Command Palette
Search for a command to run...
Hunyuan3D:仅需 10 秒生成 3D 资产
腾讯 Hunyuan3D-1.0:文本转 3D 和图像转 3D 的统一框架


一、教程简介
Hunyuan3D-1.0 是由腾讯公司研究团队于 2024 年推出的 3D 生成扩散模型模型,包括一个轻量版和一个标准版,均支持从文本和图像输入生成高质量的 3D 资产,轻量版模型能在大约 10 秒内生成 3D 物体,而标准版则在大约 25 秒内完成,标准版本比精简版和其他现有模型多 3 倍参数。相关技术报告为 Tencent Hunyuan3D-1.0: A Unified Framework for Text-to-3D and Image-to-3D Generation 。
该框架框架涉及文本转图像模型,即 Hunyuan-DiT,Hunyuan3D-1.0 是一个统一的框架,可以应用于文本到 3D (Text-to-3D) 和图像到 3D (Image-to-3D) 的生成。模型采用两阶段方法进行 3D 资产的生成。第一阶段使用多视角扩散模型,大约在 4 秒内高效生成多视角 RGB 图像。第二阶段引入前馈重建模型,利用这些多视角图像在大约 3 秒内快速而准确地重建 3D 视图。该模型能够重建各种尺度的物体,从大型建筑到小型工具或花草都能轻松处理。它在两个公开的 3D 数据集——GSO 和 OmniObject3D 上的表现优于主流开源模型,整体能力属于国际领先水平。经过定性和定量的多维度评估,Hunyuan3D-1.0 在几何细节、纹理细节、纹理-几何一致性、 3D 合理性、指令遵循等方面的表现都非常出色。
Hunyuan3D-1.0 的发布,为 3D 创作者和艺术家提供了一个强大的工具,可以自动化生产 3D 资产,提高了 3D 生成的速度和泛化能力。
本教程是 Hunyuan3D-1.0 轻量版,使用了 3 个模型使 Web 界面包含 2 个功能:
两个功能:
- 图像生成 3D(image_to_3D)
- 文本转 3D(text_to_3D)
三个模型:
- Hunyuan3D-1/lite 用于多视图生成的精简模型
- Hunyuan3D-1/std 多视图生成的标准模型
- Hunyuan3D-1/svrm 稀疏视图重建模型
二、效果示例

三、运行步骤
启动容器后等待约 3 分钟(加载模型),点击 API 地址即可进入 Web 界面(否则将会显示 BadGateway)
1 、图像生成 3D(image_to_3d)
选择「Text to 3D」功能,按如下要求输入提示词和进行相关设置
如果需要生成 gif 必须选中「Render gif」,否则不会生成效果。其他功能无需选中
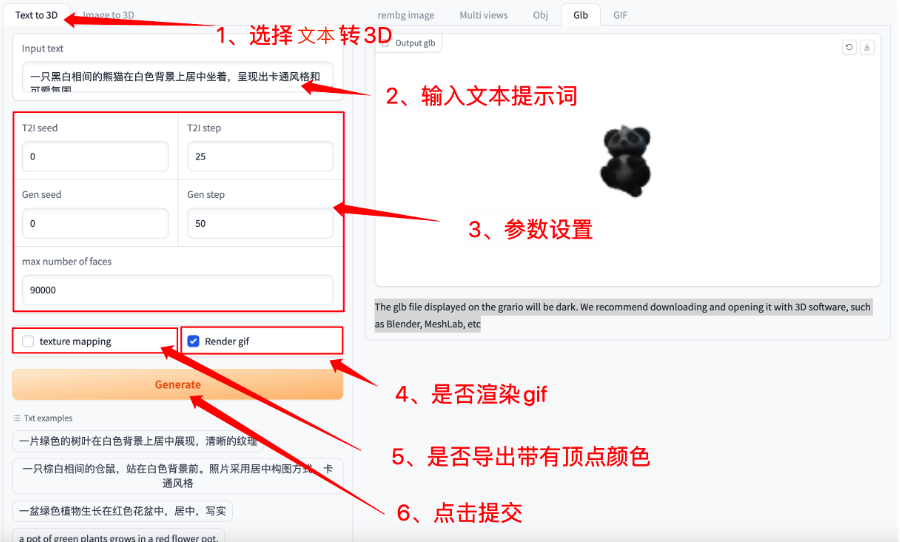
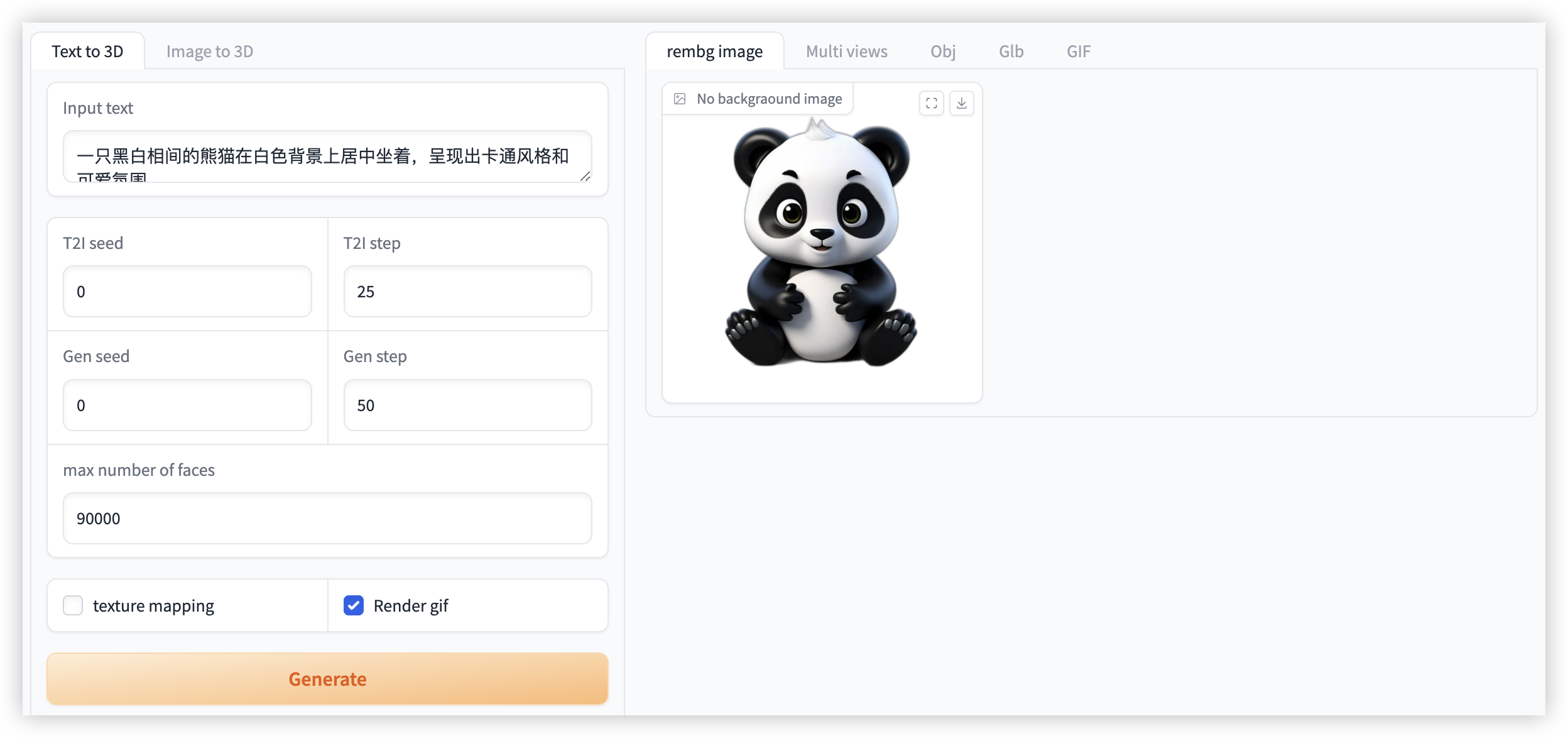
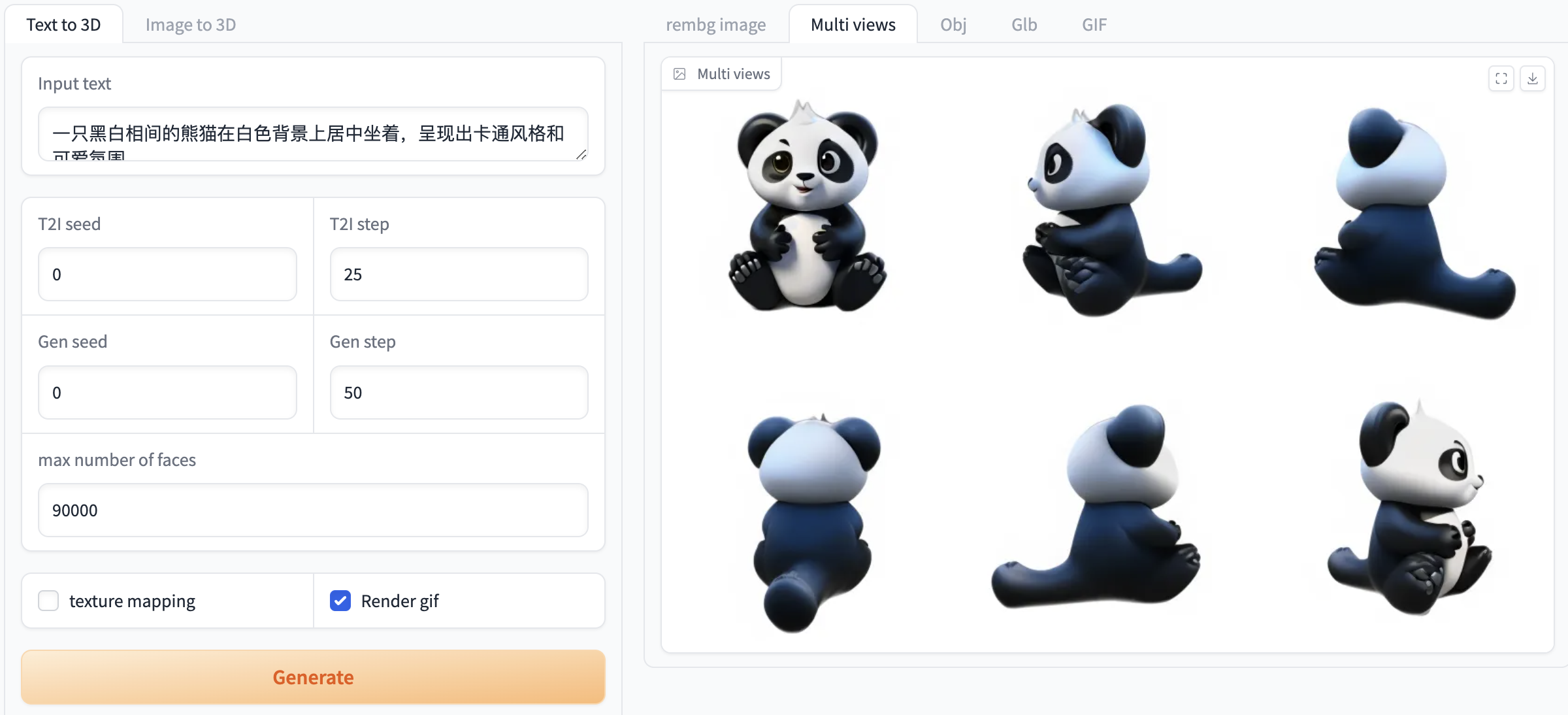
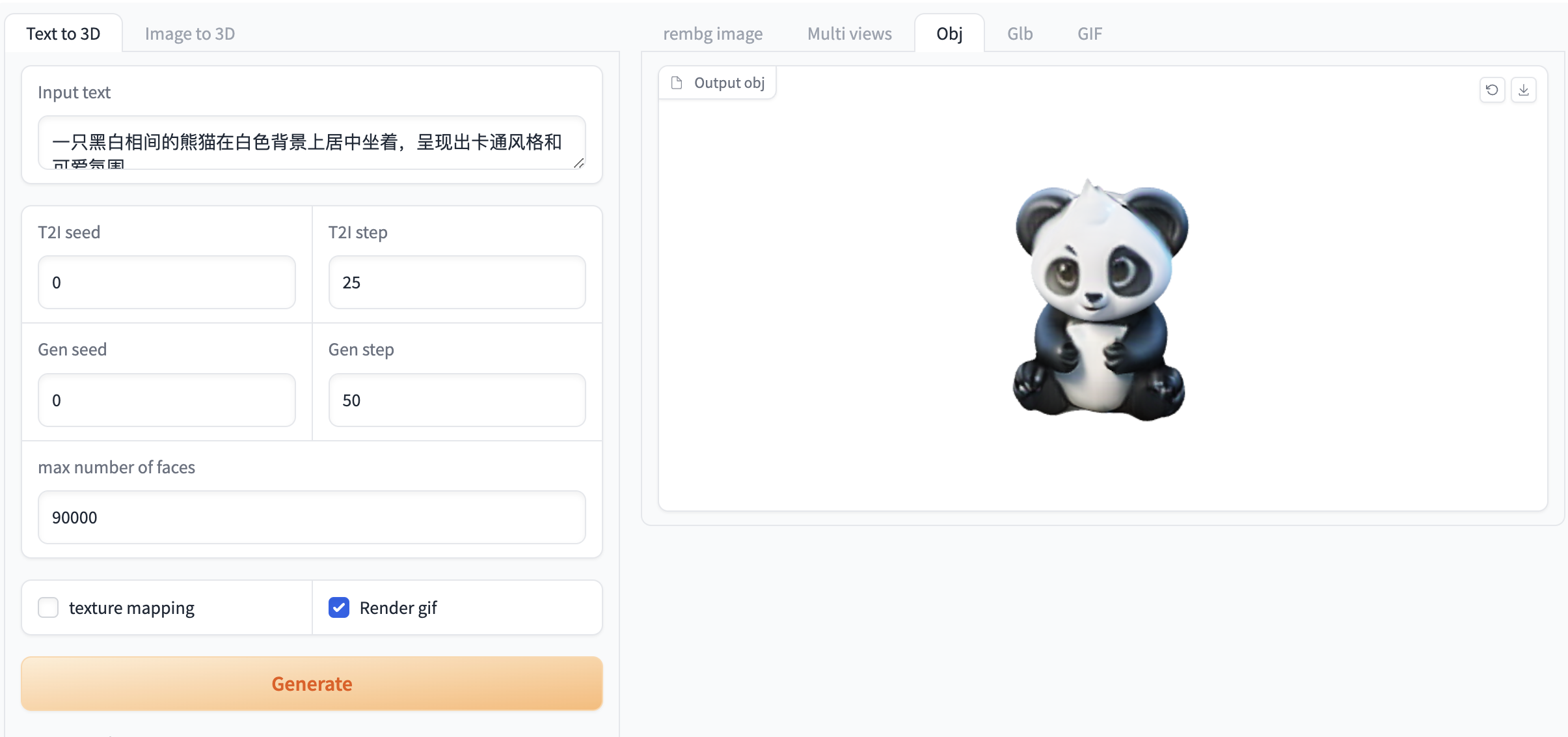
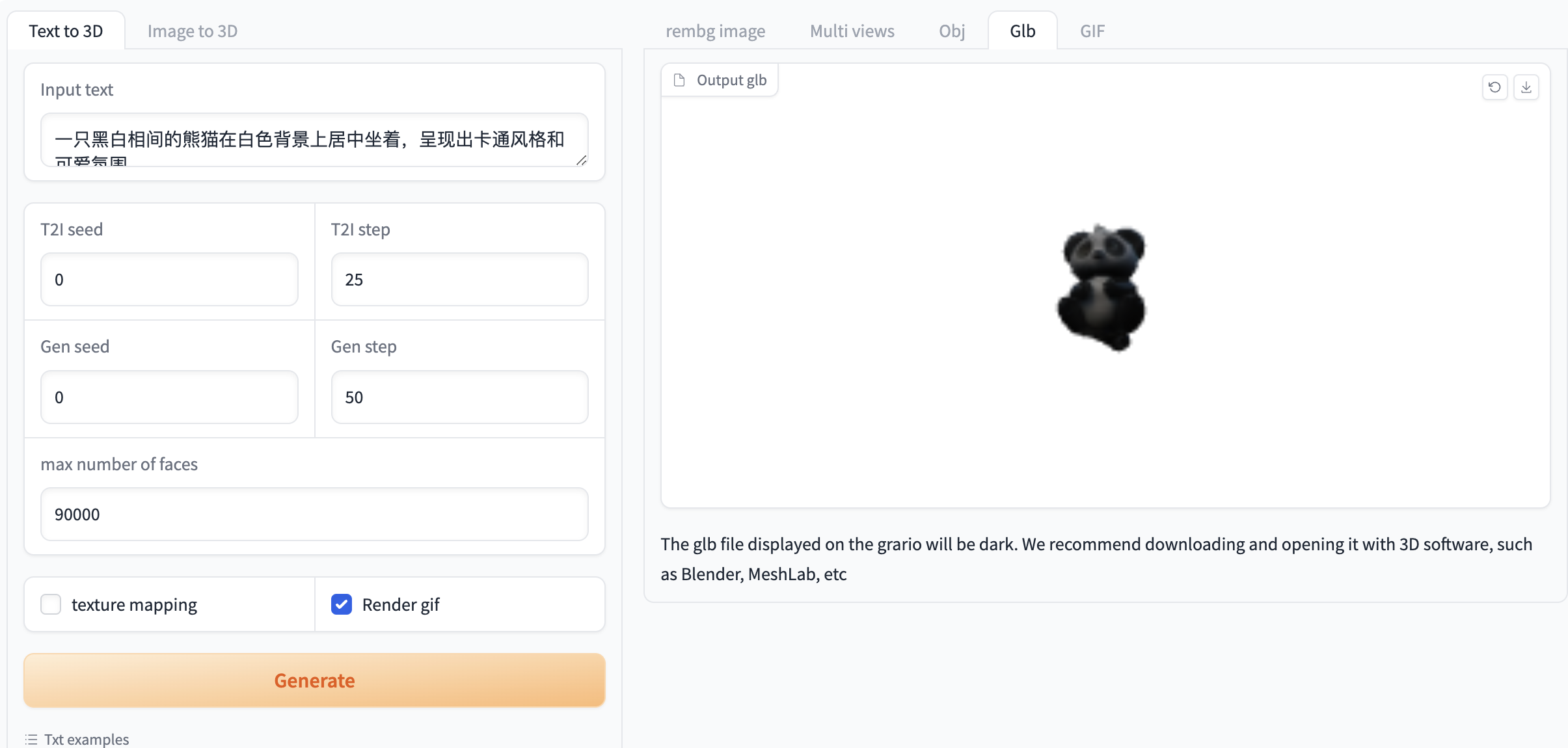
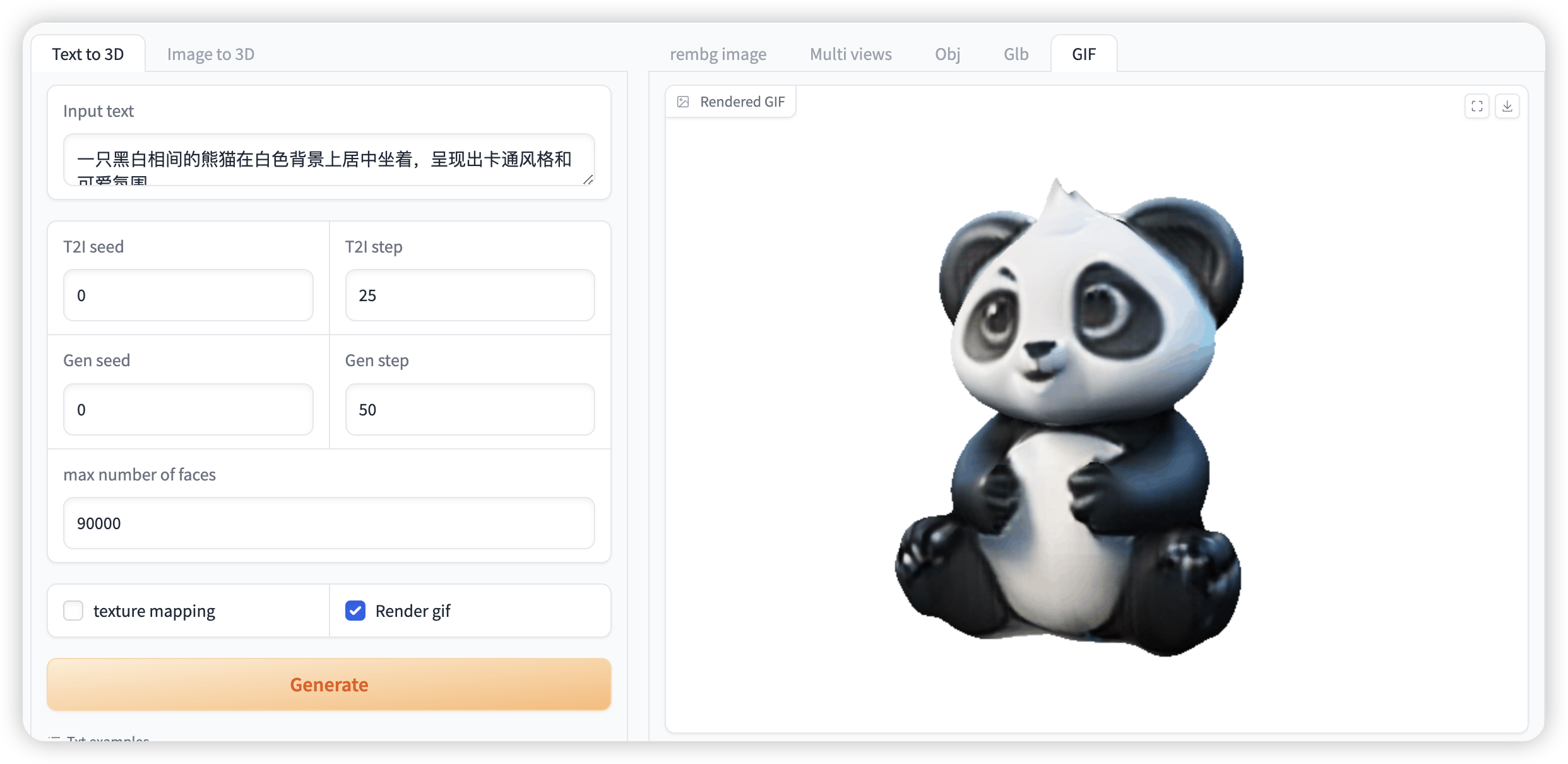
图 1 图像生成视频演示
2. 文本转 3D(image_to_video)
选择「Image to 3D」功能,按如下要求输入提示词和相关设置。
注意:自行上传图像时,请务必保证图片为 n*n 的正方形,否则会出现报错的情况
如果需要生成 gif 必须选中「Render gif」,否则不会生成效果。其他功能无需选中
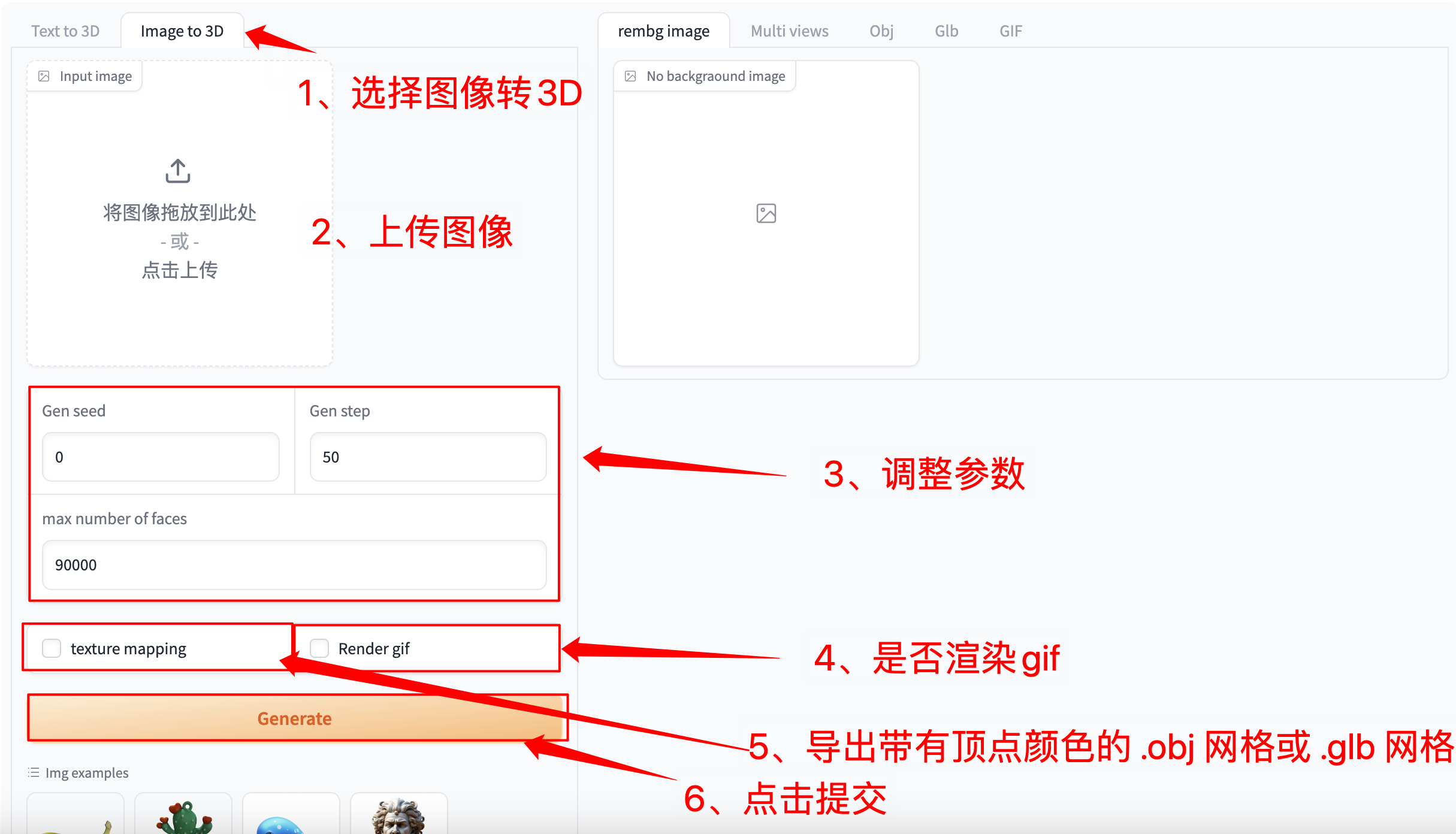
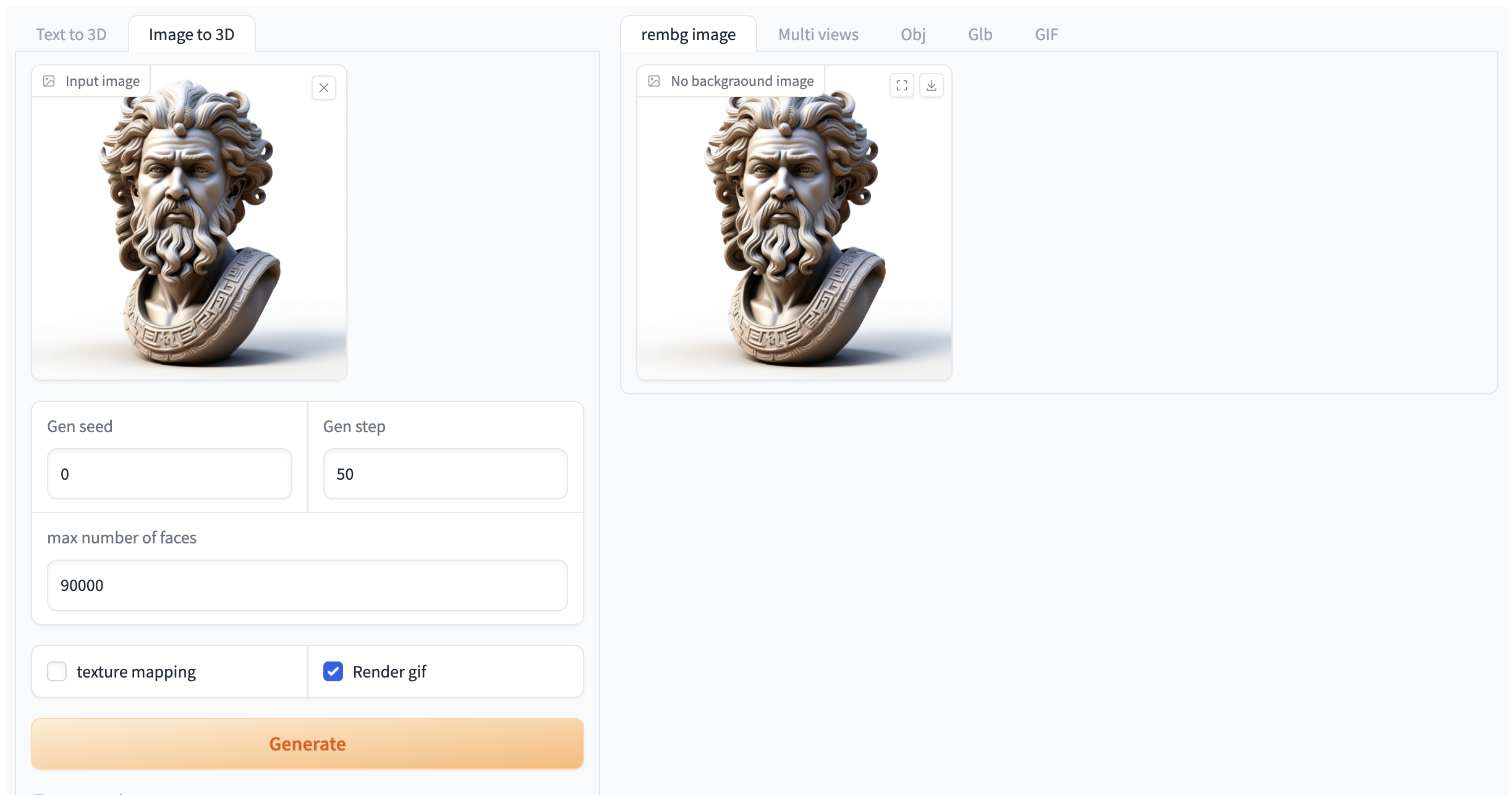
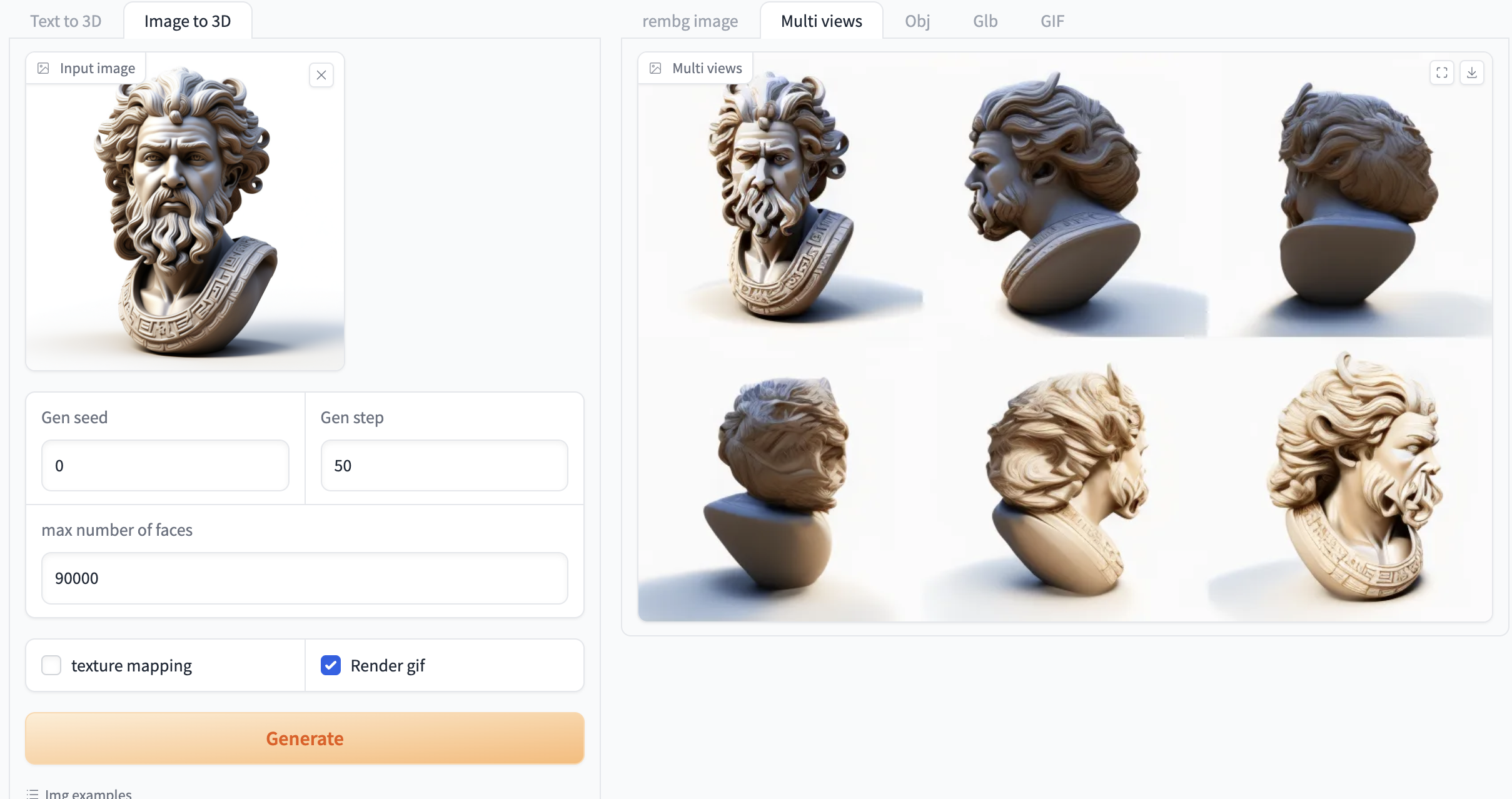
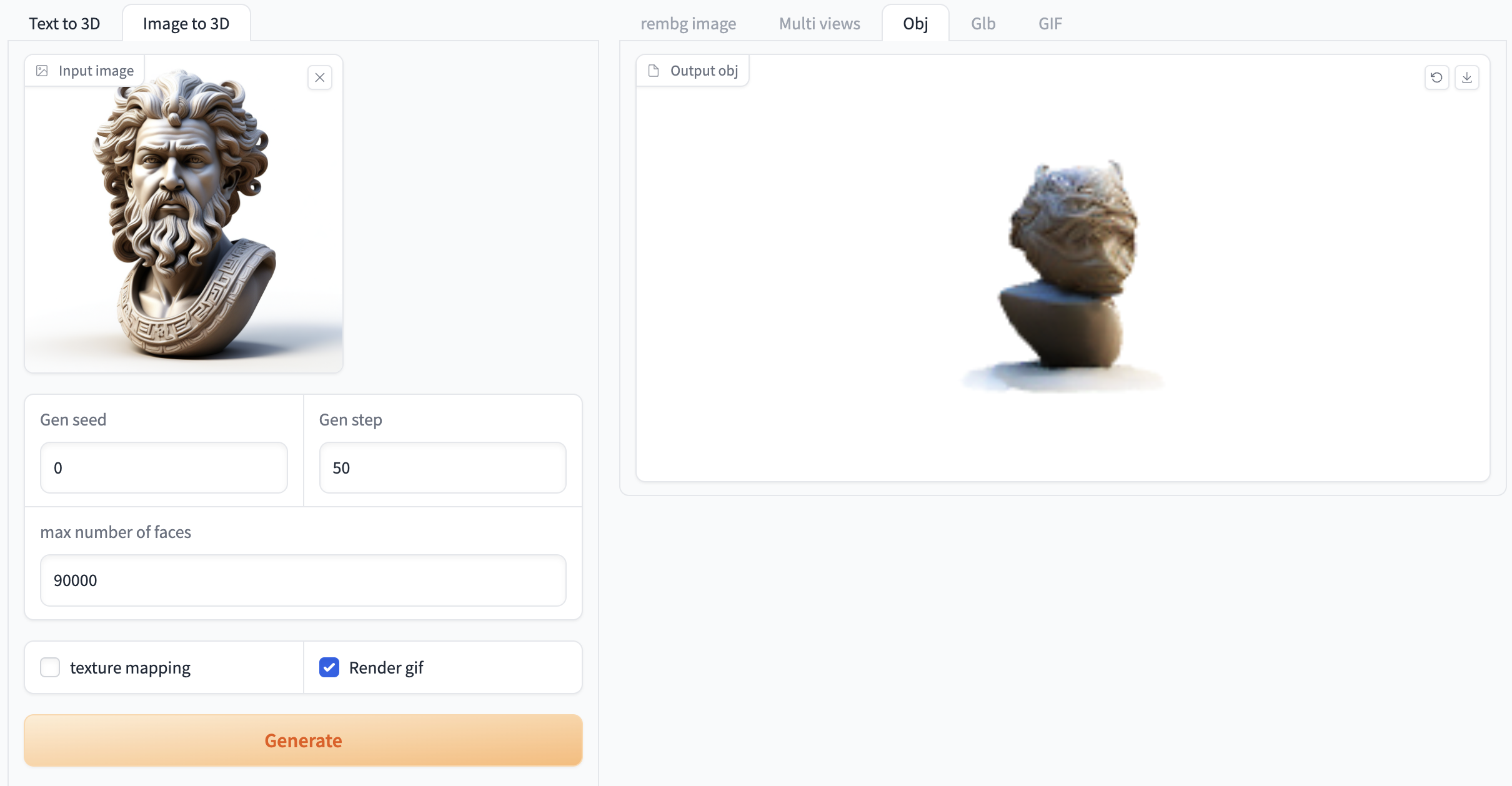
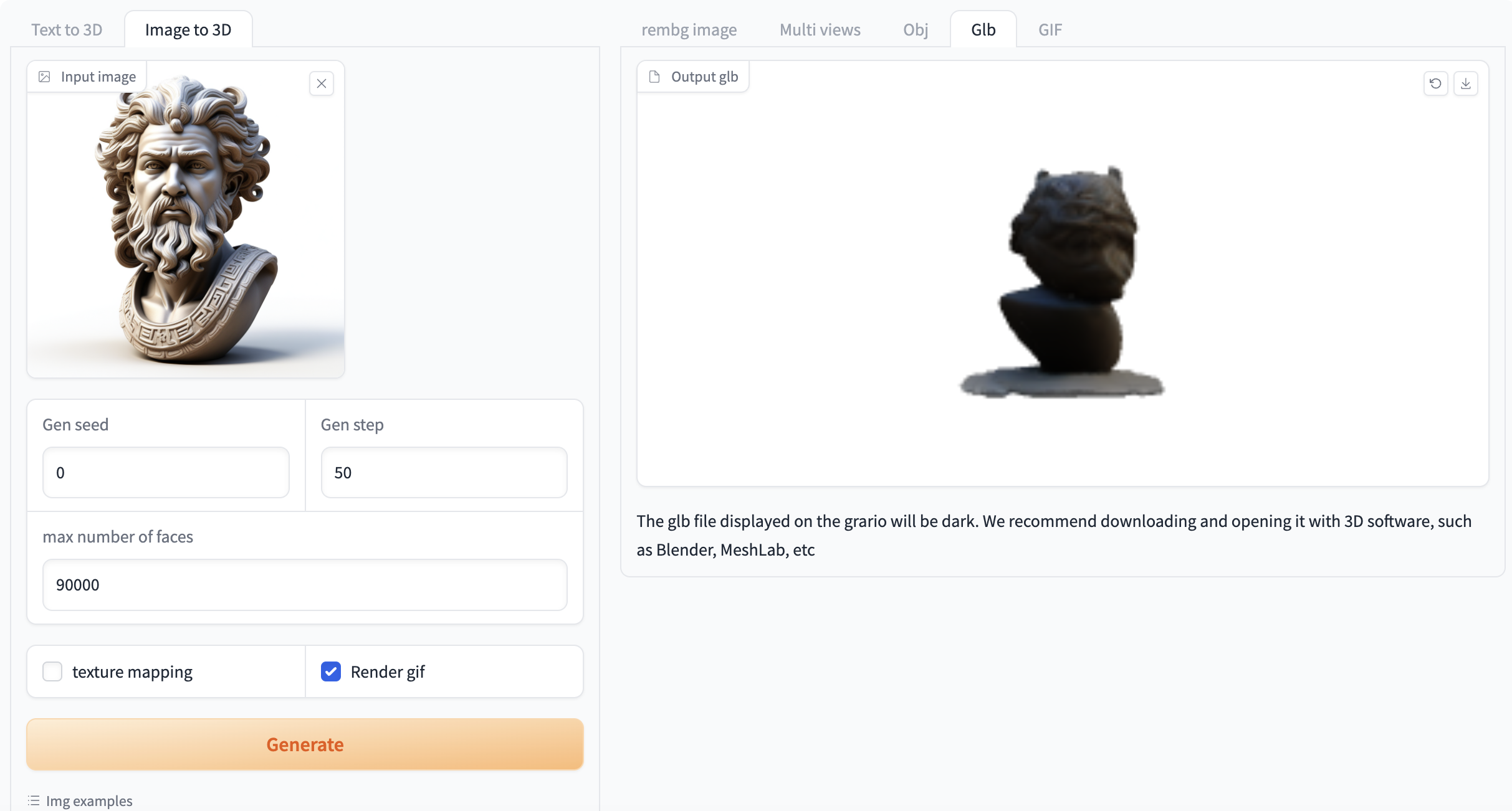
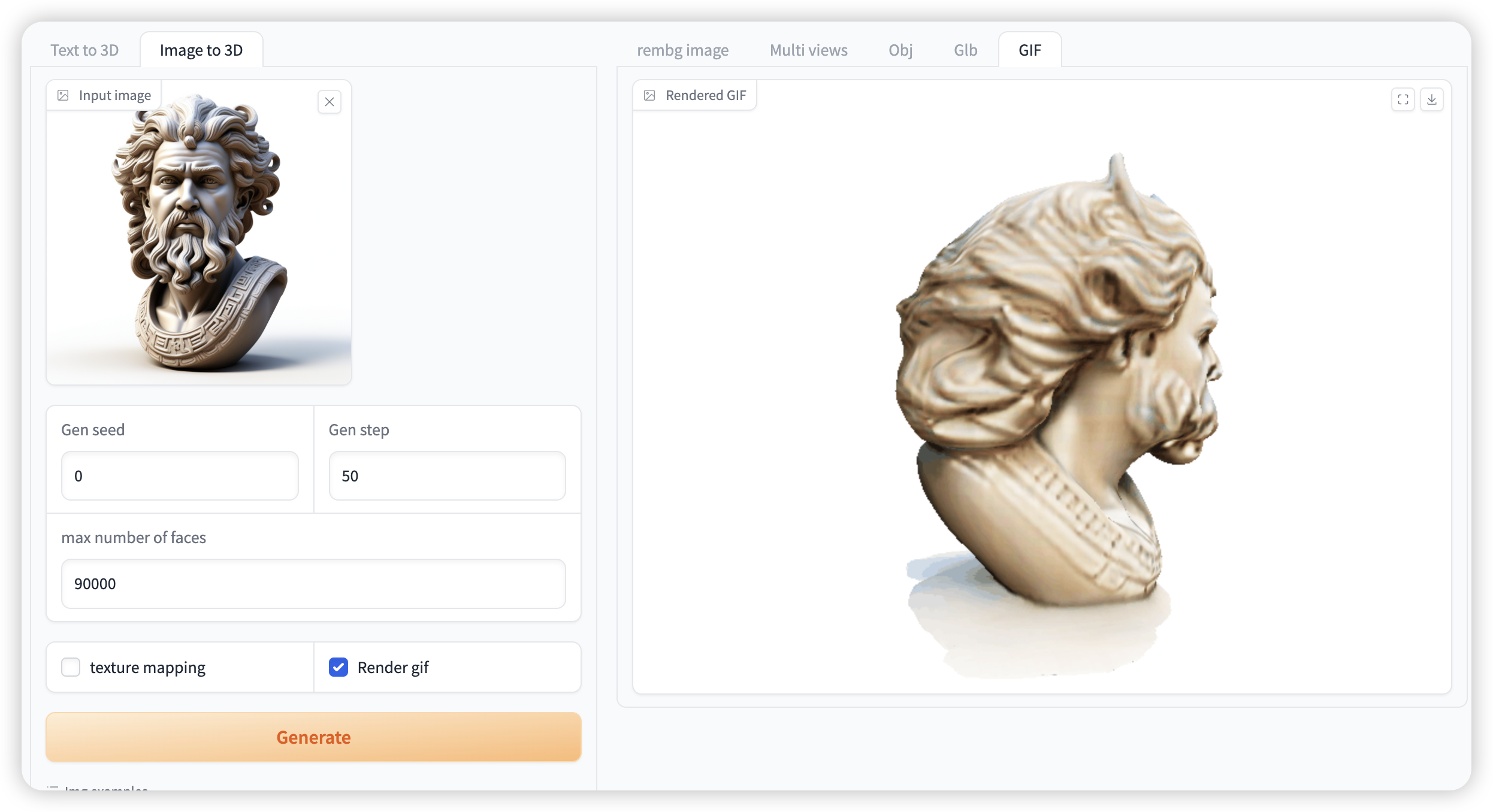

图 2 图像生成视频演示
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓
