HyperAI
Command Palette
Search for a command to run...
ShowUI:专注 GUI 自动化的视觉-语言-动作模型

一、教程简介

ShowUI 是由新加坡国立大学 Show Lab 和微软于 2024 年共同开发的视觉-语言-行动模型,专为图形用户界面 (GUI) 智能助手设计,旨在提高人类工作的效率。这个模型通过理解屏幕界面的内容,并执行如点击、输入、滚动等交互动作,支持网页和手机应用场景,能够自动完成复杂的用户界面任务。 ShowUI 能够解析屏幕截图和用户指令,进而预测出界面上的交互动作。相关论文成果为 ShowUI: One Vision-Language-Action Model for GUI Visual Agent 。已被 CVPR 2025 收录。
本教程默认使用资源为单卡 RTX 5090,最低可用单卡 RTX 4090 启动使用。
二、项目示例
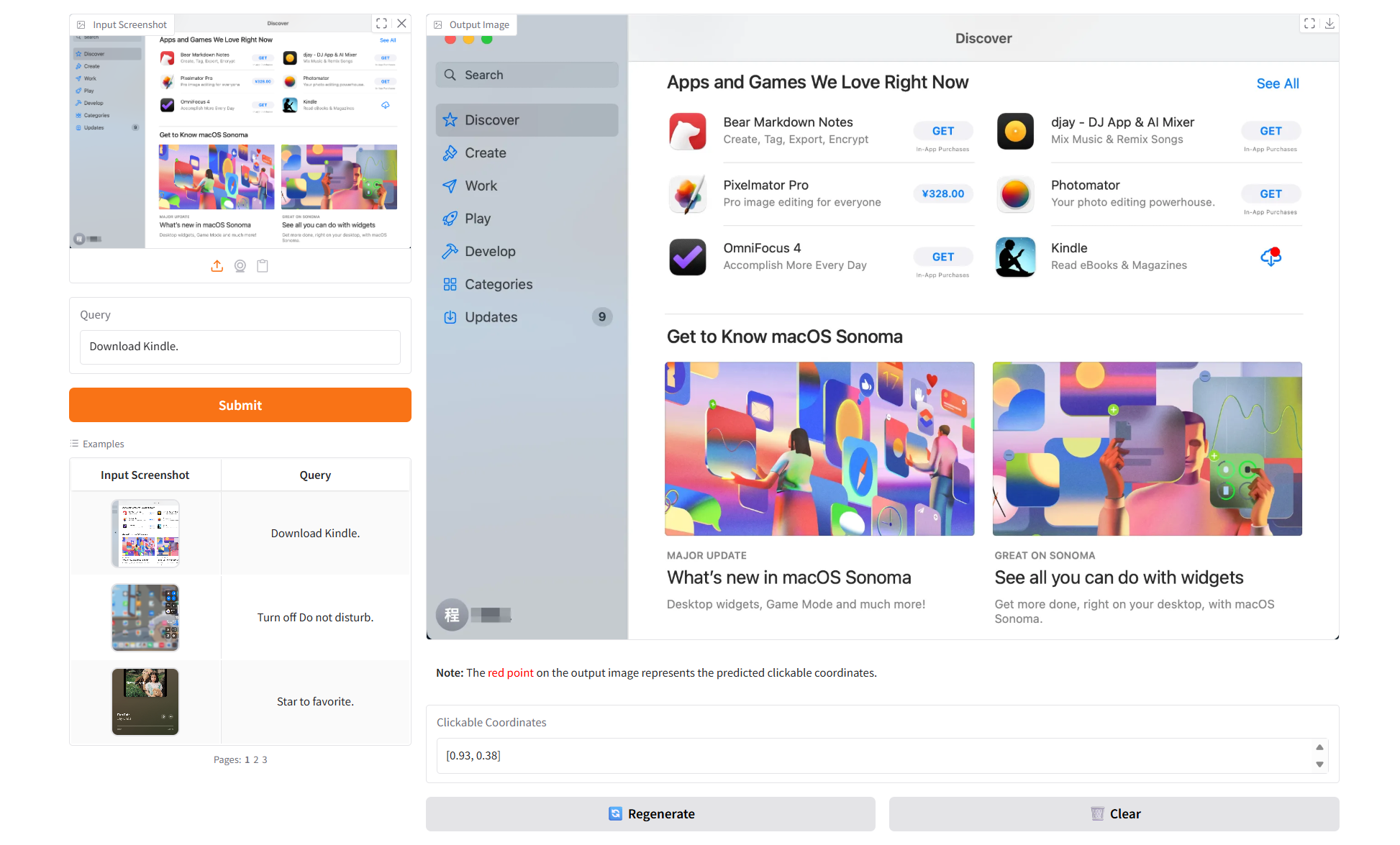
三、运行步骤
1. 启动容器后点击 API 地址即可进入 Web 界面
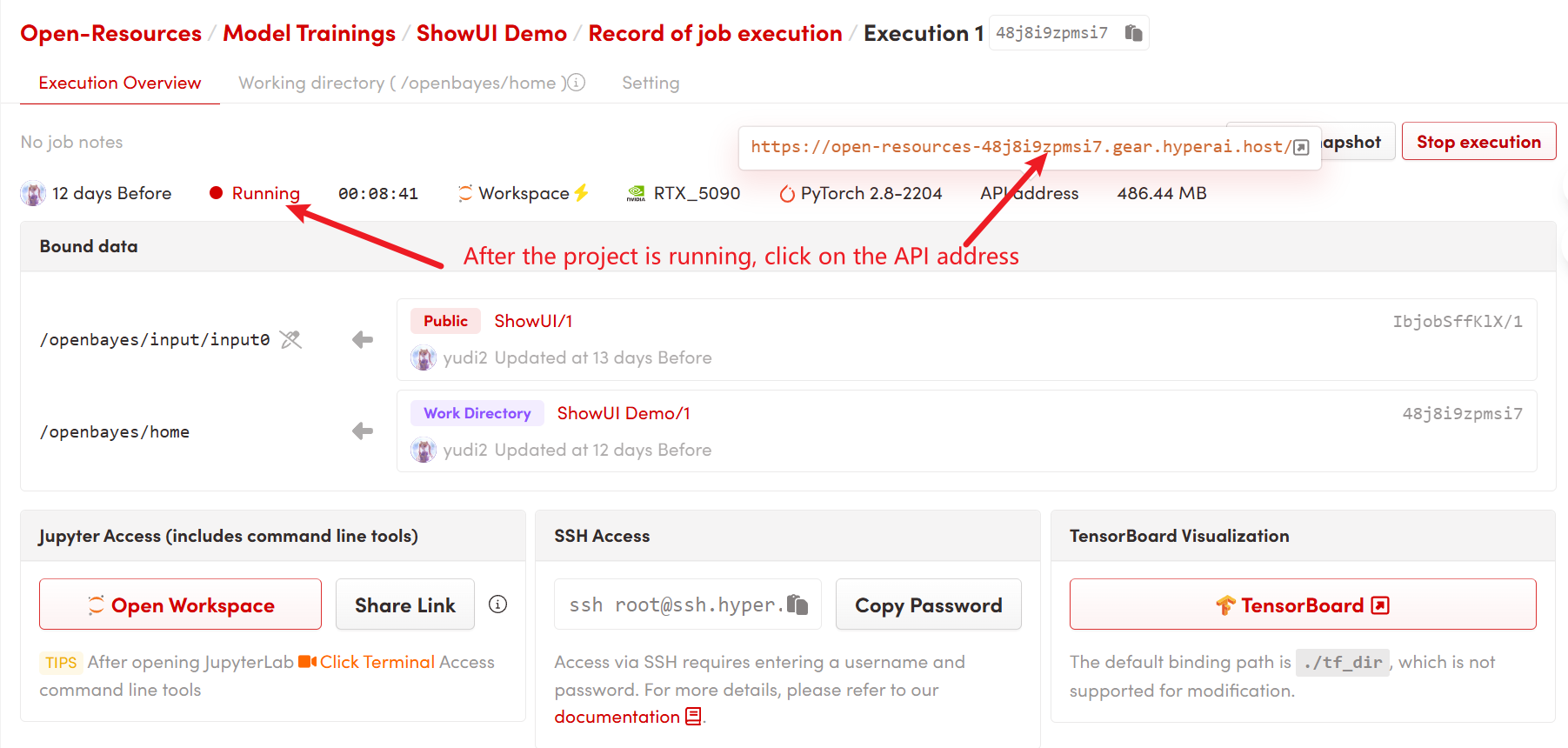
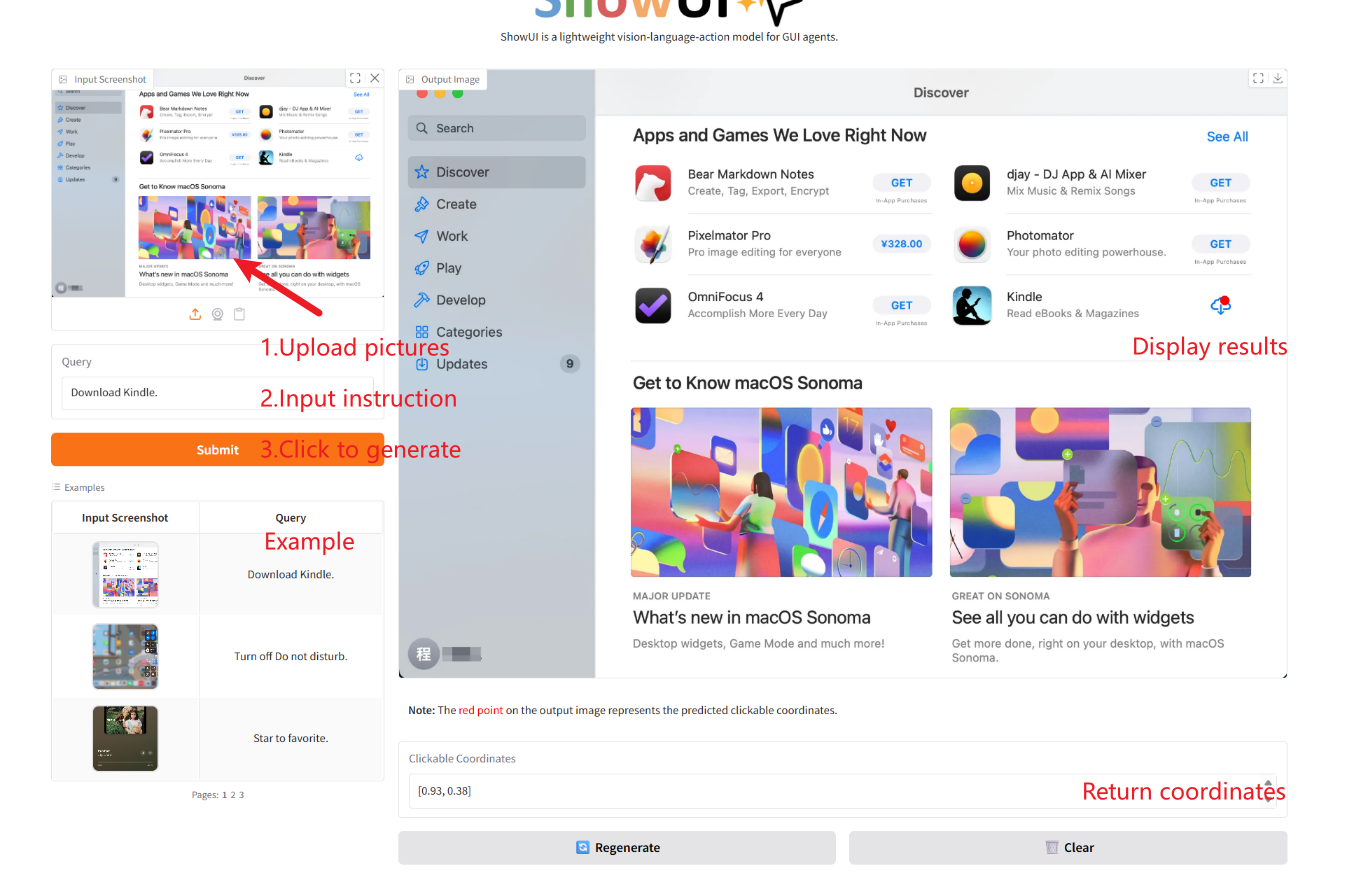
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
引用信息
@misc{lin2024showui,
title={ShowUI: One Vision-Language-Action Model for GUI Visual Agent},
author={Kevin Qinghong Lin and Linjie Li and Difei Gao and Zhengyuan Yang and Shiwei Wu and Zechen Bai and Weixian Lei and Lijuan Wang and Mike Zheng Shou},
year={2024},
eprint={2411.17465},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.17465},
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。