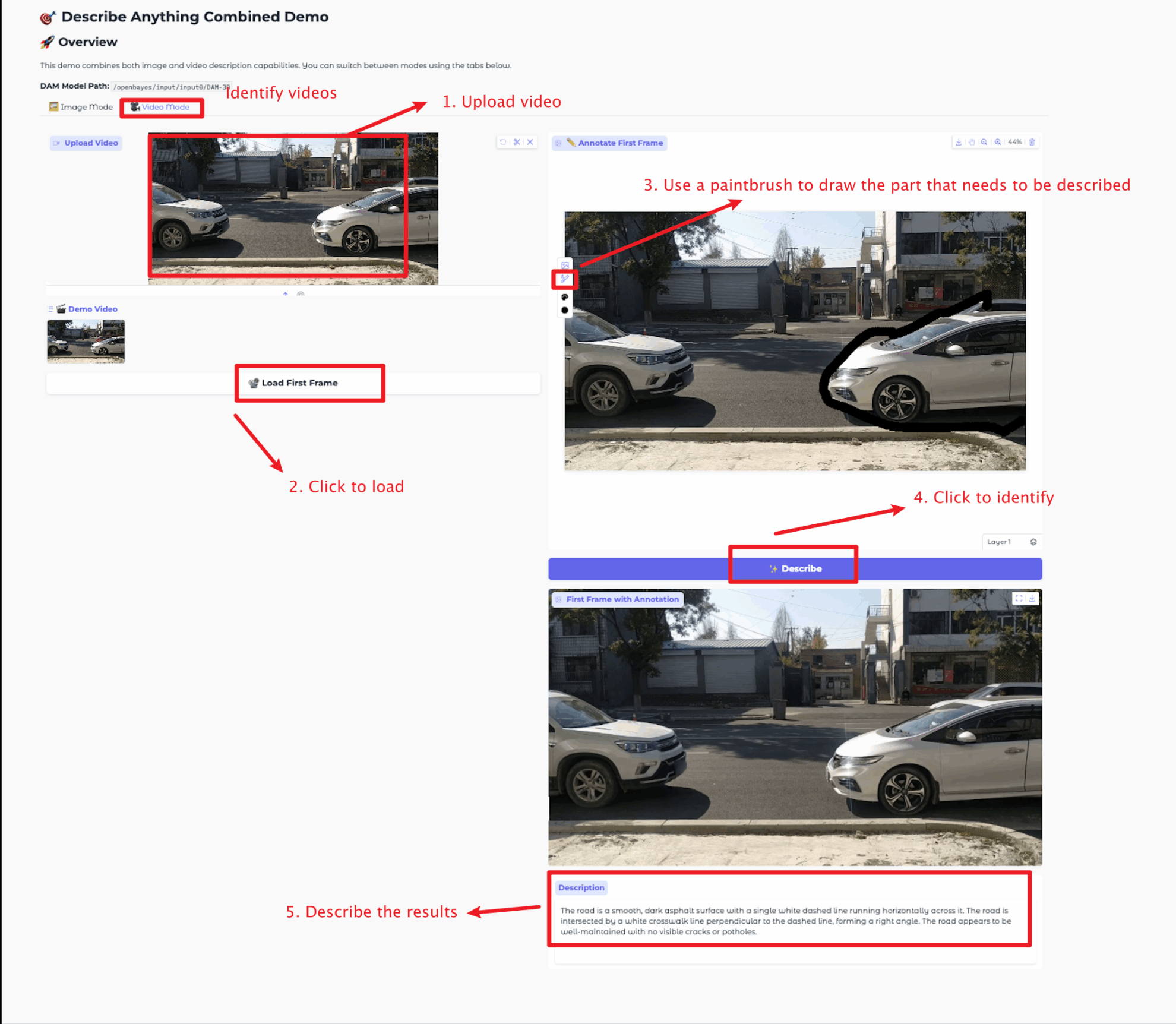
Video Mode
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
感谢 Github 用户 zhangjunchang 对本教程的部署,本项目引用信息如下:
@article{lian2025describe,
title={Describe Anything: Detailed Localized Image and Video Captioning},
author={Long Lian and Yifan Ding and Yunhao Ge and Sifei Liu and Hanzi Mao and Boyi Li and Marco Pavone and Ming-Yu Liu and Trevor Darrell and Adam Yala and Yin Cui},
journal={arXiv preprint arXiv:2504.16072},
year={2025}
} GitHub Stars arXiv 该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。