HyperAI
Command Palette
Search for a command to run...
MuseTalk 高质量口型同步模型 Demo
日期
1 年前
大小
2.41 GB
MuseTalk 的特点包括:
- 实时性:能够在实时环境中运行,达到每秒 30 帧以上的处理速度,确保唇语同步的流畅性。
- 高质量同步:采用潜在空间修复方法,在保持面部特征的同时,根据输入音频调整口型,实现高质量的唇语同步。
- 与 MuseV 配合:MuseTalk 可以与 MuseV 模型一起使用,MuseV 是一个视频生成框架,能够生成虚拟人视频。
- 开源:MuseTalk 的代码已经开源,便于社区贡献和进一步的开发。
MuseTalk 在口型生成方面表现出色,能够生成准确且画面一致性良好的口型,尤其擅长真人视频生成。它在与其他产品如 EMO 、 AniPortrait 、 Vlogger 以及微软的 VASA-1 等进行比较时,也具有优势。
效果示例
模型框架
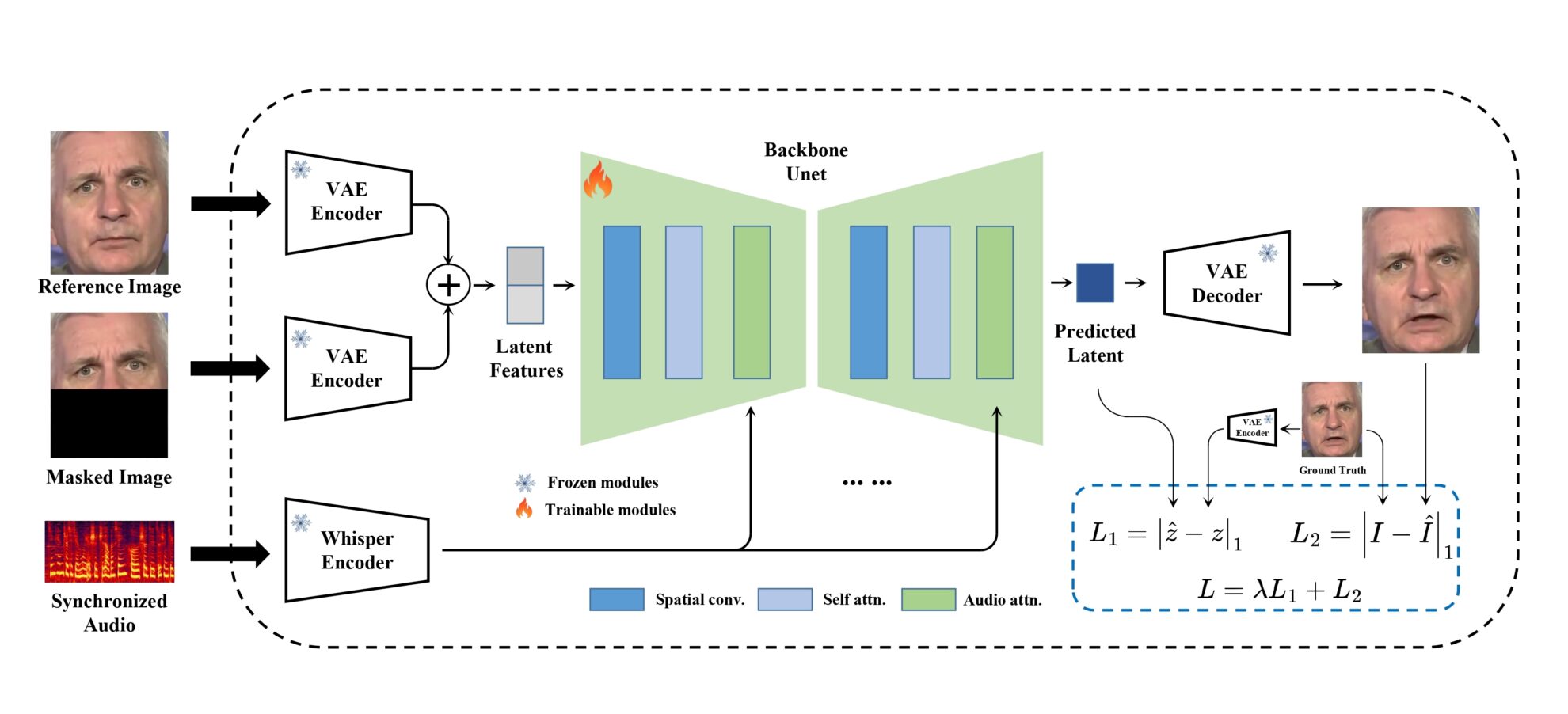
MuseTalk 在潜在空间中进行训练,其中图像由 freezed VAE 编码。音频由 freezed whisper-tiny 模型编码。生成网络的架构借鉴了 stable-diffusion-v1-4 的 UNet,其中音频嵌入通过交叉注意与图像嵌入融合。
运行步骤
1. 在该项目右上角点击「克隆」,随后依次点击 “下一步” 即可完成:基本信息> 选择算力> 审核等步骤。最后点击「继续执行」即可在个人容器内开启本项目。
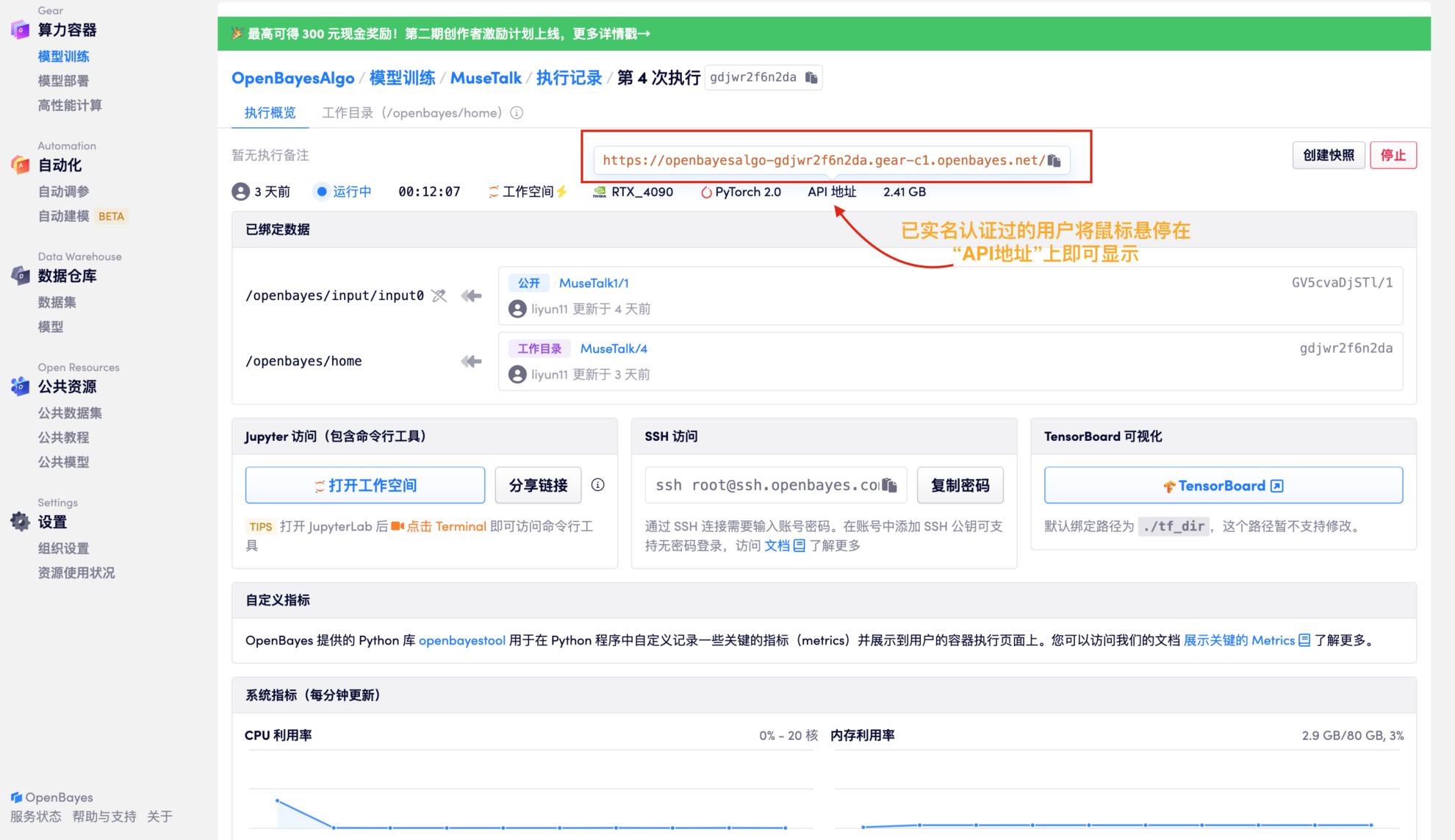
2. 待资源分配完成后,直接复制 API 地址在任意网址粘贴进入(需要已完成实名认证,此步无需打开工作空间)
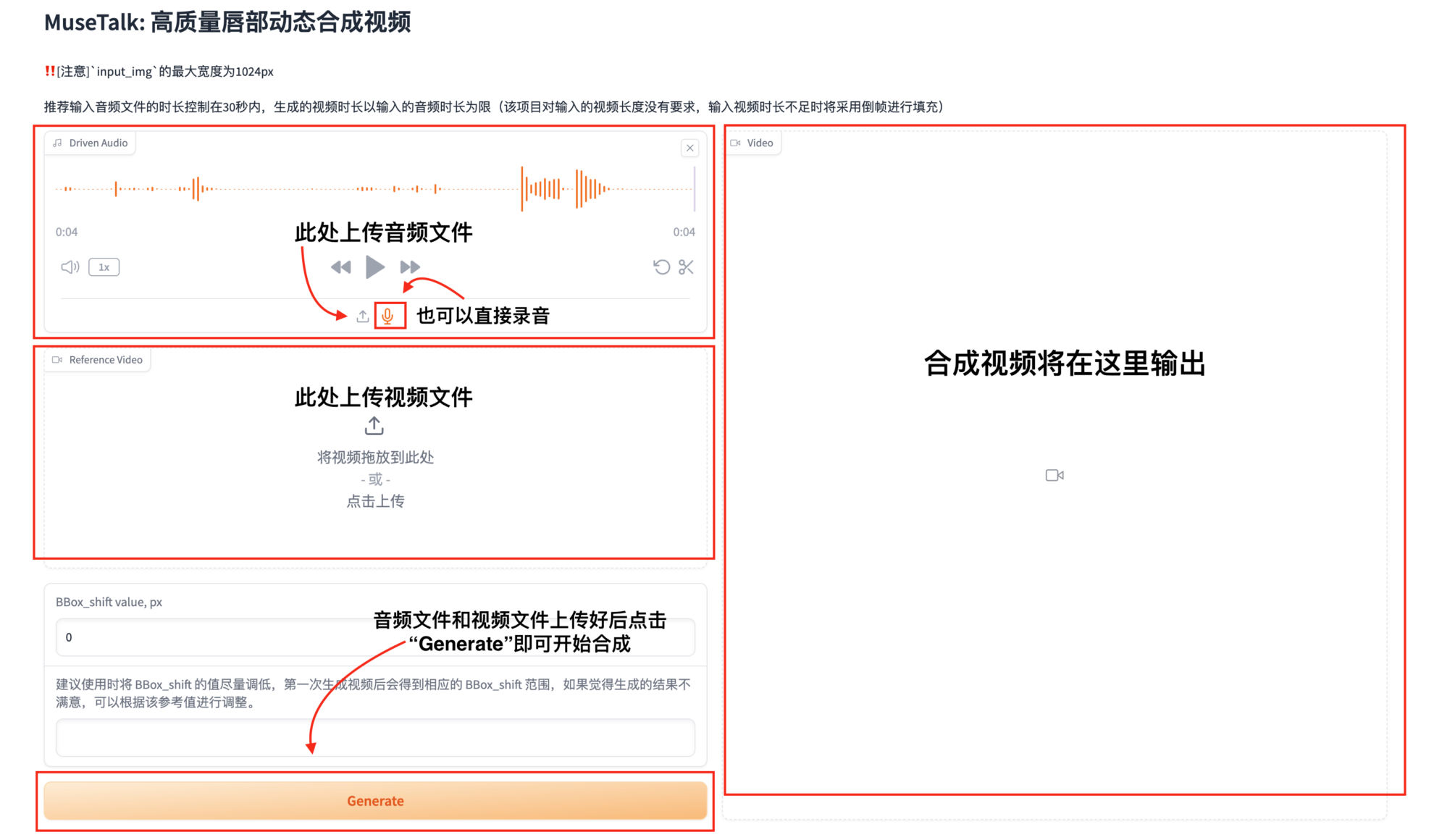
3. 上传音频文件和视频文件进行合成
经测试:生成一段时长为 17 秒的音频文件大概需要 3 分钟;时长为一分钟左右的音频文件生成时间大概需要 6 分钟。
-|MuseTalk 可以根据输入的音频修改脸部和口型,脸部区域的大小最好为 256 x 256 。同时 MuseTalk 还支持修改面部区域中心点建议,这将显着影响生成结果。
-|目前 MuseTalk 支持中文、英文、日文等多种语言的音频输入。
-|最终生成视频时长以音频时长为准。
该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。