HyperAI
Command Palette
Search for a command to run...
Qwen2.5-Omni 看听说写全模态打通
日期
1 年前
标签
一、教程简介
Qwen2.5-Omni 是阿里巴巴通义千问团队于 2025 年 3 月 27 日发布的最新端到端多模态旗舰模型,专为全面的多模式感知设计,无缝处理包括文本、图像、音频和视频在内的各种输入,同时支持流式的文本生成和自然语音合成输出。
主要特点
- 全能创新架构:采用了一种全新的 Thinker-Talker 架构,这是一种端到端的多模态模型,旨在支持文本/图像/音频/视频的跨模态理解,同时以流式方式生成文本和自然语音响应。研究团队提出了一种新的位置编码技术,称为 TMRoPE (Time-aligned Multimodal RoPE),通过时间轴对齐实现视频与音频输入的精准同步。
- 实时音视频交互:架构旨在支持完全实时交互,支持分块输入和即时输出。
- 自然流畅的语音生成:在语音生成的自然性和稳定性方面超越了许多现有的流式和非流式替代方案。
- 全模态性能优势:在同等规模的单模态模型进行基准测试时,表现出卓越的性能。 Qwen2.5-Omni 在音频能力上优于类似大小的 Qwen2-Audio,并与 Qwen2.5-VL-7B 保持同等水平。
- 卓越的端到端语音指令跟随能力:Qwen2.5-Omni 在端到端语音指令跟随方面表现出与文本输入处理相媲美的效果,在 MMLU 通用知识理解和 GSM8K 数学推理等基准测试中表现优异。
本教程使用 Qwen2.5-Omni 作为演示,算力资源采用 A6000 。
支持功能:
- 在线多模态对话
- 离线多模态对话
二、运行步骤
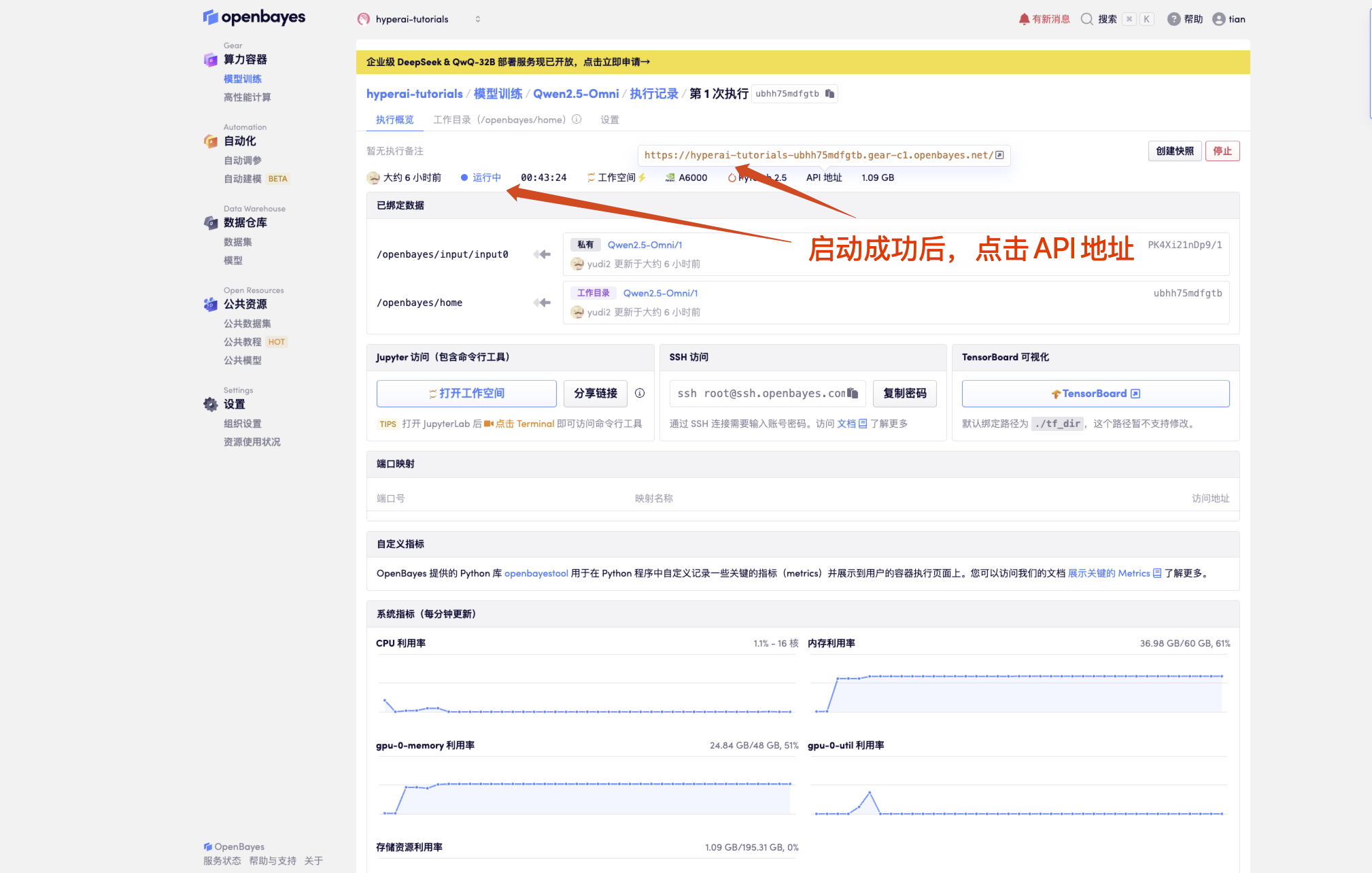
1. 启动容器后点击 API 地址即可进入 Web 界面
若不显示「模型」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
2. 进入网页后,即可与模型展开对话
当输入框为橙色时表示模型正在响应。
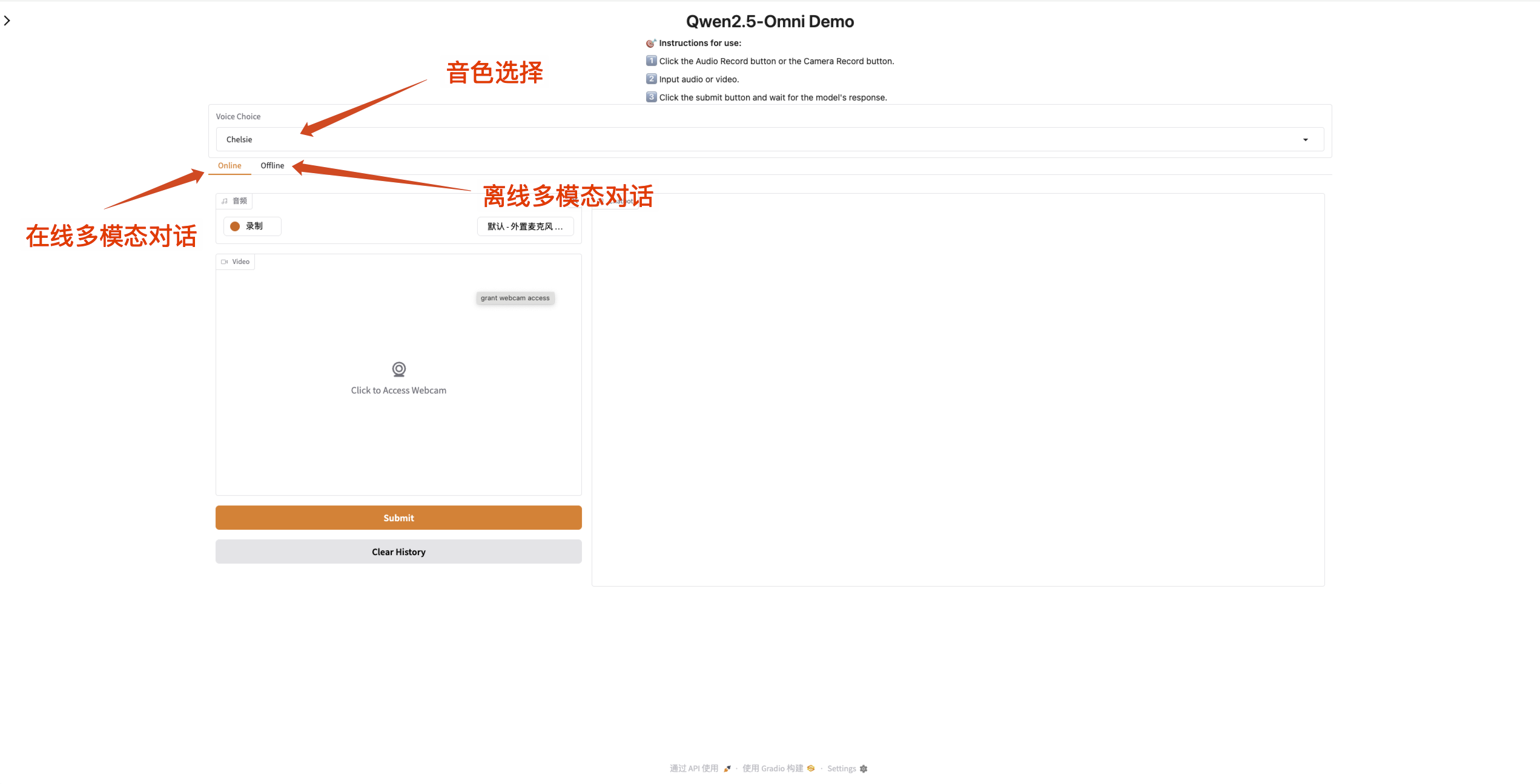
Qwen2.5-Omni 支持更改输出音频的声音。「Qwen/Qwen2.5-Omni-7B」检查点支持以下两种声音类型:
| 音色类型 | 性别 | 描述 |
|---|---|---|
| Chelsie | 女 | 甜美,温婉,明亮,轻柔 |
| Ethan | 男 | 阳光,活力,轻快,亲和 |
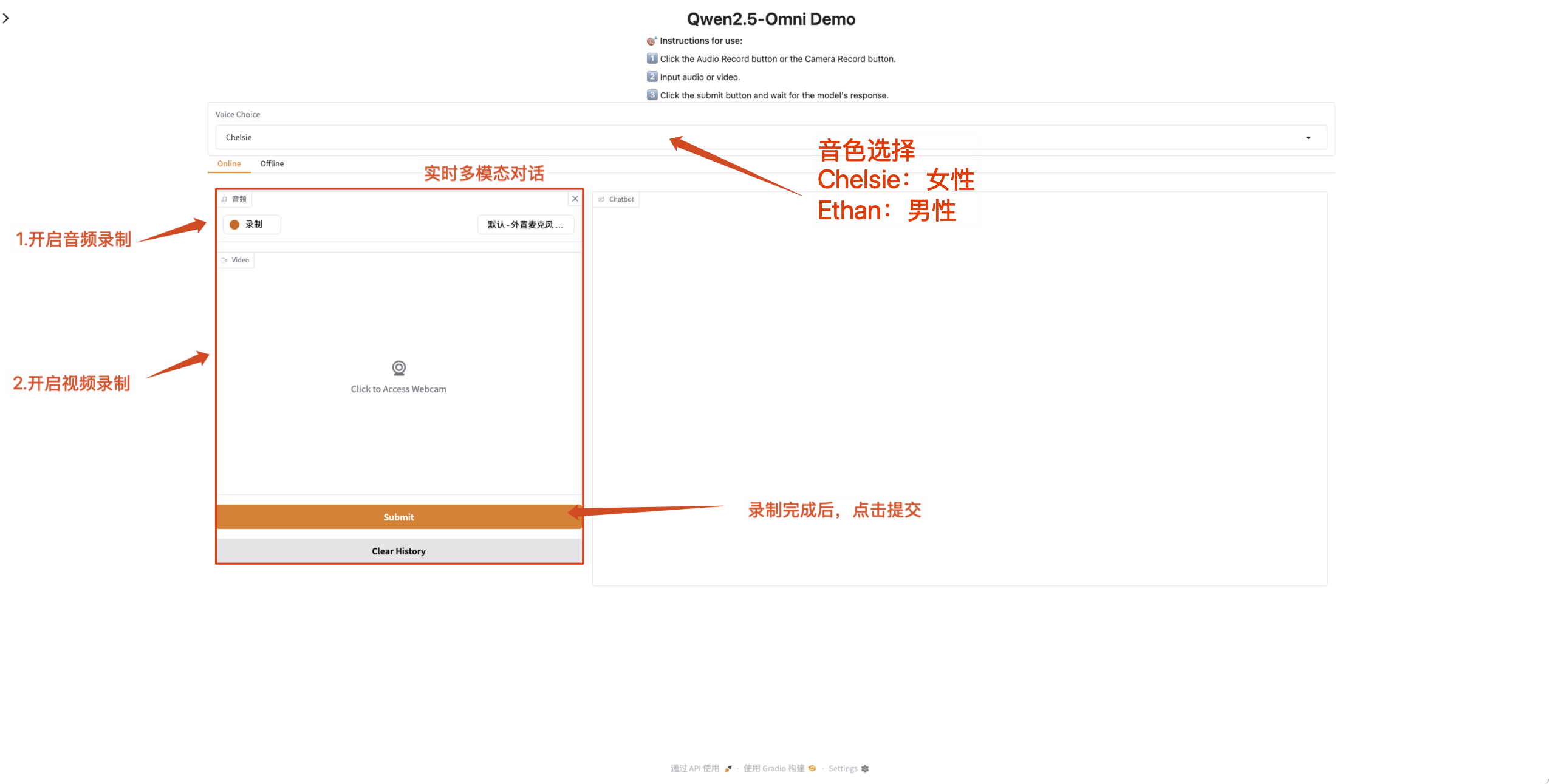
- 在线多模态对话
开启网页端的麦克风与摄像头权限,在录制完成后能够与 Qwen2.5-Omni 实时对话。
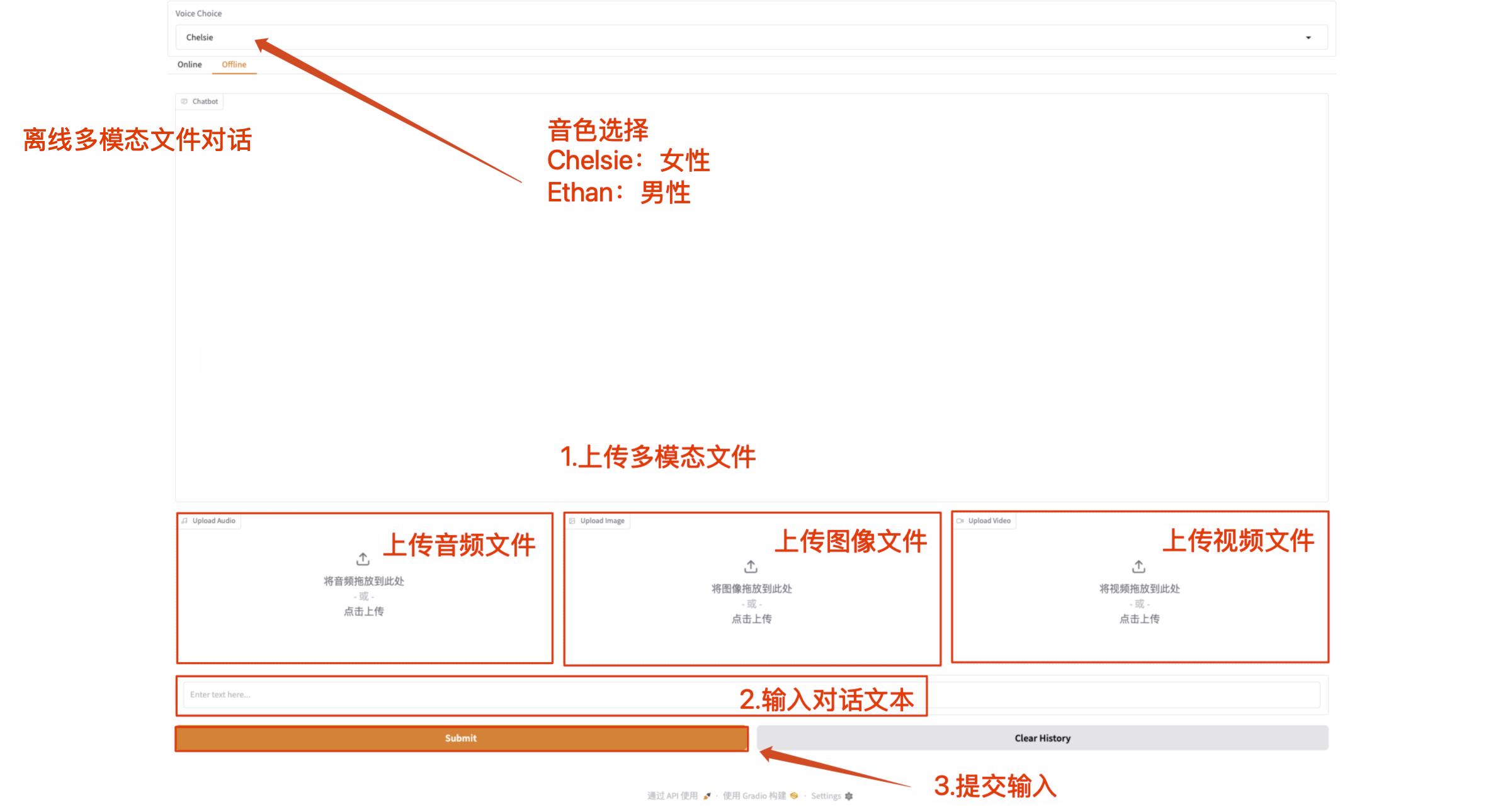
- 离线多模态对话
直接上传多模态文件,并配合文本内容与 Qwen2.5-Omni 对话。
注意:视频文件必须有声音,如果没有声音会显示报错。
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓ 
本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。