HyperAI
Command Palette
Search for a command to run...
使用 vLLM+Open-webUI 部署 Qwen3-30B-A3B


一、教程简介

Qwen3 项目是由阿里 Qwen 团队于 2025 年发布,相关技术报告为 Qwen3: Think Deeper, Act Faster 。
Qwen3 是 Qwen 系列中最新一代大型语言模型,提供全面的密集模型和混合专家 (MoE) 模型。 Qwen3 基于丰富的训练经验,在推理、指令遵循、代理能力和多语言支持方面取得了突破性进展,最新版本 Qwen3 有以下特点:
- 全尺寸稠密与混合专家模型:0.6B 、 1.7B 、 4B, 8B 、 14B 、 32B and 30B-A3B 、 235B-A22B
- 支持在思考模式(用于复杂逻辑推理、数学和编码)和 非思考模式(用于高效通用对话)之间无缝切换,确保在各种场景下的最佳性能。
- 显著增强的推理能力,在数学、代码生成和常识逻辑推理方面超越了之前的 QwQ(在思考模式下)和 Qwen2.5 指令模型(在非思考模式下)。
- 卓越的人类偏好对齐,在创意写作、角色扮演、多轮对话和指令跟随方面表现出色,提供更自然、更吸引人和更具沉浸感的对话体验。
- 擅长智能体能力,可以在思考和非思考模式下精确集成外部工具,在复杂的基于代理的任务中在开源模型中表现领先。
- 支持 100 多种语言和方言,具有强大的多语言理解、推理、指令跟随和生成能力。
本教程采用资源为双卡 A6000 。
👉 该项目提供了一种型号的模型:
- Qwen3-30B-A3B 模型
二、运行步骤
- 启动容器后点击 API 地址即可进入 Web 界面
若不显示「模型」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
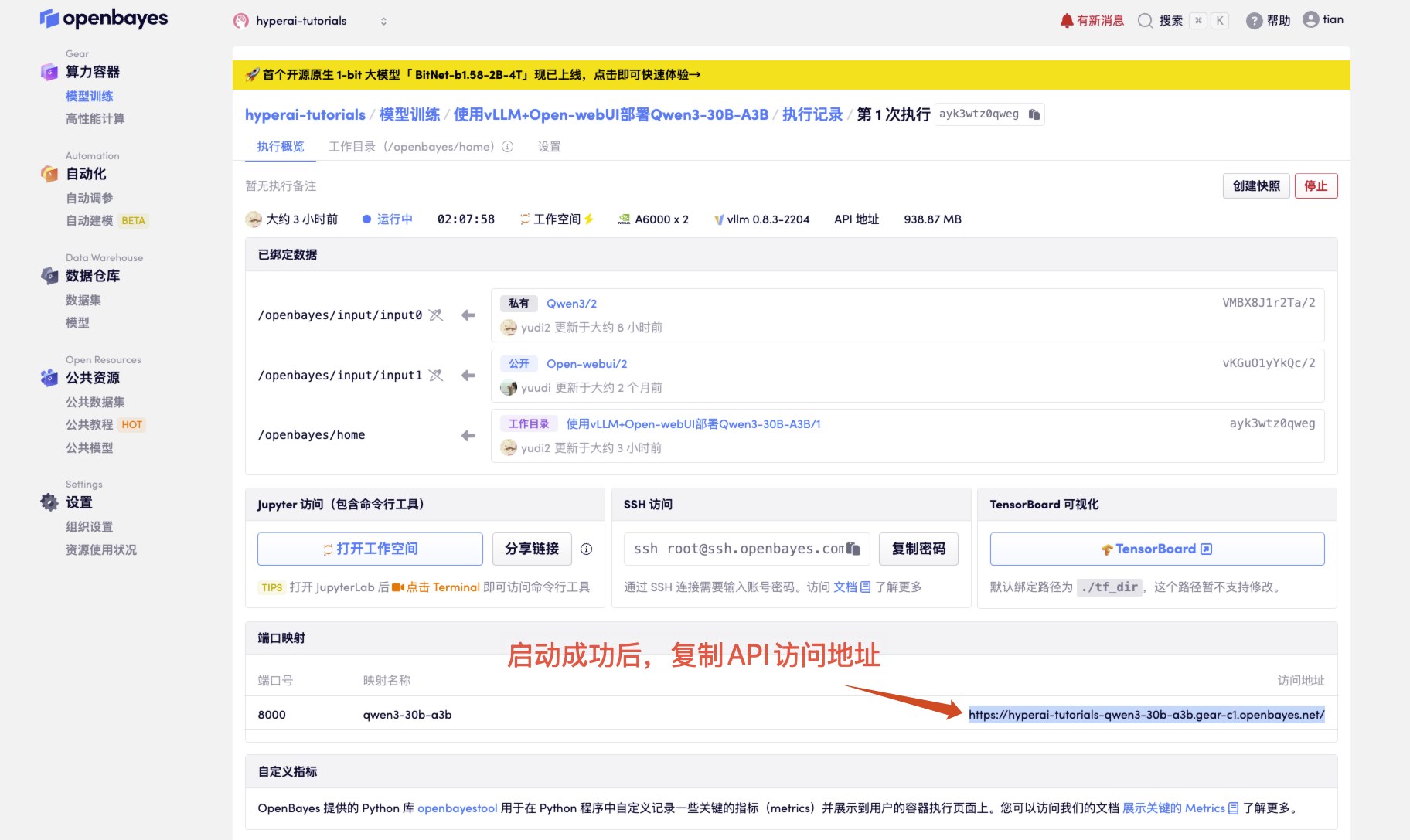
2. 进入网页后,即可与模型展开对话
使用步骤

三、 OpenAI API 调用指南
以下是优化后的 API 调用方法说明,结构更清晰且增加了实用细节:
1. 获取基础配置
# 必要参数配置
BASE_URL = "<API 地址>/v1" # 生产环境
MODEL_NAME = "Qwen3-30B-A3B" # 默认模型名称
API_KEY = "Empty" # 未设置 API_KEY
获取 API 地址
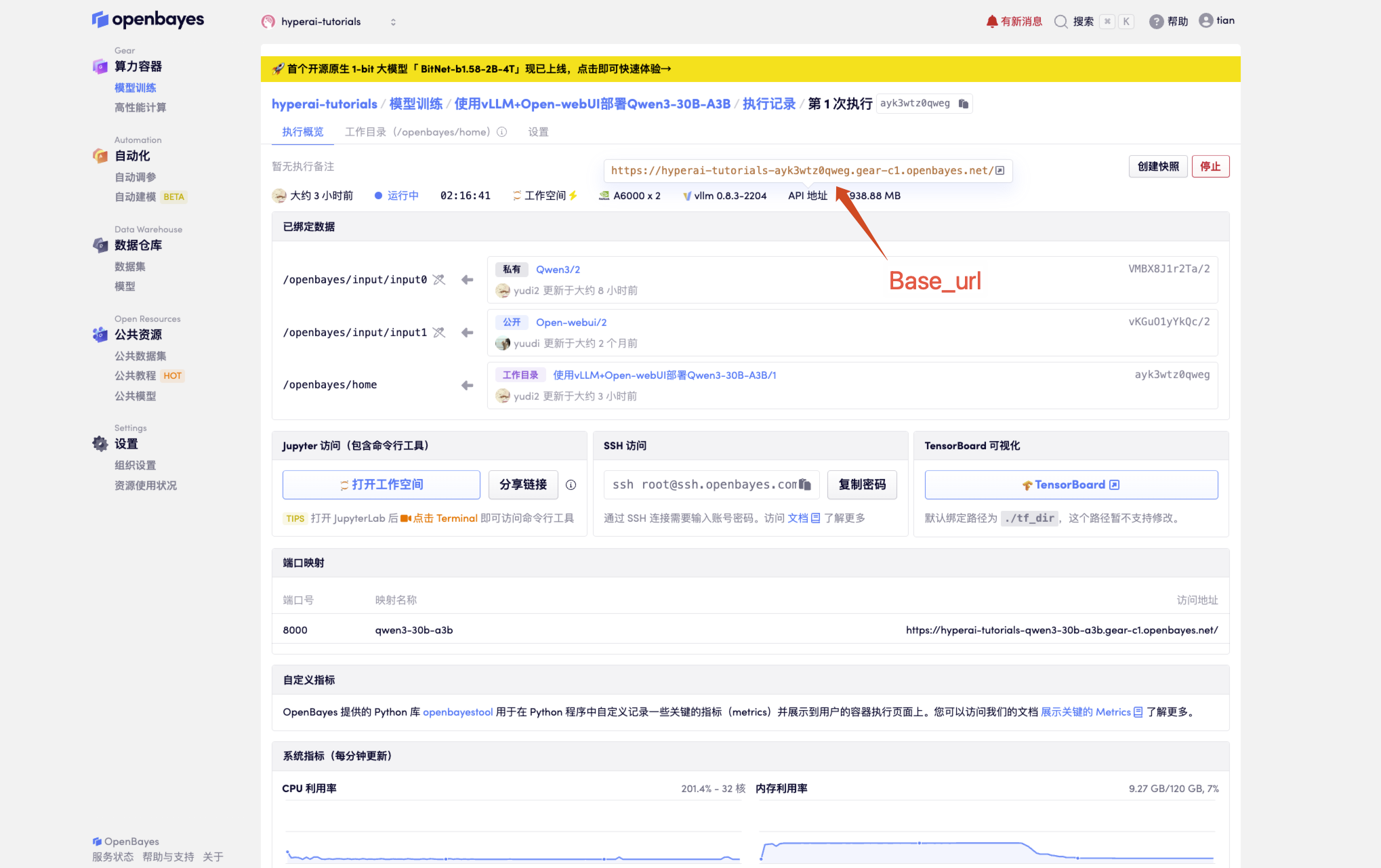
2. 不同调用方式
2.1 原生 Python 调用
import openai
# 创建 OpenAI 客户端实例
client = openai.OpenAI(
api_key=API_KEY, # 请替换为你的实际 API Key
base_url=BASE_URL # 替换为你的实际 base_url
)
# 发送聊天消息
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "user", "content": "你好!"}
],
temperature=0.7,
)
# 输出回复内容
print(response.choices[0].message.content)
# 方法 2:requests 库(更灵活)
import requests
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
data = {
"model": MODEL_NAME,
"messages": [{"role": "user", "content": "你好!"}]
}
response = requests.post(f"{BASE_URL}/chat/completions", headers=headers, json=data)
2.2 开发工具集成
如 VScode 安装官方 CLINE 插件
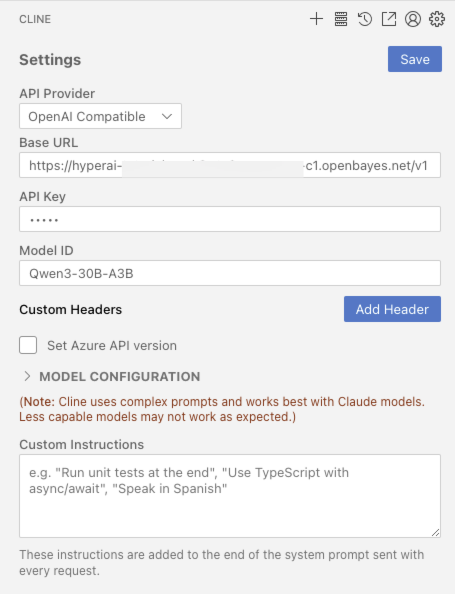
2.3 cURL 调用
curl <BASE_URL>/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": <MODEL_NAME>,
"messages": [{"role": "user", "content": "你好!"}]
}'
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
感谢 ZV-Liu 对本教程的制作,本项目引用信息如下:
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。