Command Palette
Search for a command to run...
本教程推荐使用 pytorch 版本为 2.0,单卡 4090,为了方便使用,已将使用的模型下载至教程内,请读者依次运行即可。
1. 介绍
随着各行业对先进计算机视觉系统的需求持续激增,视觉变压器的部署已成为研究人员和从业者的焦点。然而,要充分发挥这些模型的潜力,需要对其架构有深入的了解。此外,制定有效部署这些模型的优化策略也同样重要。
本文旨在概述 Vision Transformer,全面探讨其架构、关键组件以及使它们与众不同的基本原理。在文章的最后,我们将通过代码演示讨论一些优化策略,使模型更加紧凑,以便于部署。
2. Vit 概述
ViT 是一种特殊类型的神经网络,主要应用于图像分类和目标检测。 ViT 的准确性已经超越了传统的 CNN,而促成这一点的关键因素是它们基于 Transformer 架构。现在这个架构是什么?
2017 年, Vaswani 等人在论文 《Attention is all you need》中介绍了 Transformer 神经网络架构。该网络使用与循环神经网络(RNN)非常相似的编码器和解码器结构。在这个模型中,输入没有时间戳的概念;所有单词同时传递,并且它们的单词嵌入同时确定。
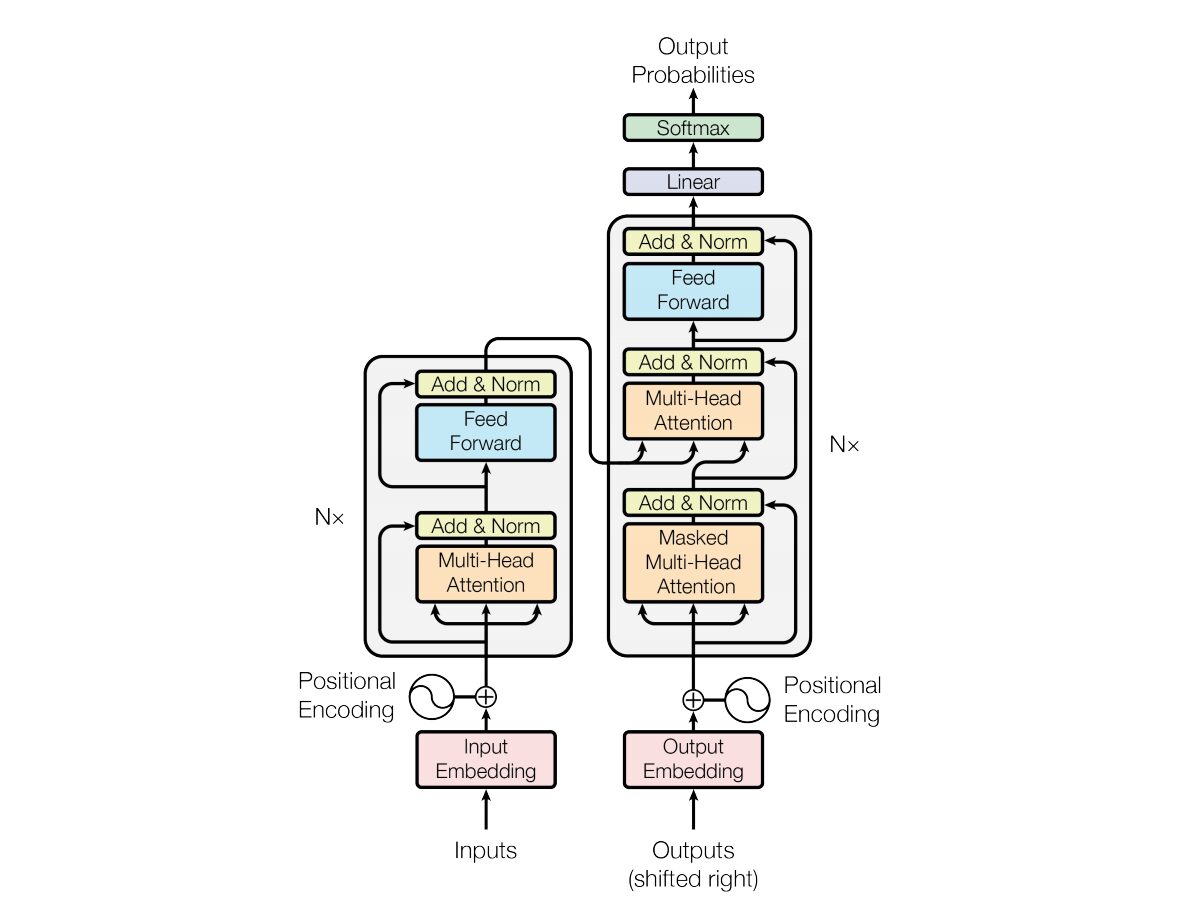
这种类型的神经网络架构依赖于一种称为自注意力的机制。
以下是 Transformer 架构关键组件的高级解释:
- 输入嵌入:输入嵌入是将输入传递给变压器的第一步。输入嵌入是指将输入标记或单词转换为可以输入模型的固定大小向量的过程。这个嵌入步骤至关重要,因为它以捕获单词之间语义关系的方式将离散标记表示转换为连续向量表示。这个嵌入步骤将一个单词映射到一个向量,但是同一个单词在不同的句子中可能有不同的含义。这就是位置编码器的用武之地。
- 位置编码:由于 Transformer 本身并不理解序列中元素的顺序,因此将位置编码添加到输入嵌入中,以向模型提供有关序列中元素位置的信息。简而言之,位置嵌入给出了一个向量,该向量是基于句子中单词位置的上下文。原始论文使用正弦和余弦函数来生成该向量。该信息被传递到编码器块。
- 编码器-解码器结构: Transformer 主要用于序列到序列的任务,例如机器翻译。它由编码器和解码器组成。编码器处理输入序列,解码器生成输出序列。
- 多头自注意力:自注意力允许模型在进行预测时对输入序列的不同部分进行不同的权重。 Transformer 的关键创新是使用多个注意力头,使模型能够同时关注输入的不同方面。每个注意力头都经过训练以关注不同的模式。
- 缩放点积注意力:注意力机制通过输入序列与可学习权重向量的点积来计算一组注意力分数。这些分数经过缩放并通过 softmax 函数以获得注意力权重。使用这些注意力权重的输入序列的加权和就是注意力机制的输出。
- 前馈神经网络:在注意力层之后,每个编码器和解码器块通常包括一个具有激活函数(例如 ReLu)的前馈神经网络。该网络独立地应用于序列中的每个位置。
- 层归一化和残差连接:层归一化和残差连接用于稳定训练。编码器和解码器中的每个子层(注意力或前馈)都有层归一化,每个子层的输出都通过残差连接传递。
- 编码器和解码器堆栈:编码器和解码器由多个彼此堆叠的相同层组成。层数是一个超参数。
- 解码器中的屏蔽自注意力:在训练期间,在解码器中,自注意力机制被修改以防止关注未来的令牌。这是使用掩蔽技术来完成的,以确保每个位置只能处理它之前的位置。
- 最终线性和 Softmax 层:解码器堆栈的输出被转换为最终预测概率(例如,使用线性层,然后是 softmax 激活)以生成输出序列。
3. 了解 Vision Transformer 架构
CNN 被认为是图像分类任务的最佳解决方案。如果预训练的数据集足够大,ViT 在此类任务上始终击败 CNN 。 ViT 取得了重大成就,成功地在 ImageNet 上训练了 Transformer 编码器,与众所周知的卷积架构相比,展示了令人印象深刻的结果。
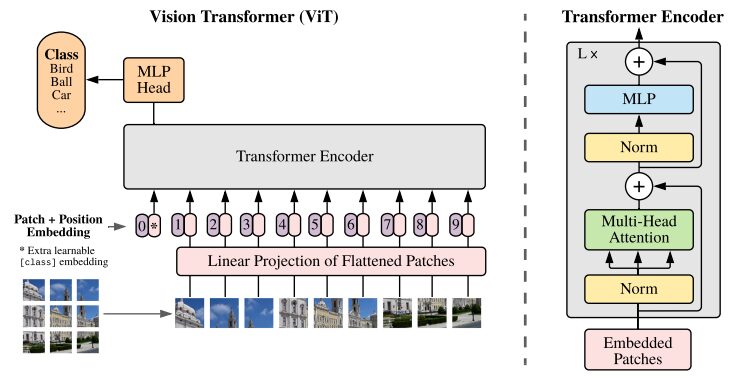
原始研究论文中 ViT 架构的图示
Transformers 模型通常处理按顺序传递到编码器-解码器的图像和单词。以下是 ViT 的简化概述:
- 补丁提取:图像作为补丁序列被馈送到 Transformer 编码器。补丁是指图像中的一个小矩形部分,通常大小为 16×16 像素。

- 将图像划分为不重叠的块(通常为 16×16 网格)后,每个块都会转换为表示其特征的向量。这些特征通常是通过利用卷积神经网络(CNN)来提取的,该网络经过训练可以识别图像分类所必需的重要特征。
- 线性嵌入:这些提取的补丁被线性嵌入到平面向量中。然后,这些向量被视为 Transformer 的输入序列,也称为扁平补丁的线性投影。
- Transformer 编码器:嵌入的补丁向量通过 Transformer 编码器层堆栈传递。每个编码器层由自注意力机制和前馈神经网络组成。
- 自注意力机制:自注意力机制允许模型捕获图像中不同补丁之间的关系,使其能够学习远程依赖性和关系。 Transformer 中的注意力机制使模型能够捕获局部和全局上下文信息,使其能够有效地执行各种视觉任务。
- 位置编码:由于 Transformer 本身并不理解补丁之间的空间关系,因此将位置编码添加到输入嵌入中以提供有关原始图像中补丁位置的信息。
- 多个编码器层: ViT 通常使用多个 Transformer 编码器层从输入图像中捕获分层和抽象特征。
- 全局平均池化: Transformer 编码器的输出通常受到全局平均池化,它将来自不同补丁的信息聚合成固定大小的表示。
- 分类头: 然后将合并的表示输入到分类头(通常由一个或多个完全连接的层组成)中,以生成特定计算机视觉任务(例如图像分类)的最终输出。
我们强烈建议您查看原始研究论文,以更深入地了解 ViT 架构。
4. 如何使用
以下代码均可在 pre_ViT.ipynb 中访问并执行!!!!
4.1 使用预训练 ViT 模型对图片进行分类
预训练 ViT 模型是使用著名的 ImageNet-21k(一个包含 1400 万张图像和 21k 个类别的数据集)进行预训练的 ,并在包含 100 万张图像和 1k 个类别的 ImageNet 数据集上进行了微调。
演示:
- 在平台上第一次启动会缺少下面两个库,使用 pip 安装 用 pip 安装依赖时添加额外的参数 –user 那么安装的依赖会保存在容器的工作空间,下次重启不回失效
!pip install --user -q transformers timm- 从 Transformer 库导入必要的类。 ViTFeatureExtractor 用于从图像中提取特征,ViTForImageClassification 是用于图像分类的预训练 ViT 模型。
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image as img
from IPython.display import Image, display
FILE_NAME = '/notebooks/football-1419954_640.jpg'
display(Image(FILE_NAME, width = 700, height = 400))
#预测图片的地址
image_path = "./pic/football.jpg"
image_array = img.open(image_path)
#Vit 模型地址
vision_encoder_decoder_model_name_or_path = "./my_model/"
#加载 ViT 特征转化 and 预训练模型
#feature_extractor = ViTFeatureExtractor.from_pretrained(vision_encoder_decoder_model_name_or_path)
#model = ViTForImageClassification.from_pretrained(vision_encoder_decoder_model_name_or_path)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
#使用 Vit 特征提取器处理输入图像,专为 ViT 模型的格式
inputs = feature_extractor(images = image_array,
return_tensors="pt")
#预训练模型处理输入并生成输出 logits,代表模型对不同类别的预测。
outputs = model(**inputs)
#创建一个变量来存储预测类的索引。
logits = outputs.logits
# 查找具有最高 Logit 分数的类的索引
predicted_class_idx = logits.argmax(-1).item()
print(predicted_class_idx)
#805
print("Predicted class:", model.config.id2label[predicted_class_idx])
#预测种类:足球代码分解:
- ViTFeatureExtractor.from_pretrained:负责将输入图像转换为适合 ViT 模型的格式。
- ViTForImageClassification.from_pretrained:加载预先训练的 ViT 模型以进行图像分类。
- feature_extractor:使用 ViT 特征提取器处理输入图像,将其转换为适合 ViT 模型的格式。
- model:预训练模型处理输入并生成输出 logits,代表模型对不同类别的预测。接下来的步骤是查找具有最高 Logit 分数的类的索引。创建一个变量来存储预测类的索引。
- model.config.id2label[predicted_class_idx]:将预测的类别索引映射到其相应的标签。
4.2 使用 DeiT 对图像进行分类
DeiT 展示了 Transformers 在计算机视觉任务中的成功应用,即使数据可用性和资源有限。
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
print(torch.__version__)
# should be 1.8.0
#从 DeiT 存储库加载名为 “deit_base_patch16_224” 的预训练 DeiT 模型。
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
#将模型设置为评估模式,这在使用预训练模型进行推理时非常重要。
model.eval()
#定义一系列应用于图像的变换。例如调整大小、中心裁剪、将图像转换为 PyTorch 张量、使用 ImageNet 数据常用的平均值和标准差值对图像进行归一化。
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
#从 URL 下载图像并对其进行转换。或者直接从本地上传
#Image.open(requests.get("https://images.rawpixel.com/image_png_800/czNmcy1wcml2YXRlL3Jhd3BpeGVsX2ltYWdlcy93ZWJzaXRlX2NvbnRlbnQvcHUyMzMxNjM2LWltYWdlLTAxLXJtNTAzXzMtbDBqOXFrNnEucG5n.png", stream=True).raw)
img = Image.open("./pic/football.jpg")
#None 模拟大小为 1 的批次
img = transform(img)[None,]
#模型的推理、预测
out = model(img)
clsidx = torch.argmax(out)
#打印预测类别的索引。
print(clsidx.item())代码分解:
- 安装库:第一个必要步骤是安装所需的库。我们强烈建议用户研究这些库以更好地理解。
- 加载预训练模型::model=torch.hub.load(‘facebookresearch/deit:main’, ‘deit_base_patch16_224’, pretrained=True) 从 DeiT 存储库加载名为 “deit_base_patch16_224” 的预训练 DeiT 模型。
- 将模型设置为评估模式:model.eval():将模型设置为评估模式,这在使用预训练模型进行推理时非常重要。
- 图像变换:定义一系列应用于图像的变换。例如调整大小、中心裁剪、将图像转换为 PyTorch 张量、使用 ImageNet 数据常用的平均值和标准差值对图像进行归一化。下载并转换图像:下一步涉及从 URL 下载图像并对其进行转换。添加参数 [None,] 会添加额外的维度来模拟大小为 1 的批次。
- 模型推理和预测:out = model(img) 将允许预处理后的图像通过 DeiT 模型进行推理。 clsidx = torch.argmax(out) 将找到概率最高的类的索引。接下来,打印预测类别的索引。
4.3 量化模型
为了减小模型大小,应用了量化。此过程在不影响模型精度的情况下减小了尺寸。
#将量化后端指定为 “qnnpack” 。 QNNPACK(Quantized Neural Network PACKage)是 Facebook 开发的低精度量化神经网络推理库
backend = "qnnpack"
model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
#推理过程中量化模型的权重,并 qconfig_spec 指定量化应仅应用于线性(全连接)层。使用的量化数据类型是 torch.qint8(8 位整数量化)
quantized_model = torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
scripted_quantized_model = torch.jit.script(quantized_model)
#模型保存到名为 “fbdeit_scripted_quantized.pt” 的文件
scripted_quantized_model.save("fbdeit_scripted_quantized.pt")代码分解:
- torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
- qconfig_spec 指定量化应仅应用于线性(全连接)层。使用的量化数据类型是 torch.qint8(8 位整数量化)。
4.4 优化模型
optimize_for_mobile 函数专门针对移动部署对其进行优化,并将生成的优化模型保存到文件中。
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model)
optimized_scripted_quantized_model.save("fbdeit_optimized_scripted_quantized.pt")
# 使用优化模型进行预测
out = optimized_scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.item())4.5 精简版
对于在支持 PyTorch Lite 的移动或边缘设备上部署模型非常重要,可确保此类设备运行时环境的兼容性和效率。
optimized_scripted_quantized_model._save_for_lite_interpreter("fbdeit_optimized_scripted_quantized_lite.ptl")
ptl = torch.jit.load("fbdeit_optimized_scripted_quantized_lite.ptl")4.6 比较推理速度
比较不同模型变体的推理速度,请执行提供的代码:
with torch.autograd.profiler.profile(use_cuda=False) as prof1:
out = model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof2:
out = scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof3:
out = optimized_scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof4:
out = ptl(img)
print("original model: {:.2f}ms".format(prof1.self_cpu_time_total/1000))
print("scripted & quantized model: {:.2f}ms".format(prof2.self_cpu_time_total/1000))
print("scripted & quantized & optimized model: {:.2f}ms".format(prof3.self_cpu_time_total/1000))
print("lite model: {:.2f}ms".format(prof4.self_cpu_time_total/1000))
以上代码均可在 pre_ViT.ipynb 中访问并执行!!!!
结论与思考
在本文中,我们包含了开始使用视觉转换器并使用 Paperspace 控制台探索该模型的所有内容。我们探索了该模型的重要应用之一:图像识别。为了比较和更容易地解释 ViT,我们还包含了 Transformer 架构。
Vision Transformer 论文介绍了一种有前途且简单的模型作为 CNN 的替代品。该模型在 ILSVRC 的 ImageNet 及其超集 ImageNet-21M 上进行预训练后,在流行的图像分类数据集(包括 Oxford-IIIT Pets 、 Oxford Flowers 和 Google Brain 的 JFT-300M)上达到了最先进的基准。
总之,Vision Transformers (ViTs) 和 DeiT 代表了计算机视觉领域的重大进步。 ViT 以其基于注意力的架构证明了 Transformer 模型在图像理解方面的有效性,挑战了传统的卷积方法。
尤其是 DeiT,通过引入知识蒸馏进一步解决了 ViT 面临的挑战。通过利用师生培训范例,DeiT 展示了通过显着减少标记数据实现竞争性能的潜力,使其成为大型数据集不易获得的场景中的有价值的解决方案。
随着该领域研究的不断发展,这些创新为更高效、更强大的模型铺平了道路,为计算机视觉应用的未来带来了令人兴奋的可能性。