Command Palette
Search for a command to run...
vLLM 入门教程:零基础分步指南

目录
- 1. Tutorial Introduction
- 2. Installing vLLM
- 3. Getting Started
- 4. Launching the vLLM Server
- 5. Sending Requests
一、教程简介
vLLM (Virtual Large Language Model) 是一款专为大语言模型推理加速而设计的框架,其依靠卓越的推理效率和资源优化能力在全球范围内引发广泛关注。来自加州大学伯克利分校 (UC Berkeley) 的研究团队于 2023 年提出了开创性注意力算法 PagedAttention,其可以有效地管理注意力键和值。在此基础上,研究人员构建了高吞吐量的分布式 LLM 服务引擎 vLLM,实现了 KV 缓存内存几乎零浪费,解决了大语言模型推理中的内存管理瓶颈问题。与 Hugging Face Transformers 相比,其吞吐量提升了 24 倍,而且这一性能提升不需要对模型架构进行任何更改。相关论文成果为「Efficient Memory Management for Large Language Model Serving with PagedAttention」。
在本教程中,将逐步展示如何配置和运行 vLLM,提供从安装到启动的完整入门指南。
本教程将使用 Qwen3-0.6B 进行演示,同时提供了其他参数量的模型。
二、安装 vLLM
本平台已完成 vllm==0.8.5 的安装。如果您在平台上操作,请跳过此步骤。如果您在本地部署,请按照以下步骤进行安装。
安装 vLLM 非常简单:
pip install vllm请注意,vLLM 是使用 CUDA 12.4 编译的,因此您需要确保机器运行的是该版本的 CUDA 。
检查 CUDA 版本,运行:
nvcc --version如果您的 CUDA 版本不是 12.4,您可以安装与您当前 CUDA 版本兼容的 vLLM 版本(更多信息请参考安装说明),或者安装 CUDA 12.4 。
三、开始使用
3.1 模型准备
方法一:使用平台公共模型
首先,我们可以检查平台的公共模型是否已经存在。如果模型已上传到公共资源库,您可以直接使用。如果没有找到,则请参考方法二进行下载。
例如,平台已存放了 Qwen3 系列模型。以下是绑定模型的步骤(本教程已绑定此模型)。
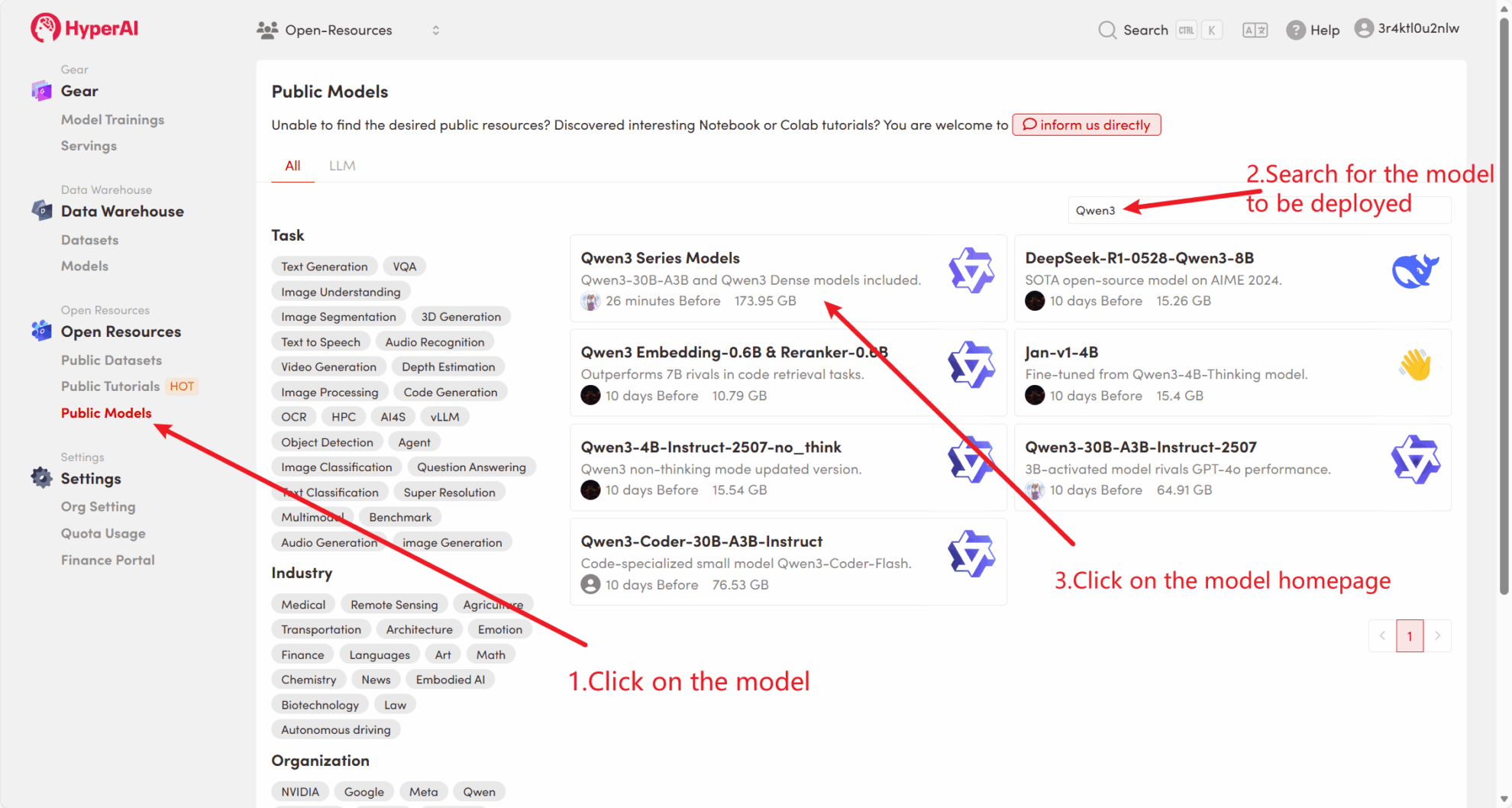
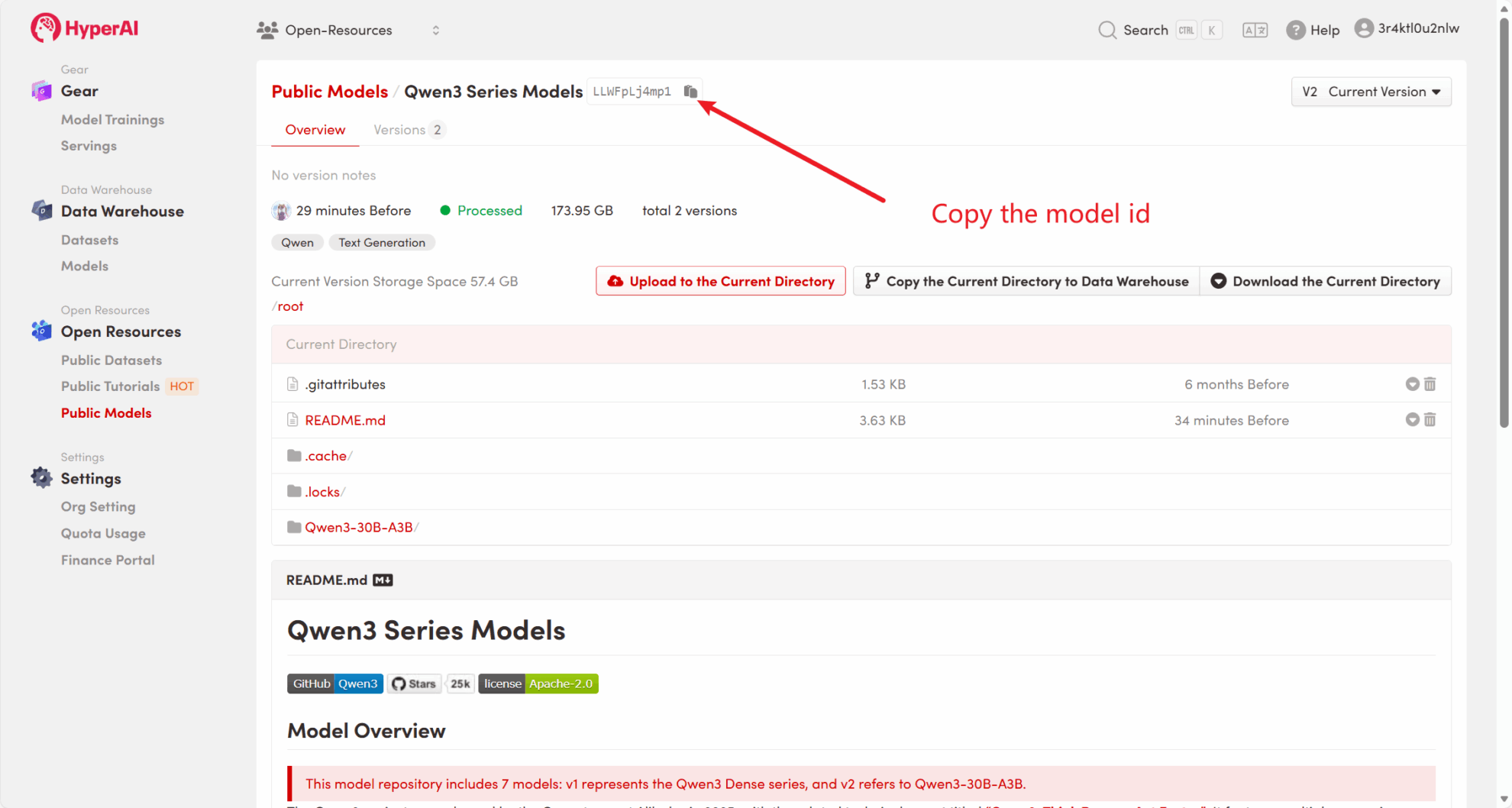
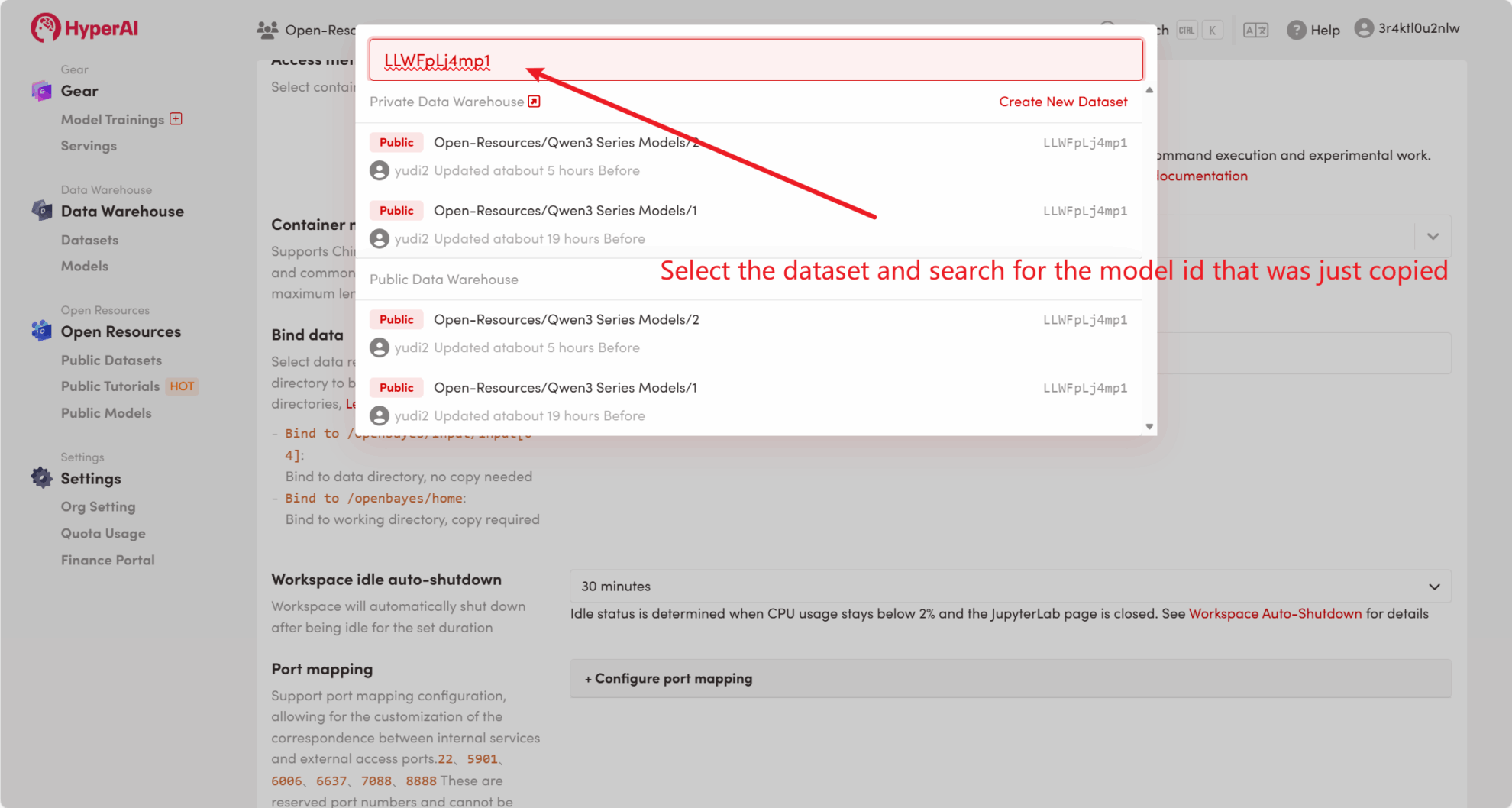
方法二:从 HuggingFace 下载 或联系客服帮忙上传平台
大多数主流模型都可以在 HuggingFace 上找到,vLLM 支持的模型列表请参见官方文档: vllm-supported-models 。
请按照以下步骤使用 huggingface-cli 下载模型:
huggingface-cli download --resume-download Qwen/Qwen3-0.6B --local-dir ./input03.2 离线推理
vLLM 作为一个开源项目,可以通过其 Python API 执行 LLM 推理。以下是一个简单的示例,请将代码保存为 offline_infer.py 文件:
from vllm import LLM, SamplingParams
# 输入几个问题
prompts = [
"Hello, who are you??",
"Where is the capital of France??",]
# 设置初始化采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)
# 加载模型,确保路径正确
llm = LLM(model="/input1/Qwen3-0.6B/", trust_remote_code=True, max_model_len=4096)
# 展示输出结果
outputs = llm.generate(prompts, sampling_params)
# 打印输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
然后运行脚本:
python offline_infer.py模型加载后,您将看到以下输出:

四、启动 vLLM 服务器
要使用 vLLM 提供在线服务,您可以启动与 OpenAI API 兼容的服务器。成功启动后,您可以像使用 GPT 一样使用部署的模型。
4.1 主要参数设置
以下是启动 vLLM 服务器时常用的一些参数:
--model:要使用的 HuggingFace 模型名称或路径(默认值:facebook/opt-125m)。--host和--port:指定服务器地址和端口。--dtype:模型权重和激活的精度类型。可能的值:auto、half、float16、bfloat16、float、float32。默认值:auto。--tokenizer:要使用的 HuggingFace 标记器名称或路径。如果未指定,默认使用模型名称或路径。--max-num-seqs:每次迭代的最大序列数。--max-model-len:模型的上下文长度,默认值自动从模型配置中获取。--tensor-parallel-size、-tp:张量并行副本数量(对于 GPU)。默认值:1。--distributed-executor-backend=ray:指定分布式服务的后端,可能的值:ray、mp。默认值:ray(当使用超过一个 GPU 时,自动设置为ray)。
4.2 启动命令行
创建兼容 OpenAI API 接口的服务器。运行以下命令启动服务器:
python3 -m vllm.entrypoints.openai.api_server --model /input1/Qwen3-0.6B/ --host 0.0.0.0 --port 8080 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-code成功启动后,您将看到类似以下的输出:

vLLM 现在可以作为实现 OpenAI API 协议的服务器进行部署,默认情况下它将在 http://localhost:8080 启动服务器。您可以通过 --host 和 --port 参数指定其他地址。
五、发出请求
在本教程中启动的 API 地址是 http://localhost:8080,您可以通过访问该地址来使用 API 。 localhost 指平台本机,8080 是 API 服务监听的端口号。
在工作空间右侧,API 地址将转发到本地 8080 服务,可以通过真实主机进行请求,如下图所示:
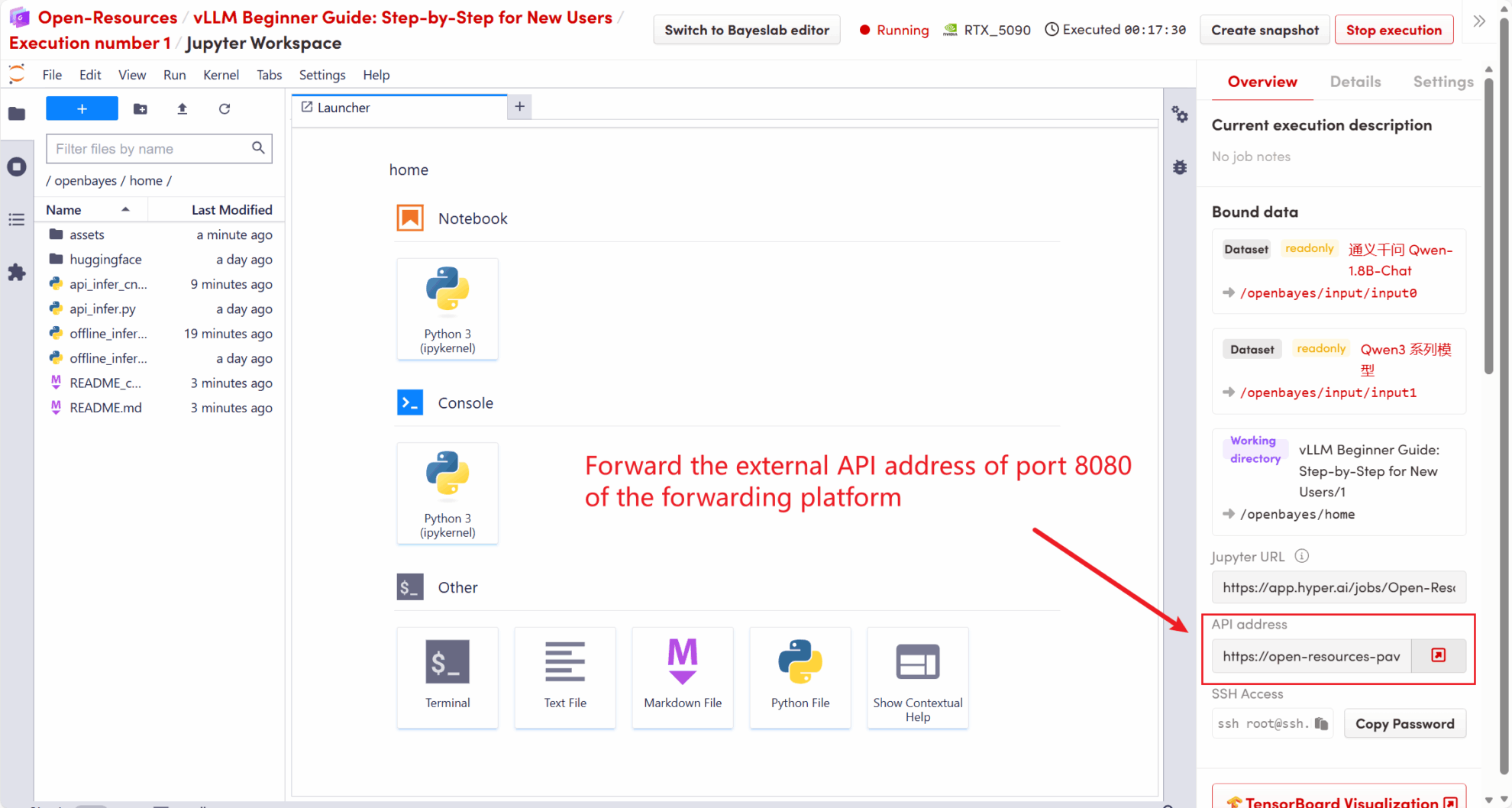
5.1 使用 OpenAI 客户端
在第四步中启动 vLLM 服务后,您可以通过 OpenAI 客户端调用 API 。以下是一个简单的示例:
# 注意:请先安装 openai
# pip install openai
from openai import OpenAI
# 设置 OpenAI API 密钥和 API 基础地址
openai_api_key = "EMPTY" # 请替换为您的 API 密钥
openai_api_base = "http://localhost:8080/v1" # 本地服务地址
client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)
models = client.models.list()
model = models.data[0].id
prompt = "Describe the autumn in Beijing"
# Completion API 调用
completion
= client.completions.create(model=model, prompt=prompt)
res = completion.choices[0].text.strip()
print(f"Prompt: {prompt}\nResponse: {res}")执行命令:
python api_infer.py您将看到如下输出结果:

5.2 使用 Curl 命令请求
您也可以使用以下命令直接发送请求。在平台上访问时,输入以下命令:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 512
}'您将得到如下响应:

如果您使用的是 OpenBayes 平台,输入以下命令:
curl https://hyperai-tutorials-8tozg9y9ref9.gear-c1.openbayes.net/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 128
}'响应结果如下:
