HyperAI
Command Palette
Search for a command to run...
MuseV 不限时长的虚拟人视频生成 Demo

项目简介
MuseV 是在 2024 年 3 月由腾讯音乐娱乐的天琴实验室开源的虚拟人视频生成框架,专注于生成高质量的虚拟人视频和口型同步。它利用先进的算法,能够制作出具有高度一致性和自然表情的长视频内容。其可与已经发布的 MuseTalk 结合使用可以构建完整的「虚拟人方案」。
该模型具有以下特点:
- 支持使用新颖的视觉条件并行去噪方案进行无限长度生成,不会再有误差累计的问题,尤其适用于固定相机位的场景。
- 提供了基于人物类型数据集训练的虚拟人视频生成预训练模型。
- 支持图像到视频、文本到图像到视频、视频到视频的生成。
- 兼容
Stable Diffusion文图生成生态系统,包括base_model、lora、controlnet等。 - 支持多参考图像技术,包括
IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID。
效果展示
生成结果的所有帧直接由 MuseV 生成,没有时序超分辨、空间超分辨等任何后处理。
以下所有测试用例都可在本教程中实现,经测试生成一段 7 秒钟的视频大概需要 2 分半左右的时间,测试的最长视频时长为 20 秒,用时 8 分钟。
人物效果展示
| image | video | prompt |
 | (masterpiece, best quality, highres:1), peaceful beautiful sea scene | |
 | (masterpiece, best quality, highres:1), playing guitar | |
 | (masterpiece, best quality, highres:1), playing guitar |
场景效果展示
| image | video | prompt |
 | (masterpiece, best quality, highres:1), peaceful beautiful waterfall, an endless waterfall | |
 | (masterpiece, best quality, highres:1), peaceful beautiful sea scene |
根据已有视频生成视频
| image | video | prompt |
 | (masterpiece, best quality, highres:1), is dancing, animation |
运行步骤
1. 在本教程右上角找到「克隆」按钮,点击「克隆」后,直接使用平台默认的配置进行容器创建,等待容器成功执行并启动后看到下图所展示的页面,按照图中提示进入项目的操作界面。
❗注意❗ 由于模型较大,容器启动成功后可能需要 1 分钟左右的时间等待模型加载完毕方可打开 API 地址。
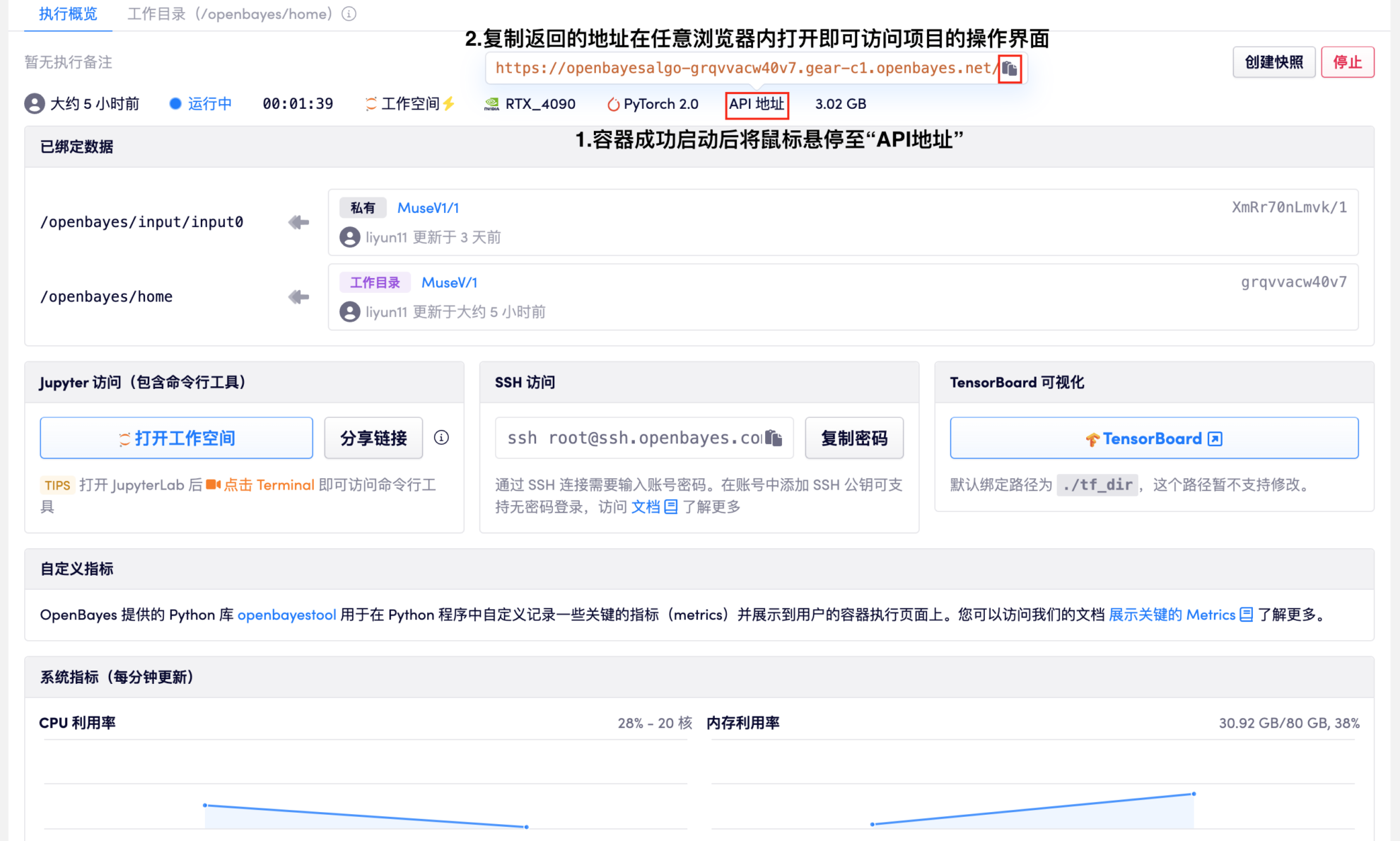
2. 页面的使用讲解如下:

交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。