HyperAI
Command Palette
Search for a command to run...
PixelFlow:像素空间图像生成方案
一、教程简介
PixelFlow 项目是香港大学 Adobe 团队于 2025 年 4 月发布的 AI 图像生成模型,这是一系列直接在原始像素空间中运行的图像生成模型,与主要的潜在空间模型形成鲜明对比。相关论文成果为 PixelFlow: Pixel-Space Generative Models with Flow 。
这种方法无需预先训练的变分自动编码器 (VAE) 并实现整个模型的端到端可训练,从而简化了图像生成过程。通过高效的级联流建模,PixelFlow 在像素空间中实现了可承受的计算成本。它在 256×256 ImageNet 类条件图像生成基准测试中实现了 1.98 的 FID 。文本到图像的定性结果表明,PixelFlow 在图像质量、艺术性和语义控制方面表现出色。我们希望这种新范式能够激发并为下一代视觉生成模型开辟新的机会。

本教程采用资源为单卡 RTX 4090 。
👉 该项目提供了一种型号的模型:
- class-to-image: 它在 256×256 ImageNet 类条件图像生成基准测试中实现了 1.98 的 FID 。
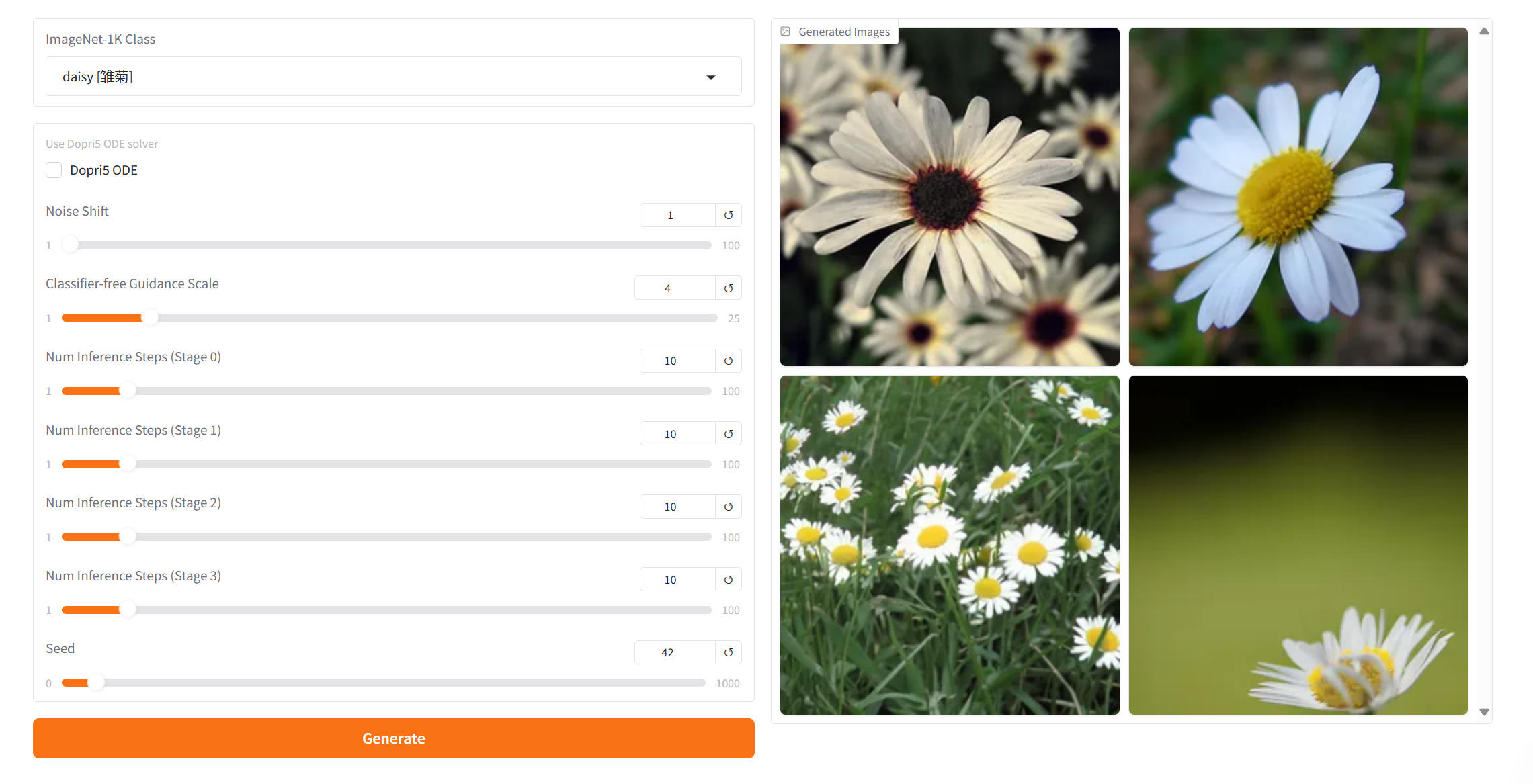
项目示例
二、运行步骤
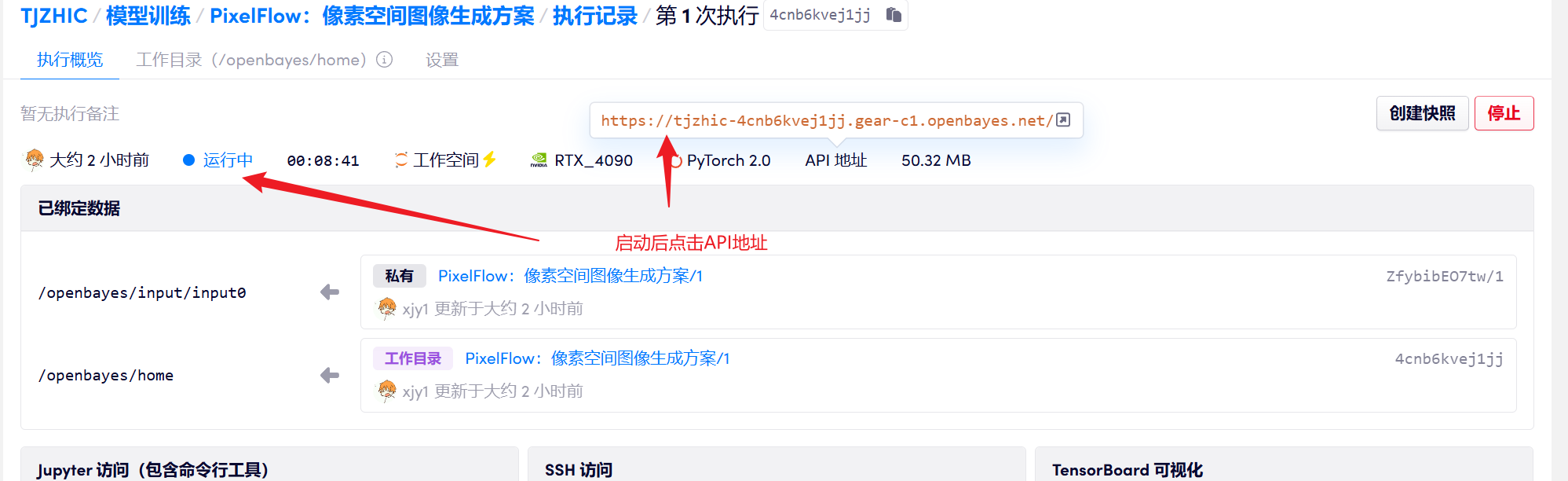
1. 启动容器后点击 API 地址即可进入 Web 界面
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
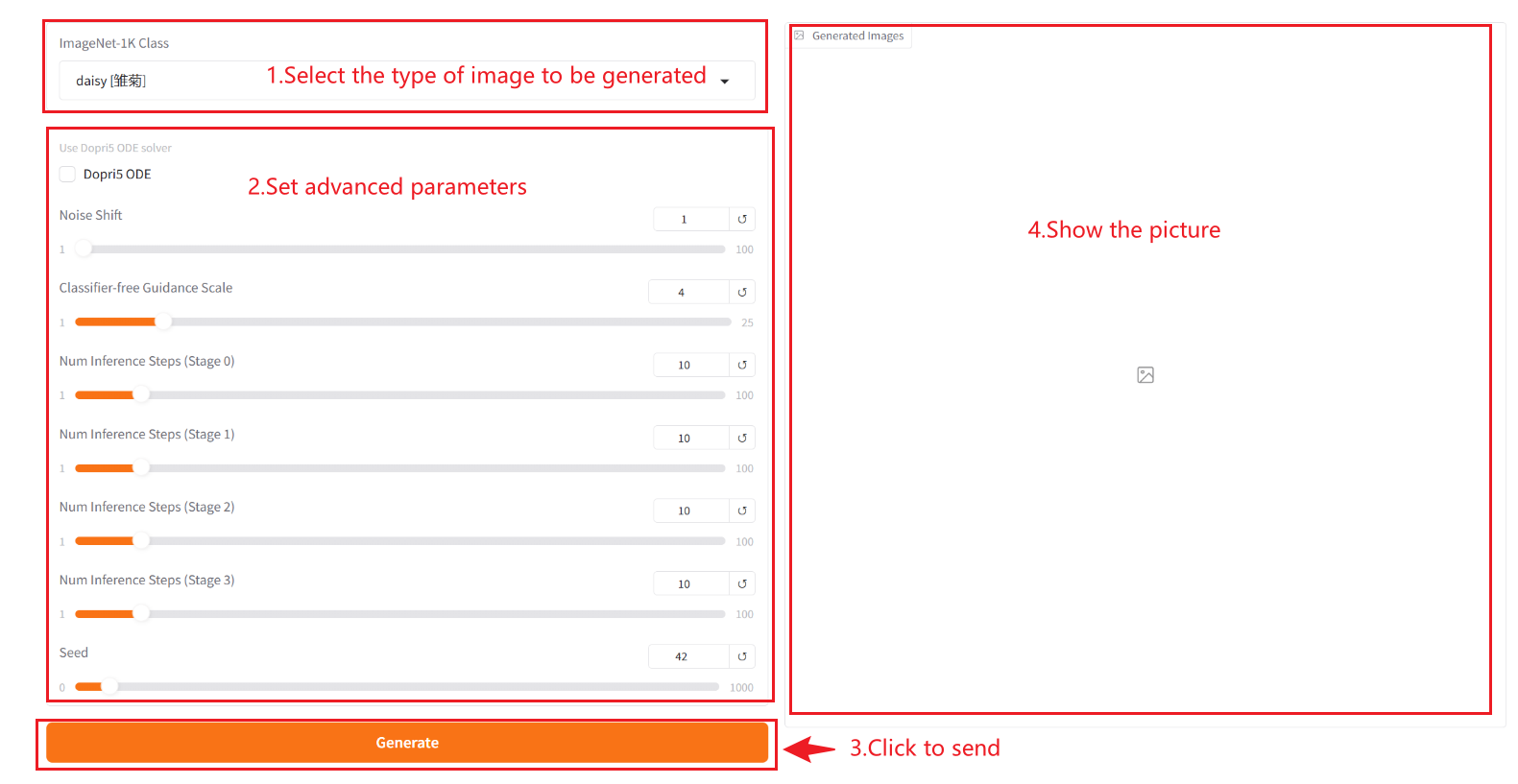
2. 进入网页后,即可与模型展开对话
❗️重要的使用技巧:
- ImageNet-1k Class: 生成的图片只能选择下拉框给出的类别,无法自定义。
- Dopri5 ODE: 它是 Dormand-Prince 5 阶自适应步长 ODE 求解器,需要高质量生成时启用(例如生成高清图像)。
- Noise Shift: 控制生成过程中噪声的偏移量,较大的值会增加噪声的强度,使生成结果更随机、多样化,较小的值会减少噪声的干扰,生成结果更接近训练数据的分布(更保守)。
- Classifier-free Guidance Scale: 它用于控制生成模型中条件输入(如文本或图像)对生成结果的影响程度。较高的指导值会让生成结果更加贴近输入条件,而较低的值会保留更多随机性。
- Num Inference Steps [stage 0 ]: 表示模型的迭代次数或推理过程中的步数, 代表模型用于生成结果的优化步数。更高的步数通常会生成更精细的结果,但可能增加计算时间。 [stage 0 ] 表示生成的图片,后面的数字加 1 就是表示第几章图,一共有四张图片。
- Seed: 是随机数种子,用于控制生成过程中的随机性。相同的 Seed 值可以生成相同的结果(前提是其他参数相同),这在结果复现中非常重要。
使用步骤
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@article{chen2025pixelflow,
title={PixelFlow: Pixel-Space Generative Models with Flow},
author={Chen, Shoufa and Ge, Chongjian and Zhang, Shilong and Sun, Peize and Luo, Ping},
journal={arXiv preprint arXiv:2504.07963},
year={2025}
}
本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。