HyperAI
Command Palette
Search for a command to run...
用 Ollama 和 Open WebUI 部署 DeepSeek R1
一、教程简介
DeepSeek-R1 是深度求索 (DeepSeek) 公司于 2025 年推出的第一版语言模型系列,专注于高效、轻量化的自然语言处理任务。该系列模型通过先进的技术优化,如知识蒸馏,旨在在保持高性能的同时降低计算资源需求。 DeepSeek-R1 的设计注重实际应用场景,支持快速部署和集成,适用于多种任务,包括文本生成、对话系统、翻译和摘要生成等。
在技术层面,DeepSeek-R1 采用了知识蒸馏技术,通过从大模型中提取知识,训练出更小但性能接近的模型。同时,高效的分布式训练和优化算法进一步缩短了训练时间,提升了模型的开发效率。这些技术亮点使得 DeepSeek-R1 在实际应用中表现出色。
本教程预设 DeepSeek-R1-Distill-Qwen-1.5B 、 DeepSeek-R1-Distill-Qwen-7B 、 DeepSeek-R1-Distill-Qwen-8B 、 DeepSeek-R1-Distill-Qwen-32B 四种模型作为演示,算力资源采用「单卡 RTX4090」。
二、运行步骤
- 克隆并启动容器后,点击 API 地址即可进入 Web 界面(若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 5 分钟后重试。)
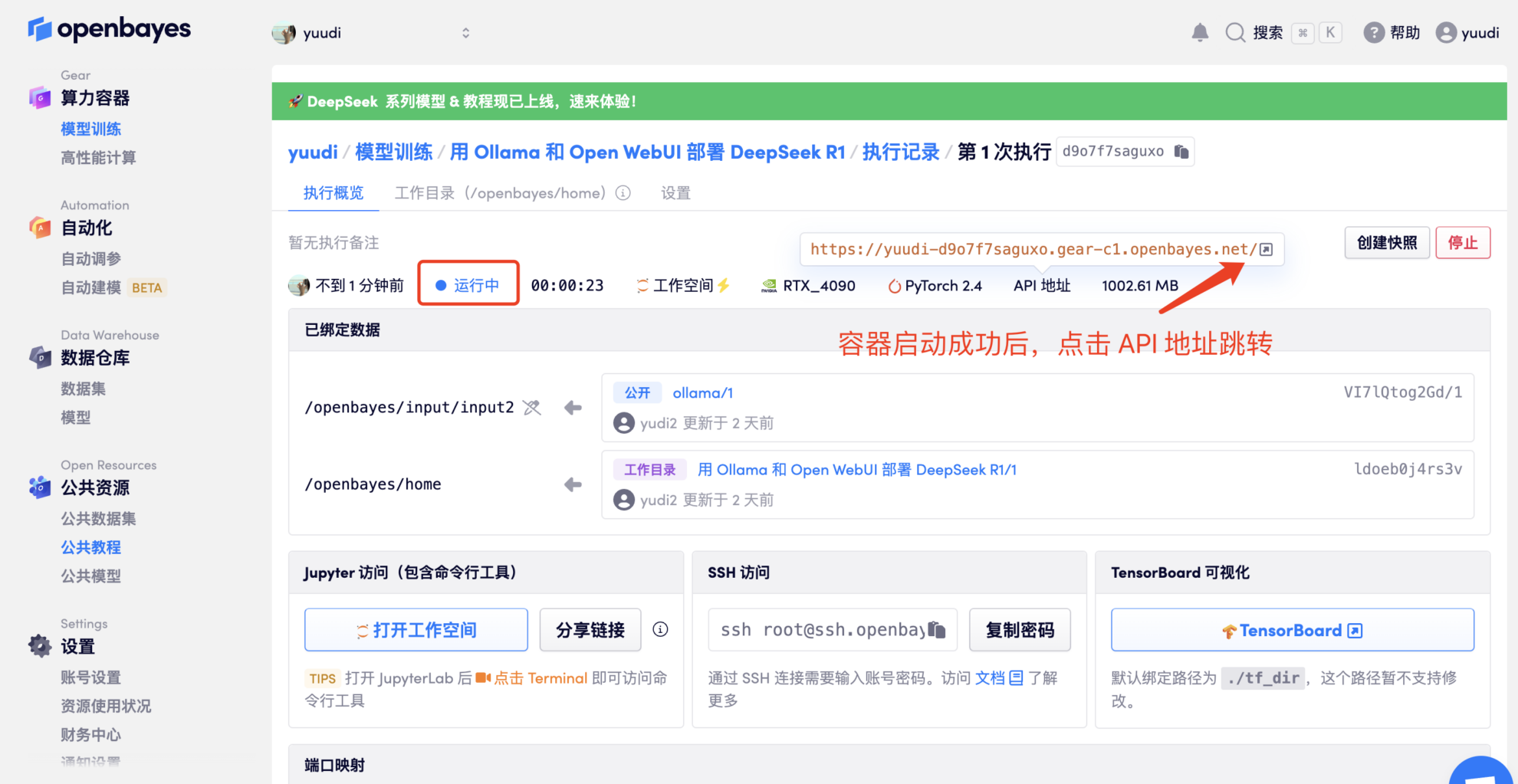
2. 进入网页后,即可与模型展开对话
注意:
- 本教程支持「联网搜索」,该功能开启后,推理速度会变慢,属于正常现象。
- 在界面左上角可以切换模型。
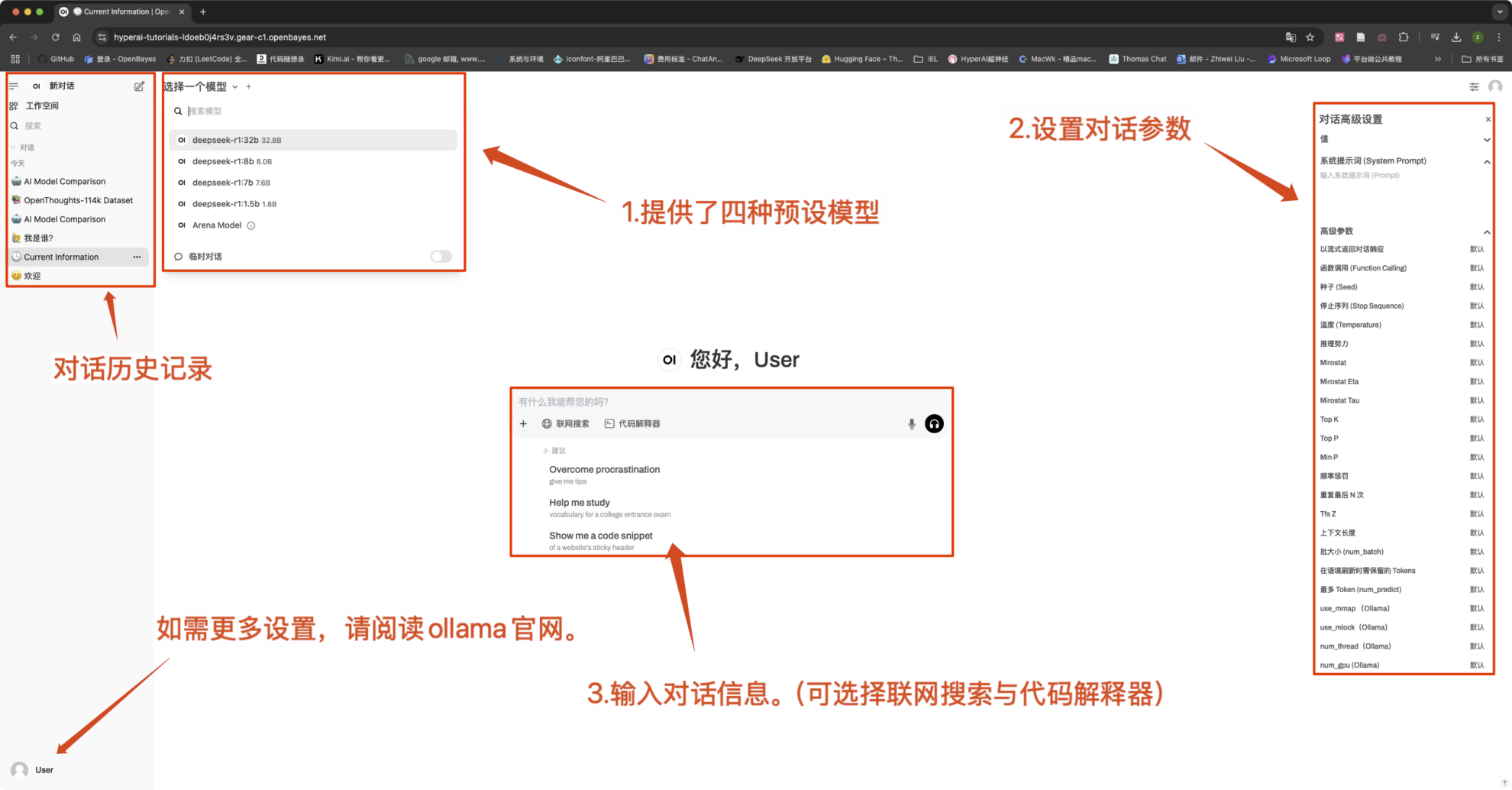
常见对话设置
1. Temperature(温度)
- 控制输出的随机性,范围一般在 0.0-2.0 之间。
- 低值(如 0.1):更确定,偏向常见词汇。
- 高值(如 1.5):更随机,可能生成更有创意但不稳定的内容。
2. Top-k Sampling(Top-k 采样)
- 只从 概率最高的 k 个 词中采样,排除低概率词汇。
- k 值小(如 10):更确定,减少偶然性。
- k 值大(如 50):更多样,增加创新性。
3. Top-p Sampling(Nucleus Sampling,Top-p 采样)
- 选择累计概率达到 p 的词集,不固定 k 值。
- 低值(如 0.3):更确定,减少偶然性。
- 高值(如 0.9):更多样,提升流畅度。
4. Repetition Penalty(重复惩罚)
- 控制文本重复度,通常在 1.0-2.0 之间。
- 值高(如 1.5):减少重复,提升可读性。
- 值低(如 1.0):无惩罚,可能导致模型重复词句。
5. Max Tokens(最大生成长度)
- 限制模型最多生成的 token 数,避免超长输出。
- 典型范围:50-4096(依赖具体模型)。
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。