Command Palette
Search for a command to run...
GLM-4-Voice 端到端中英语音对话模型
一、教程简介
GLM-4-Voice 是智谱 AI 于 2024 年推出的端到端语音模型。 GLM-4-Voice 能够直接理解和生成中英文语音,进行实时语音对话,并且能够遵循用户的指令要求改变语音的情感、语调、语速、方言等属性。
该教程 Demo 包含模型的两个功能实现:「语音对话」和「文本对话」。
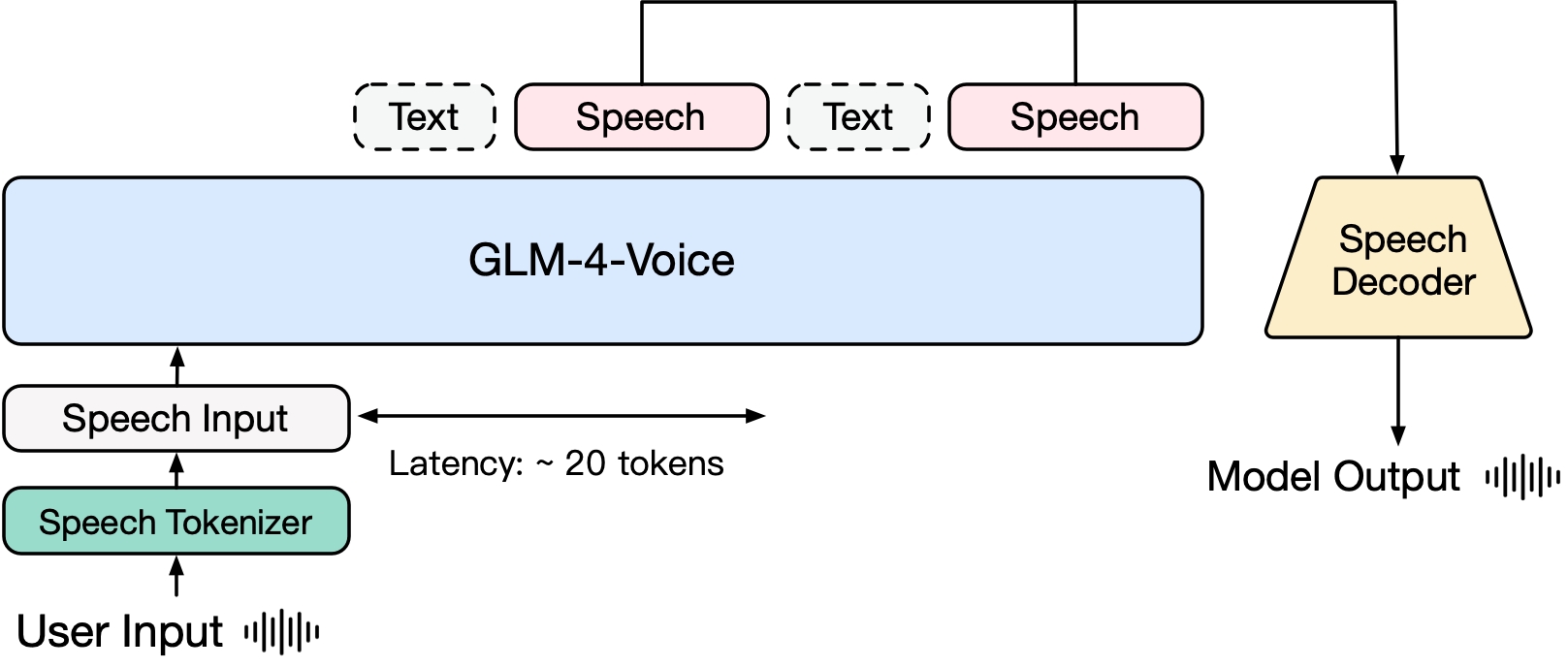
GLM-4-Voice 由三个部分组成:
- GLM-4-Voice-Tokenizer: 通过在 Whisper 的 Encoder 部分增加 Vector Quantization 并在 ASR 数据上有监督训练,将连续的语音输入转化为离散的 token 。每秒音频平均只需要用 12.5 个离散 token 表示。
- GLM-4-Voice-Decoder: 基于 CosyVoice 的 Flow Matching 模型结构训练的支持流式推理的语音解码器,将离散化的语音 token 转化为连续的语音输出。最少只需要 10 个语音 token 即可开始生成,降低端到端对话延迟。
- GLM-4-Voice-9B: 在 GLM-4-9B 的基础上进行语音模态的预训练和对齐,从而能够理解和生成离散化的语音 token 。
预训练方面,为了攻克模型在语音模态下的智商和合成表现力两个难关,研究团队将 Speech2Speech 任务解耦合为「根据用户音频做出文本回复」和「根据文本回复和用户语音合成回复语音」两个任务,并设计 2 种预训练目标,分别基于文本预训练数据和无监督音频数据合成语音-文本交错数据以适配这两种任务形式。 GLM-4-Voice-9B 在 GLM-4-9B 的基座模型基础之上,经过了数百万小时音频和数千亿 tokens 的音频文本交错数据预训练,拥有很强的音频理解和建模能力。
对齐方面,为了支持高质量的语音对话,研究团队设计了一套流式思考架构:根据用户语音,GLM-4-Voice 可以流式交替输出文本和语音两个模态的内容,其中语音模态以文本作为参照保证回复内容的高质量,并根据用户的语音指令要求做出相应的声音变化,在最大程度保留语言模型智商的情况下仍然具有端到端建模的能力,同时具备低延迟性,最低只需要输出 20 个 token 便可以合成语音。
二、运行步骤
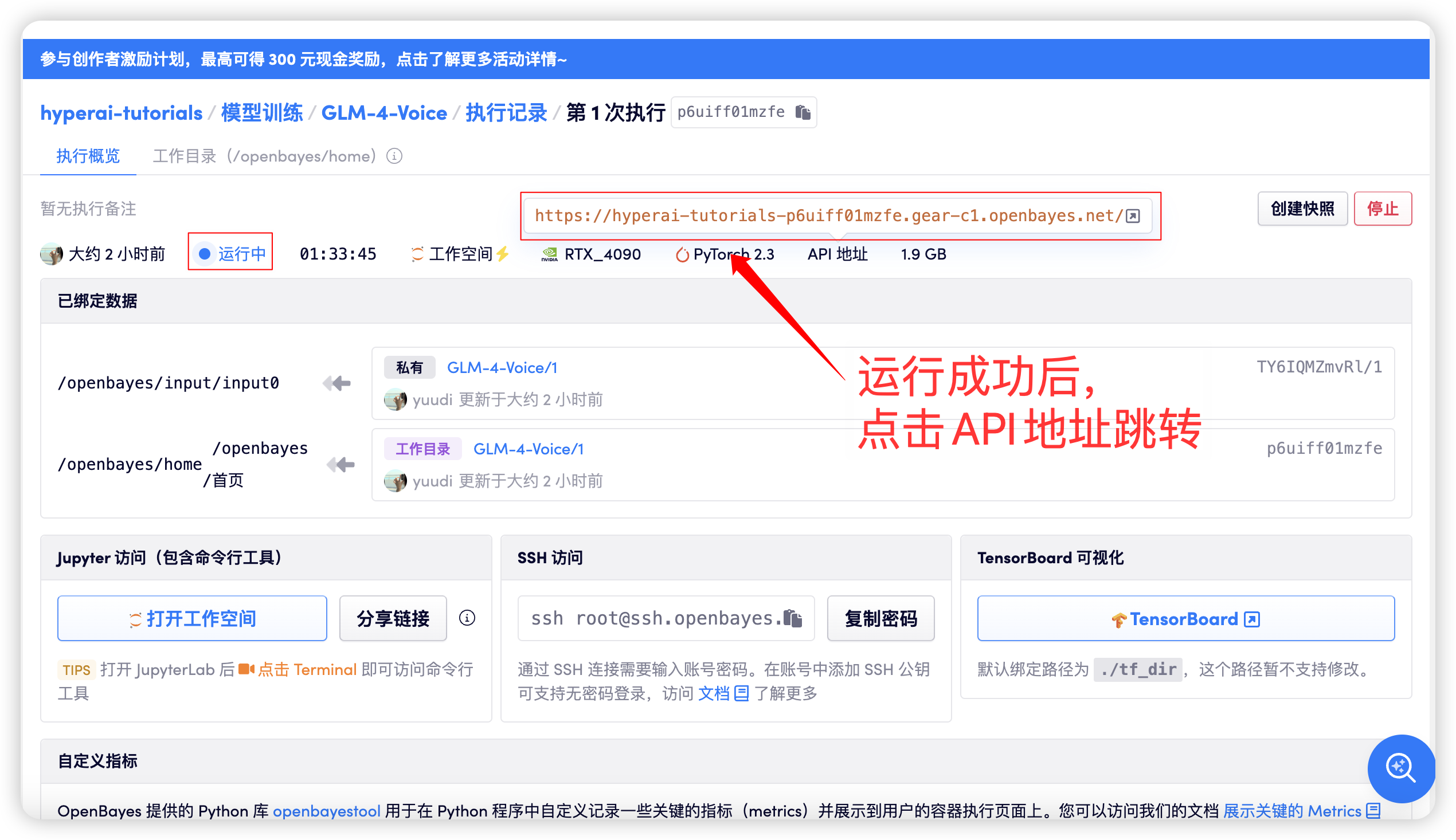
启动容器后点击 API 地址即可进入 Web 界面
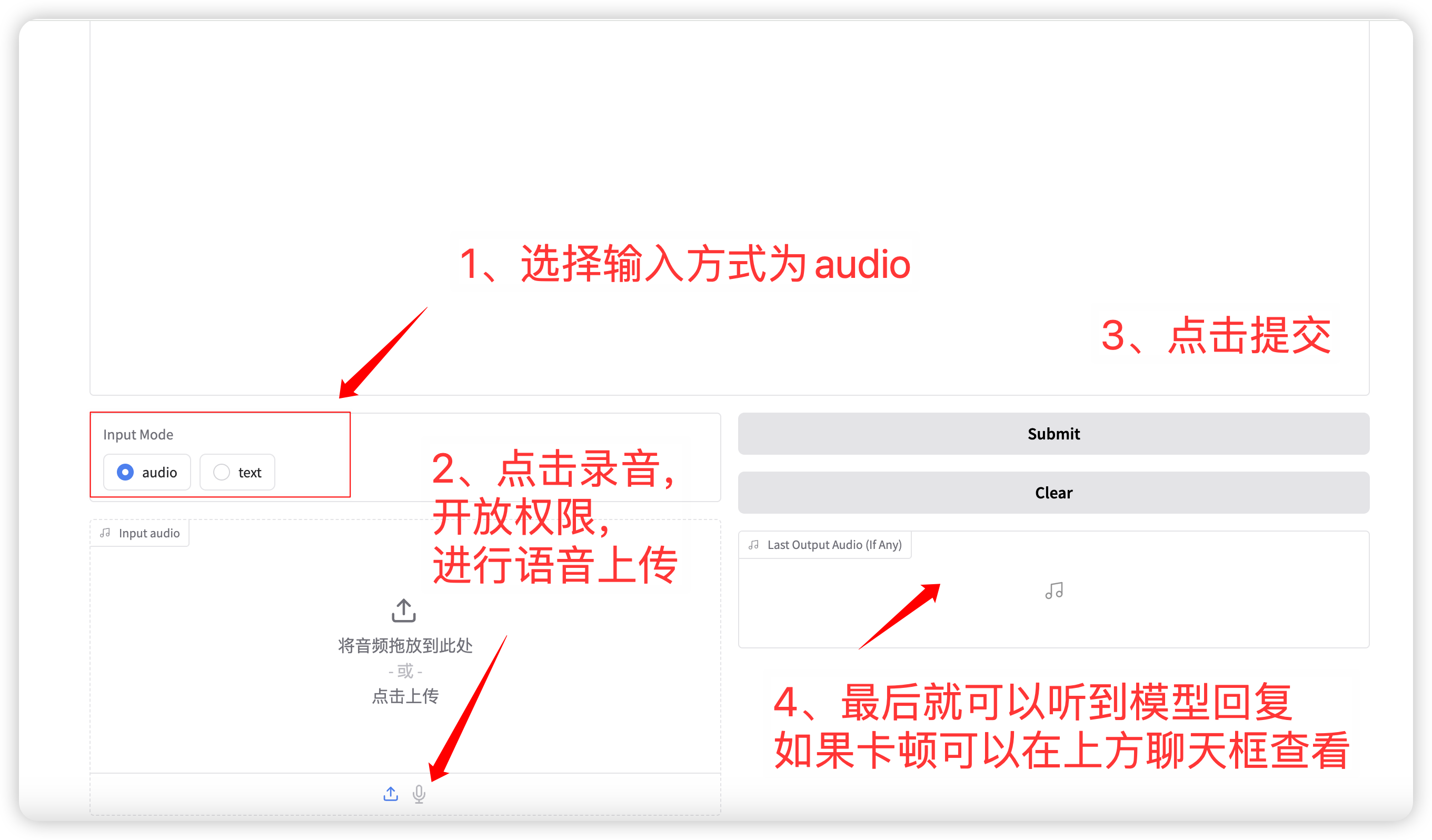
1. 语音对话
输入模式选择 audio 功能,点击录音或者上传语音文件。 相关的采样参数为:
- Temperature:范围 0-1,温度越高生成的随机性越大!
- Top p:用于指定在生成过程中选择下一个单词时,只有概率最高的前 p 个选项会被考虑。这有助于在生成文本时保持多样性,避免总是选择概率最高的预测结果,从而使得生成的文本更加丰富和多样化。
- Max new tokens:最大生成的 tokens 数。
完成设置后,模型会实时输出语音和文本,但是由于网络延迟可能会断断续续,可以听取聊天框内的语音。 整体页面布局如下:
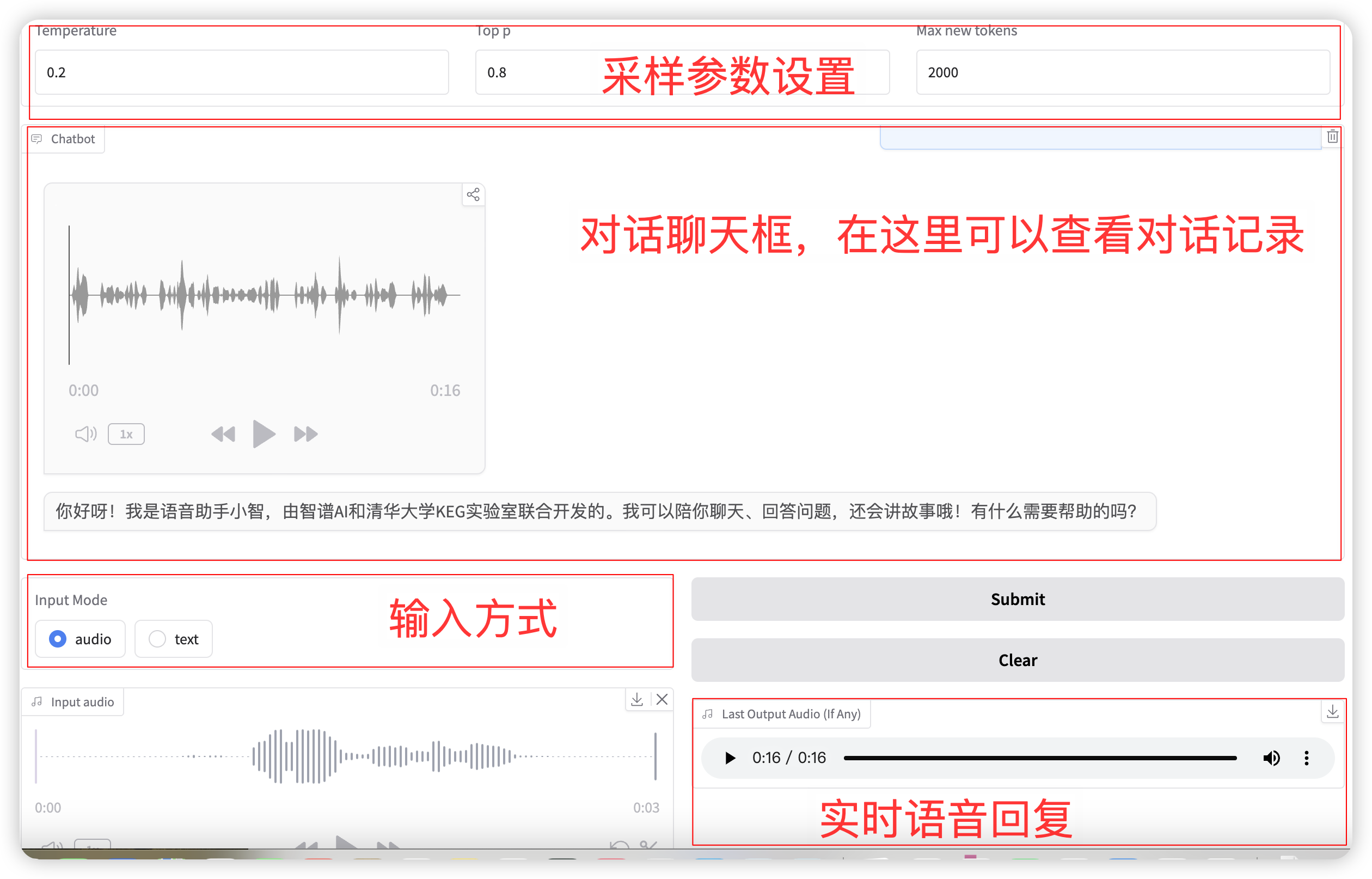
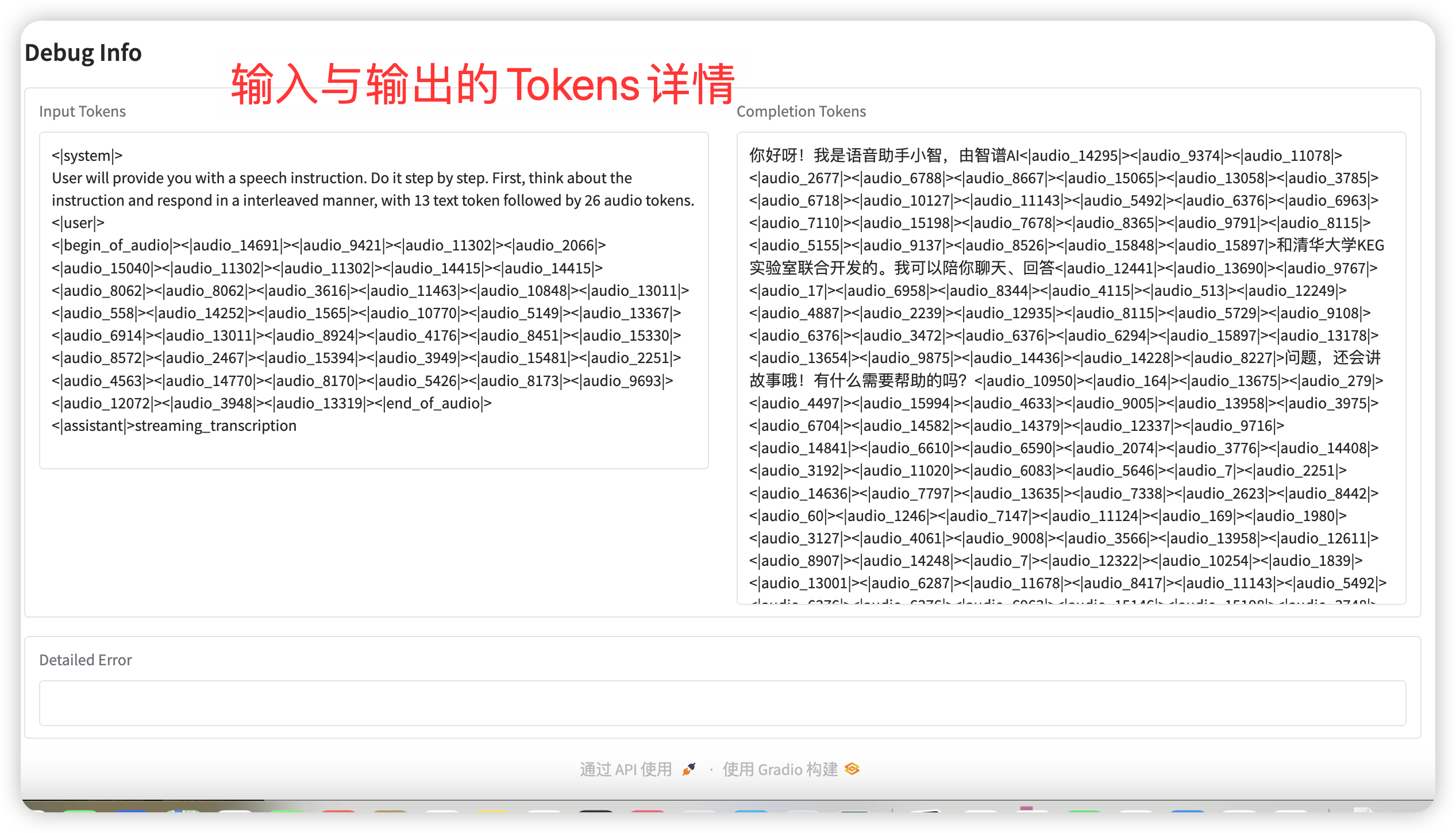
语音对话流程
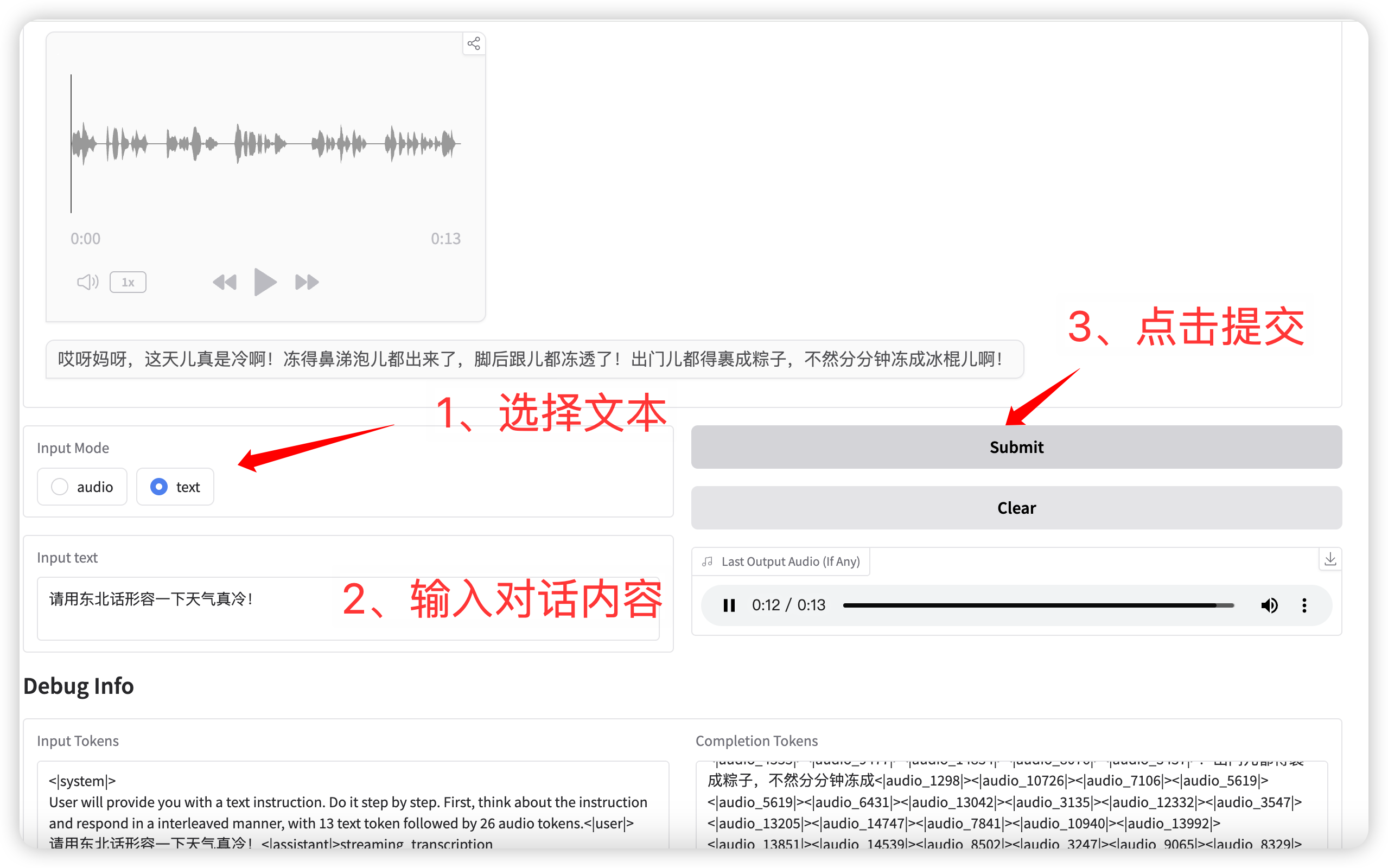
2. 文本对话
输入模式选择 **text** 功能,输入对话文本。
点击提交后,模型同时输出文本和语音。
语音对话(输入为文本)
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓
