LLM-SRBench:大型语言模型在科学方程发现方面的新基准
Parshin Shojaee, Ngoc-Hieu Nguyen, Kazem Meidani, Amir Barati Farimani, Khoa D Doan, Chandan K Reddy
发布日期: 4/16/2025
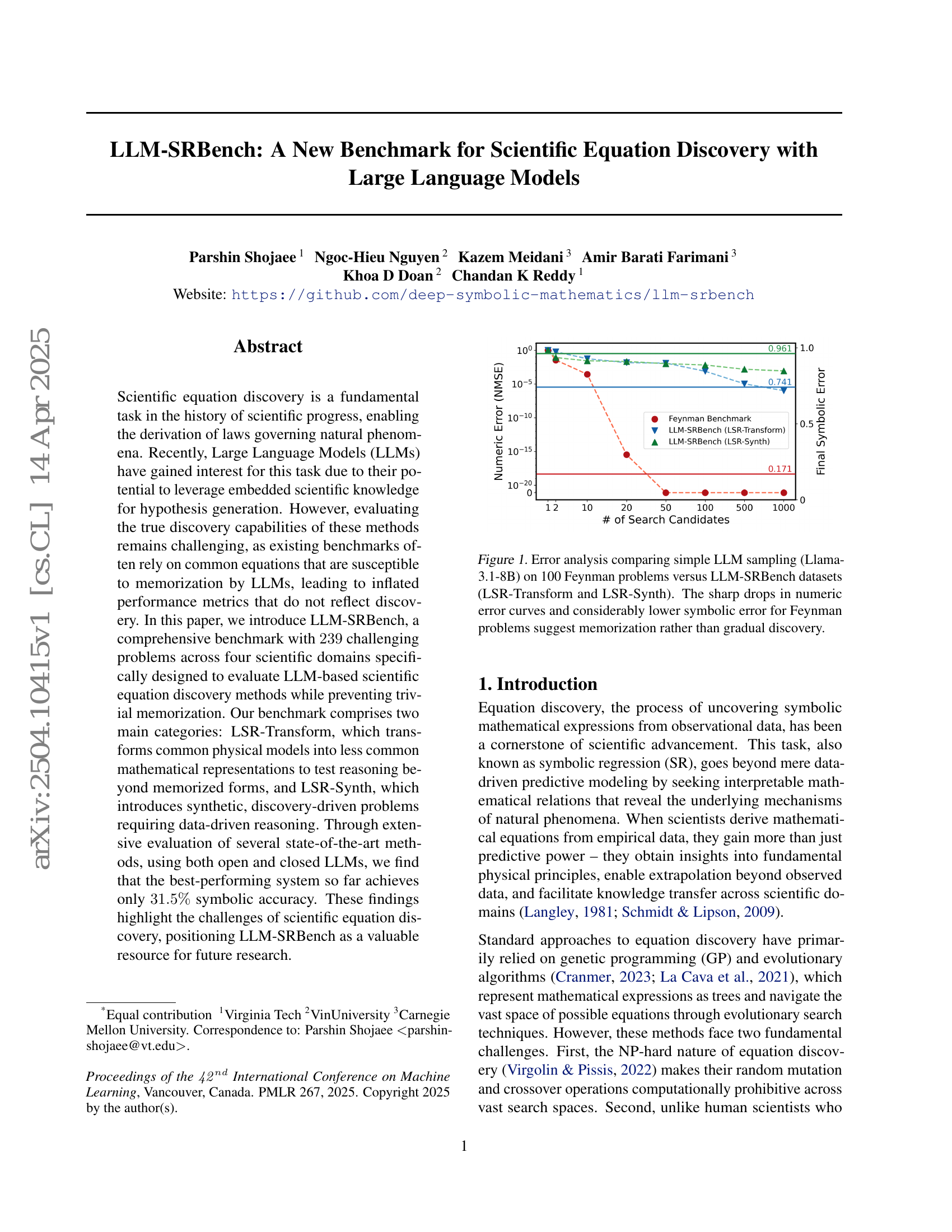
摘要
科学方程发现是科学进步历史中的基本任务,它使得人们能够推导出支配自然现象的规律。近年来,大型语言模型(LLMs)因其潜在的利用嵌入的科学知识进行假设生成的能力而引起了对这一任务的关注。然而,评估这些方法的真实发现能力仍然具有挑战性,因为现有的基准测试往往依赖于容易被大型语言模型记忆的常见方程,导致性能指标被高估,无法真实反映发现能力。在本文中,我们介绍了LLM-SRBench,这是一个包含四个科学领域239个具有挑战性问题的全面基准测试,专门设计用于评估基于大型语言模型的科学方程发现方法,同时防止简单的记忆化。我们的基准测试包括两个主要类别:LSR-Transform,将常见的物理模型转换为不常见的数学表示形式,以测试超出记忆化形式的推理能力;LSR-Synth,引入了合成的、以发现为导向的问题,需要基于数据的推理。通过对多种最先进的方法进行广泛评估,使用开放和封闭的大规模语言模型,我们发现目前表现最佳的系统仅达到31.5%的符号准确性。这些发现突显了科学方程发现所面临的挑战,并将LLM-SRBench定位为未来研究的重要资源。