HyperAI
Command Palette
Search for a command to run...
GOT-OCR-2.0 全球首款通用端到端 OCR 模型

项目介绍
GOT-OCR-2.0 是一个基于通用 OCR 理论(General OCR Theory)的统一端到端模型,专注于提升光学字符识别(OCR)的准确性与效率。该项目由 StepFun 、旷视科技、中国科学院大学和清华大学的研究团队共同发布,相关论文成果为 General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model,适用于场景文本、文档识别等多种应用场景。它采用了一体化的架构,能够高效处理文本的多样性和复杂性。 GOT-OCR 2.0 不仅支持场景文本识别,还能处理多页文档,为 OCR 领域带来更多灵活性。
GOT-OCR-2.0 的特点包括:
- 通用性强:基于通用 OCR 理论,能够处理场景文本和复杂文档结构,如表格、公式等。
- 端到端模型:统一的端到端架构简化了整个 OCR 流程,从图像输入到文本输出一体化。
- 高效性能:集成了 Flash-Attention 技术,提升了识别速度和性能。
- 多平台支持:支持 CUDA 加速,并与 GOT-OCR2.0 平台集成,可加载预训练模型。
- 应用广泛:适用于多页文档、场景文本等广泛的应用场景。
效果示例
 |
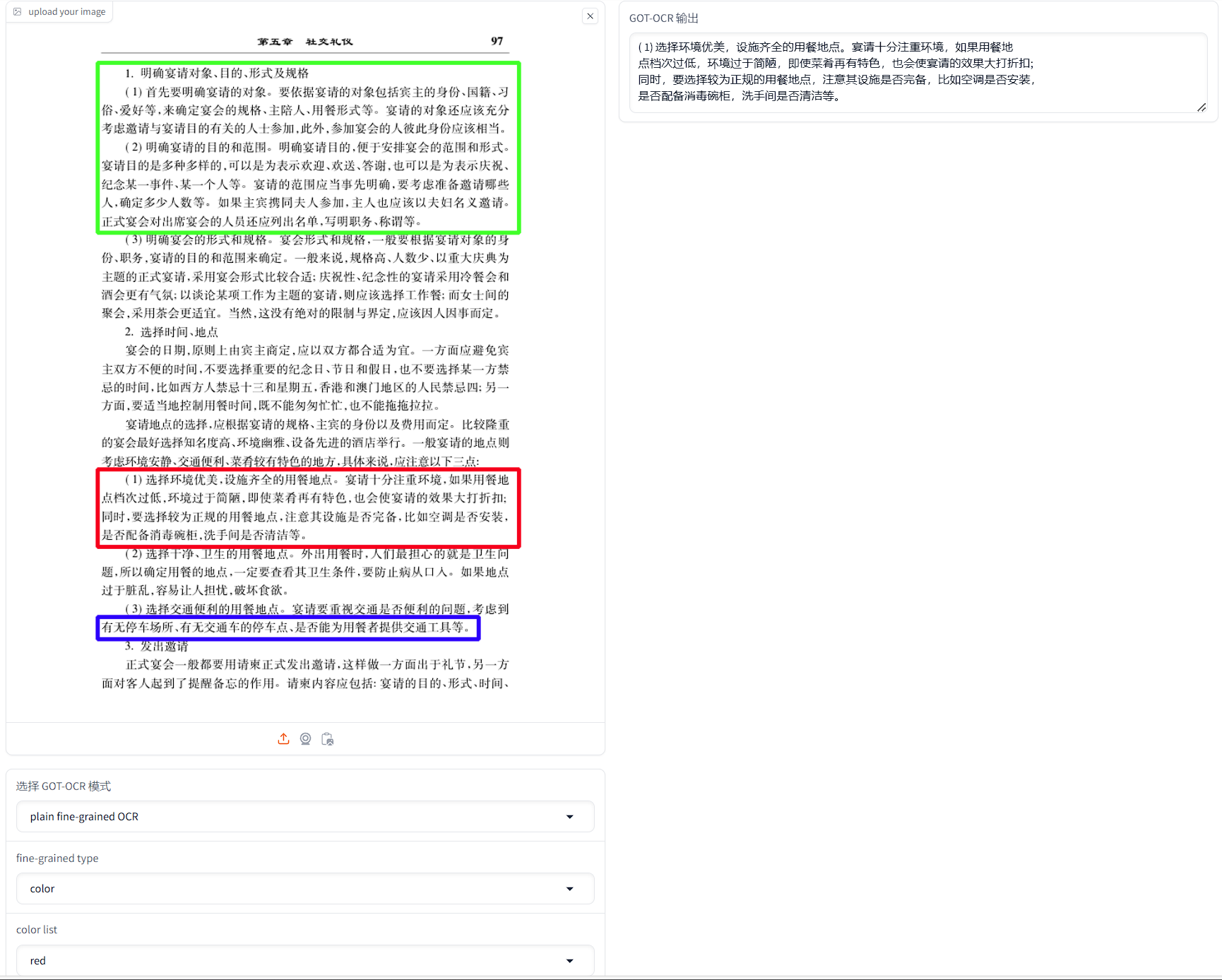 |
运行步骤
1. 在该项目右上角点击「克隆」,随后依次点击「下一步」即可完成:基本信息> 选择算力> 审核。最后点击「继续执行」即可在个人容器内开启本项目。
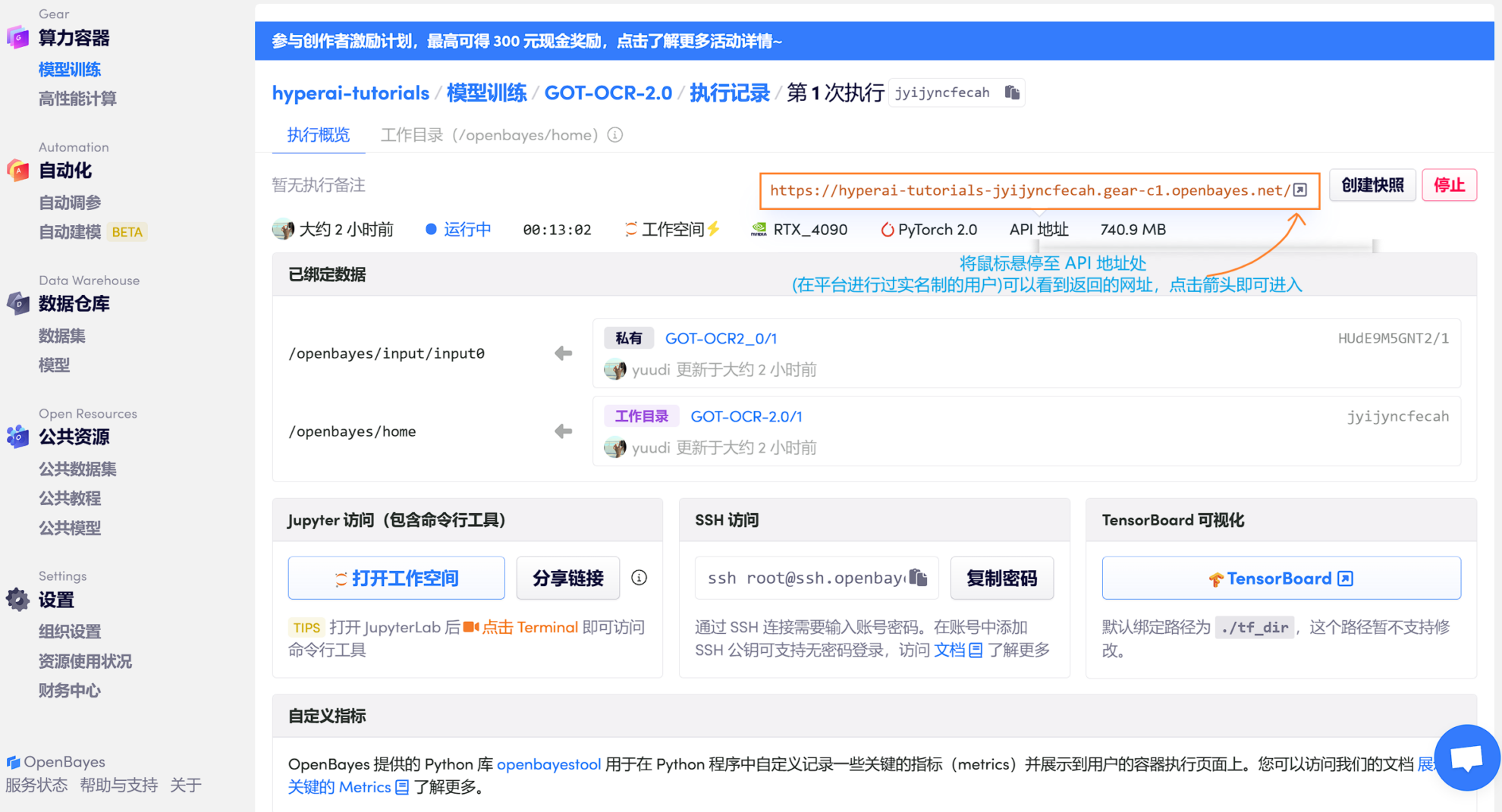
2. 资源分配完成后,后台会自动初始化模型(),随后可直接使用平台提供的 API 地址进行操作页面的访问(需要已完成实名认证,此步无需打开工作空间)
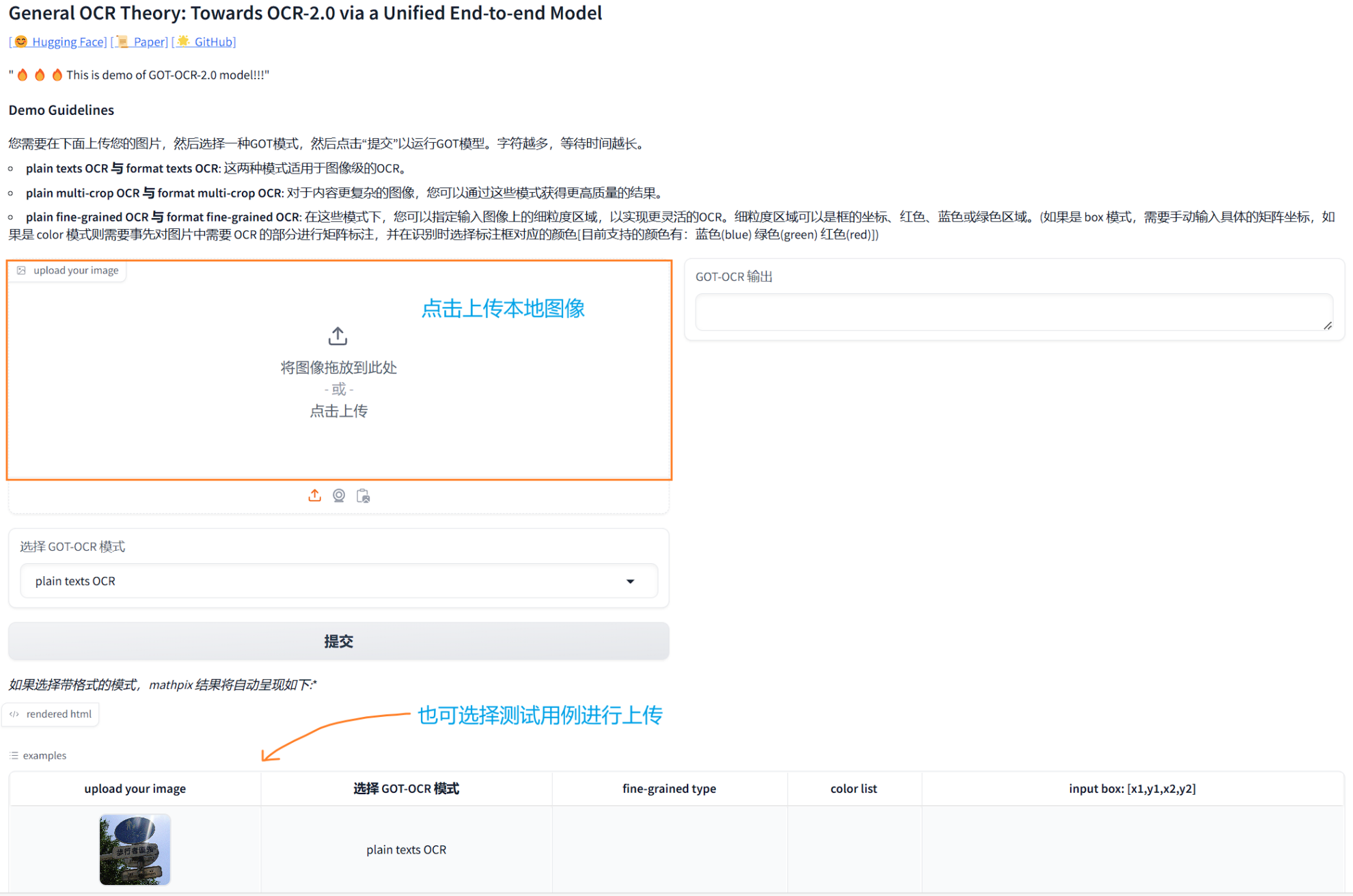
3. 上传目标图片
该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。