Command Palette
Search for a command to run...
Whisper-large-v3-turbo 语音识别、翻译 Demo

一、教程简介
Whisper 是一种通用语音识别模型。它基于大量多样化音频数据集进行训练,可以执行多语言语音识别和语音翻译等多任务。
- 多语言语音识别:自动识别音频中的语言并转为原音频中的语言进行输出
- 语言翻译:在识别的基础上,将语言翻译为中文(默认)进行输出
OpenAI 在 2024 年 10 月 1 日举办的 DevDay 活动日中,宣布推出了 Whisper large-v3-turbo 语音转录模型,共有 8.09 亿参数,在质量几乎没有下降的情况下,速度比 large-v3 快 8 倍
Whisper large-v3-turbo 语音转录模型是 large-v3 的优化版本,并且只有 4 层解码器层(Decoder Layers),作为对比 large-v3 共有 32 层。模型共有 8.09 亿参数,比 7.69 亿参数的 medium 模型稍大,不过比 15.5 亿参数的 large 模型小很多,并且所需的 VRAM 为 6 GB,而 large 模型需要 10 GB 。
二、运行步骤
启动容器后点击 API 地址即可进入 Web 界面
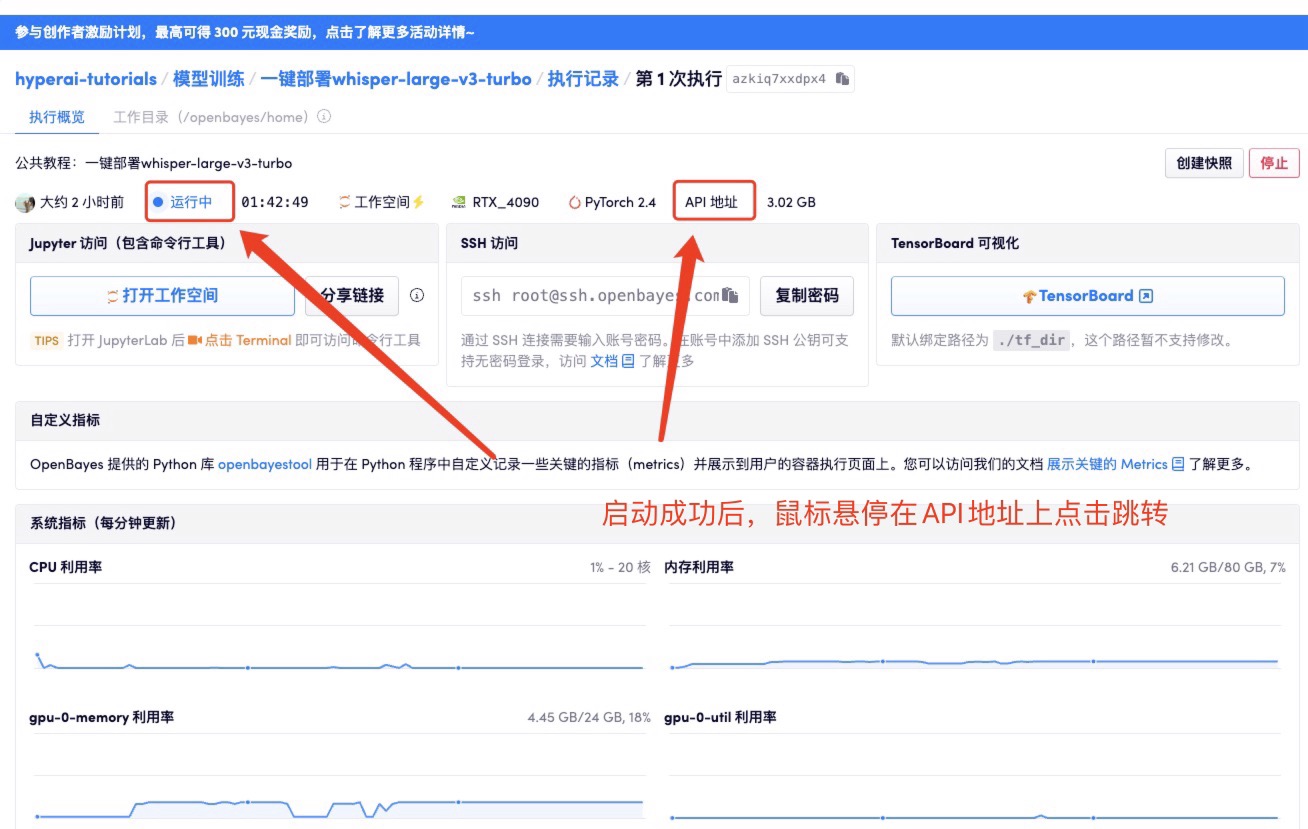
我们给出了三种使用功能进行语音识别 (transcribe) 或翻译 (translate):
- Microphone 直接使用设备进行实时录音
- Audio file 上传离线音频
- YouTube 在线视频
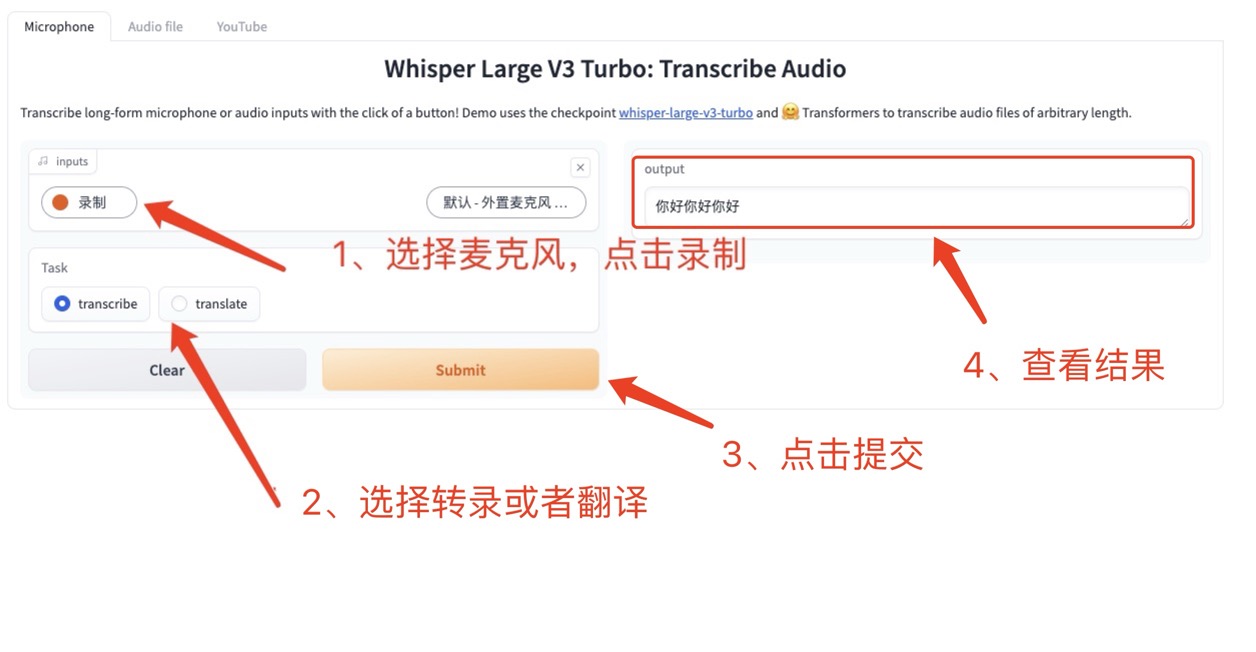
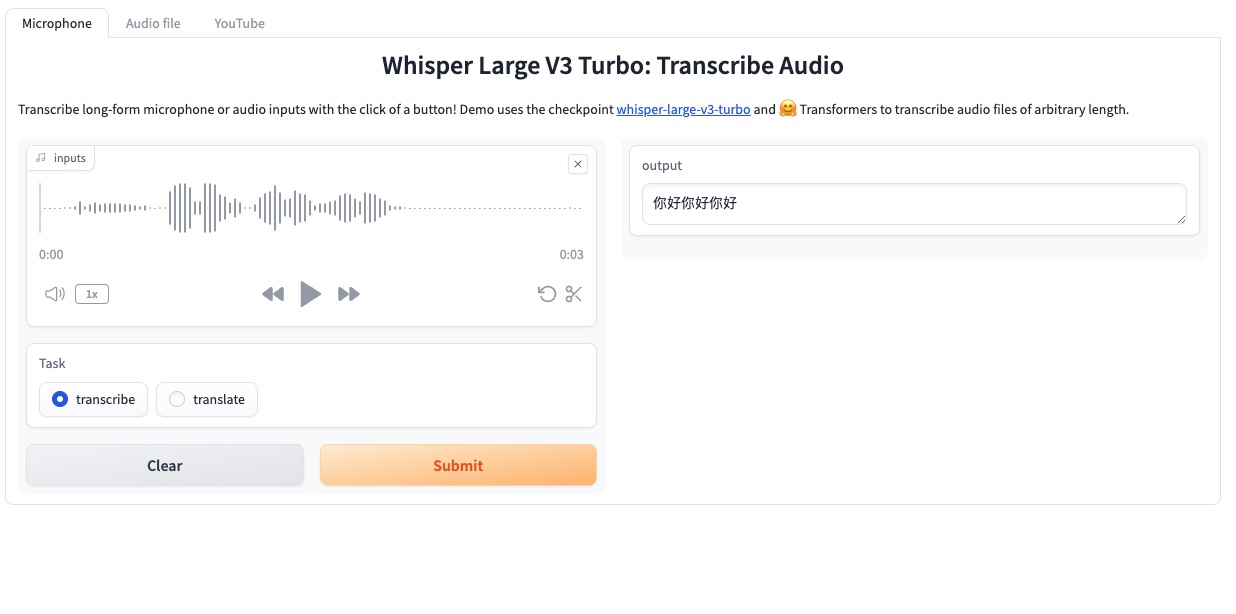
1 、 Microphone 直接使用设备进行实时录音
点击 Microphone(默认),使用设备麦克风进行音频录制,录制完成后会将音频上传到平台,选择转录或者翻译,而后点击 Submit 进行生成指定文本。(由于模型性能原因可能导致翻译不准确)
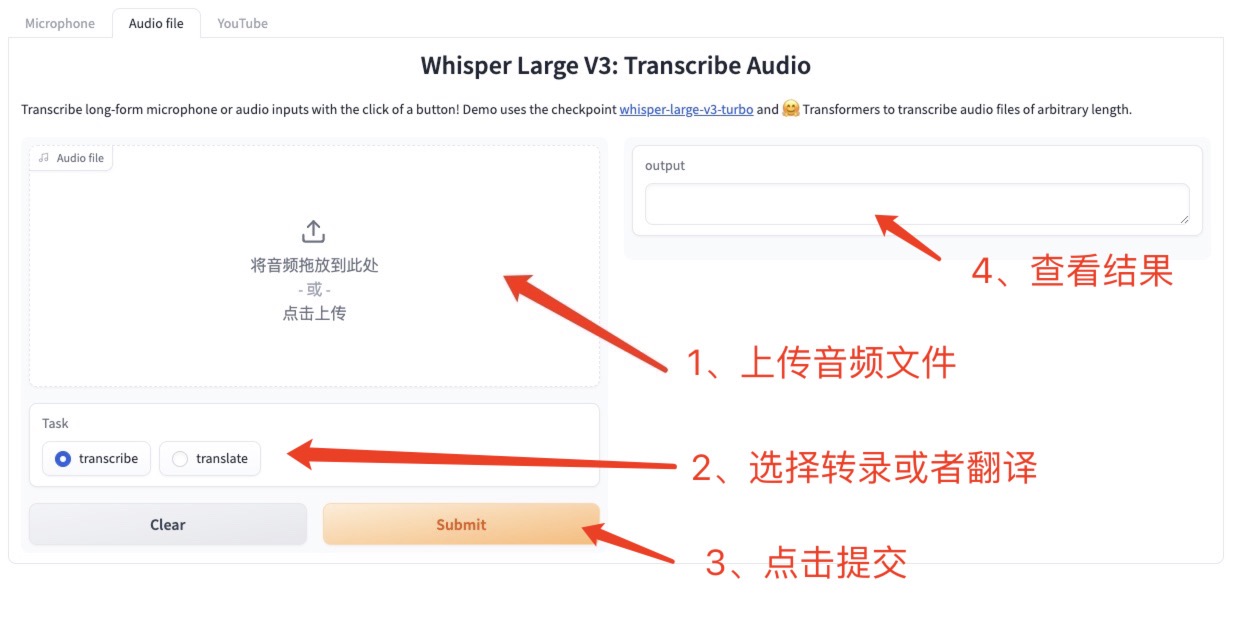
2 、 Audio file 上传离线音频
点击 Audio file,将要执行的音频上传或者拖拽到界面中,选择转录或者翻译,而后点击 Submit 进行生成指定文本。
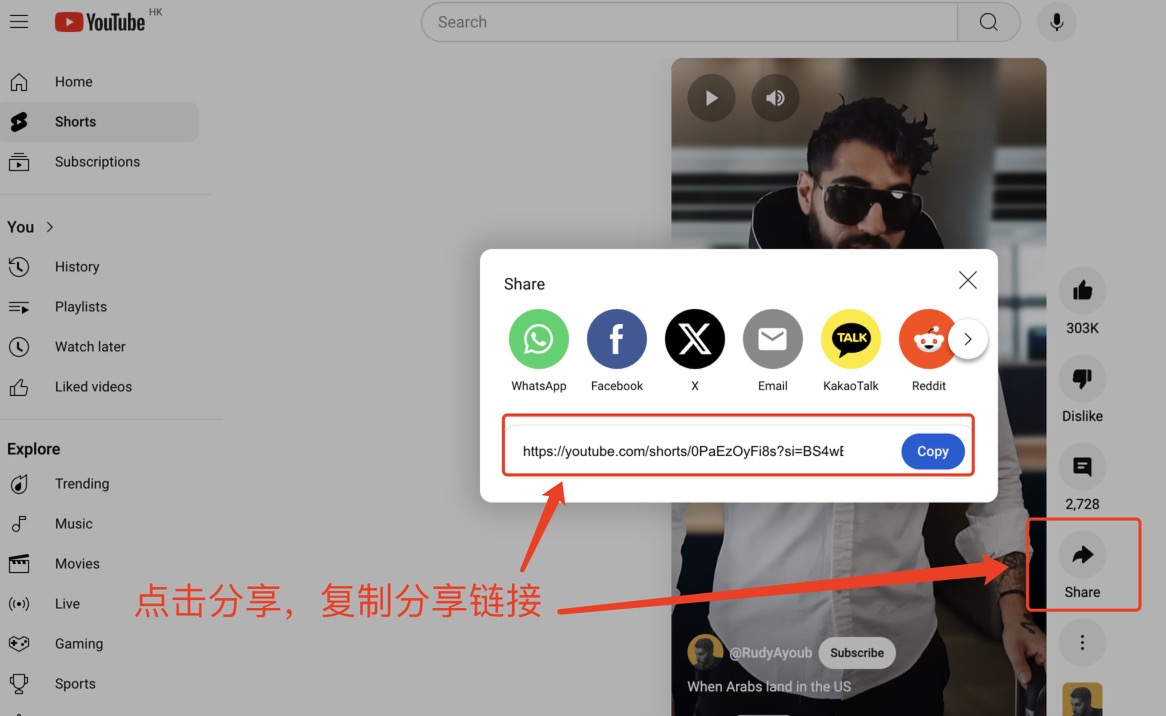
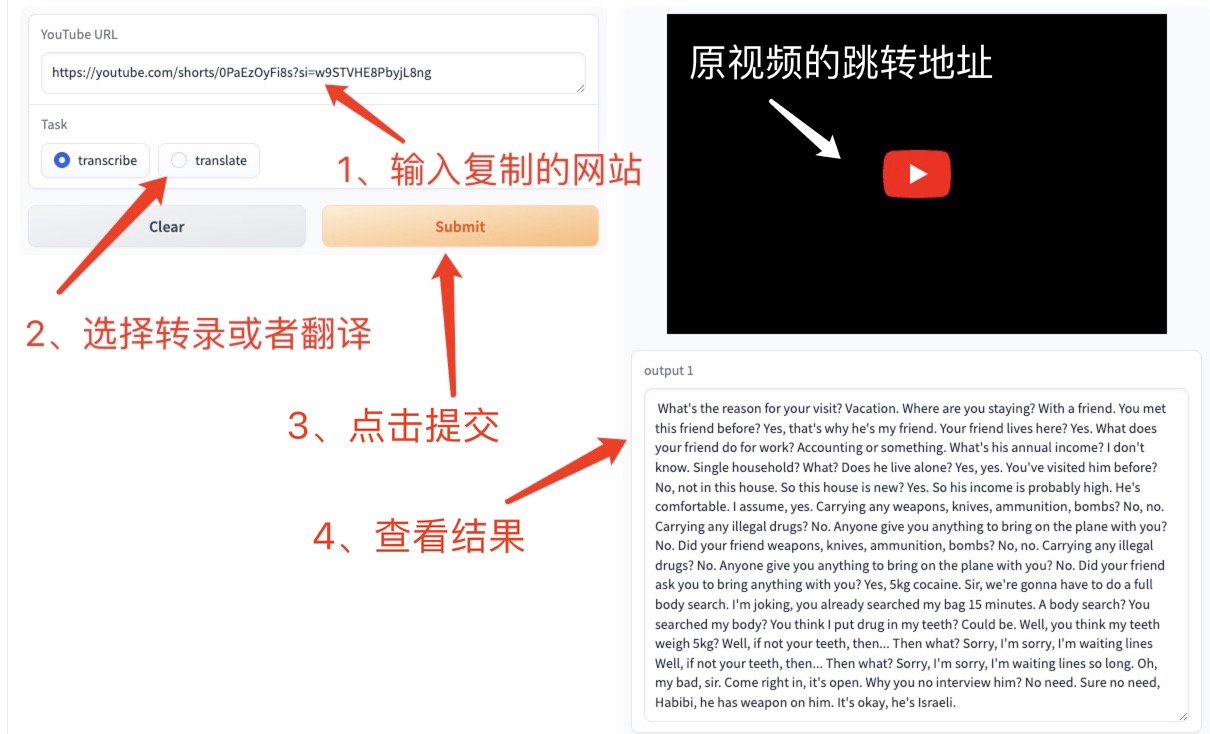
3 、 Youtube 在线视频(由于网络问题,可能会导致无法识别需要多次尝试。 Demo 仅供参考)
在浏览 Youtube 网页找到想要的视频,点击右侧分享会出现一个 url,将此 url 复制到网页中的文本框 YouTube URL 中,选择转录或者翻译,而后点击 Submit 进行生成指定文本。
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓
