Command Palette
Search for a command to run...
NVIDIA Nemotron Nano 2:一种精准高效的混合 Mamba-Transformer 推理模型
NVIDIA Nemotron Nano 2:一种精准高效的混合 Mamba-Transformer 推理模型
摘要
我们推出了Nemotron-Nano-9B-v2,这是一种混合Mamba-Transformer架构的语言模型,旨在提升推理类任务的吞吐量,同时在同类规模模型中实现顶尖的准确率。Nemotron-Nano-9B-v2基于Nemotron-H架构设计,该架构将传统Transformer模型中大部分自注意力(self-attention)层替换为Mamba-2层,从而在生成推理所需长思维链(long thinking traces)时显著提升推理速度。Nemotron-Nano-9B-v2的构建过程始于在20万亿个token上对一个120亿参数的基模型(Nemotron-Nano-12B-v2-Base)进行预训练,采用FP8训练方案。在完成对Nemotron-Nano-12B-v2-Base的对齐后,我们采用Minitron压缩与知识蒸馏策略,将模型压缩并优化,目标是在单张NVIDIA A10G GPU(配备22GiB显存,bfloat16精度)上实现高达128k token的推理能力。与现有同类规模模型(如Qwen3-8B)相比,Nemotron-Nano-9B-v2在推理基准测试中达到了相当或更优的准确率,同时在8k输入与16k输出等典型推理场景下,推理吞吐量最高提升了6倍。我们已将Nemotron-Nano-9B-v2、Nemotron-Nano-12B-v2-Base以及Nemotron-Nano-9B-v2-Base的模型检查点,连同大部分预训练与后训练数据集,公开发布于Hugging Face平台。
一句话总结
NVIDIA 推出 Nemotron-Nano-9B-v2,这是一种混合 Mamba-Transformer 推理模型,在推理基准测试中达到最先进准确率,同时在单个 A10G GPU 上实现高达 128k 上下文长度的推理,且推理吞吐量相比 Qwen3-8B 等同规模模型最高提升 6 倍,这得益于基于 12B 基础模型通过 Minitron 剪枝与蒸馏技术构建的压缩架构;该模型在生成过程中支持对思考预算的细粒度控制。
主要贡献
- Nemotron Nano 2 引入了一种混合 Mamba-Transformer 架构,将大部分自注意力层替换为 Mamba-2 模块,显著加快长推理轨迹的推理速度,同时在长达 128k token 的长上下文生成任务中保持高准确率。
- 该模型基于一个 120 亿参数的基础模型(Nemotron-Nano-12B-v2-Base),在 20 万亿 token 数据上使用 FP8 精度和 Warmup-Stable-Decay 学习率调度进行预训练,并通过持续预训练进一步扩展其长上下文能力,而不会牺牲标准基准测试上的性能。
- 通过包含 SFT、GRPO、DPO 和 RLHF 的多阶段后训练流程,该模型在推理任务上的准确率与 Qwen3-8B 等同规模模型持平或更优,同时在高生成场景(如 8k 输入 + 16k 输出 token)中实现最高达 6 倍的吞吐量提升。
引言
作者利用 NVIDIA 的 Nemotron Nano 2——一种专为资源受限环境高效部署而设计的轻量级语言模型,以应对边缘和实时应用中对轻量、高性能 AI 模型日益增长的需求。以往小型语言模型的研究常面临模型大小、推理速度与任务准确率之间的权衡,尤其在长上下文和安全关键场景中更为明显。其核心贡献在于在数据筛选、FP8 精度训练、模型架构、长上下文处理、对齐、压缩与评估等系统级层面实现全面优化,从而构建出一个高效、安全且可部署的模型,尽管体积小巧,仍能保持强劲性能。
数据集
- Nemotron-Nano-12B-v2-Base 的数据集由精心筛选与合成生成的数据组成,来源包括 Common Crawl、Wikipedia、FineWeb-2、GitHub、教科书及学术论文。
- 精选数据包括:
- 10 个近期 Common Crawl 快照(CC-MAIN-2024-33 至 CC-MAIN-2025-13)的英文网络爬取数据,补充了截至 2025 年 4 月 23 日的 CC-NEWS 数据;仅保留英文,并通过模糊匹配实现全球去重。
- 15 种语言(阿拉伯语、中文、丹麦语、荷兰语、法语、德语、意大利语、日语、韩语、波兰语、葡萄牙语、俄语、西班牙语、瑞典语、泰语)的多语言数据,从三个 Common Crawl 快照中提取,经启发式过滤与 MinHash 基于的模糊去重处理;并补充 Wikipedia 与 FineWeb-2 数据。
- 数学数据通过定制化流水线处理:从 98 个 Common Crawl 快照中提取原始 HTML,使用 lynx 渲染,经 Phi-4 清洗,FineMath 过滤,并通过 LLM Decontaminator 去污染,最终生成两个语料库——Nemotron-CC-Math-3+(1330 亿 token)和 Nemotron-CC-Math-4+(520 亿 token,高质量子集)。
- 代码数据来自 GitHub,通过许可证检测过滤(仅保留宽松许可证,详见附录 A),并采用精确与模糊(MinHash LSH)去重处理;进一步通过 OpenCoder 的启发式规则过滤低价值文件。
- 合成数据包括:
- 从 GSM8K、MATH、AOPS、Stemez² 及宽松许可证教科书中生成 STEM 问题,通过三轮迭代扩展,使用 Qwen3-30B-A3B、Qwen3-235B-A22B、Deepseek-R1 与 Deepseek-V3 生成相似、更难及多样化问题;解决方案生成后通过模糊去重去除重复项。
- 使用 Nemotron-CC-Math-4+ 作为输入,重新生成 Nemotron-MIND 数据集,产出一个 730 亿 token 的合成数学对话语料库,包含结构化提示(如教师-学生、辩论)与 5K token 分块。
- 通过 Qwen3-30B-A3B 将英文 Diverse QA 翻译为 15 种语言,以及直接从多语言 Wikipedia 文章生成 QA 对,构建多语言多样化 QA 数据。
- 通过提示 LLM 从代码片段生成问题、求解并过滤,创建合成代码 QA 对,使用 AST 解析与启发式规则进行筛选。
- 从数学、化学、生物、物理与医学领域的本科及研究生教科书与论文中生成学术 QA 对;片段通过 Milvus 向量搜索嵌入与检索,用于生成带理由的多项选择与自由回答 QA 对。
- 覆盖代码、数学、MMLU 风格知识与通用指令遵循的 SFT 风格数据,源自先前工作合成。
- 基于 LSAT、LogiQA 与 AQuA-RAT 数据集生成的基础推理 SFT 数据,使用 DeepSeek-V3 与 Qwen3-30B-A3B 扩展,通过思维链生成与多数投票选择最终答案(分别生成 40 亿与 42 亿 token)。
- 预训练数据混合包含 13 个类别,权重根据数据质量分配。混合策略分为三个课程阶段:第一阶段强调多样性,第二与第三阶段优先高质量数据(如 Wikipedia)。多语言数据混合通过消融实验优化,DiverseQA-crawl(由英文翻译)因在 Global-MMLU 上表现优异而获得最高权重。
- 数据处理包括:
- 所有主要子集均使用 MinHash LSH 进行模糊去重。
- 为学术数据构建元数据,包括教育难度、学科与质量标签。
- 多语言后训练数据采用逐行翻译,结合语言识别与括号格式化,以确保质量。
- 使用稳健的验证流水线处理工具调用数据,模拟多智能体对话并采用基于规则的验证,仅保留成功轨迹。
- 模型在上述数据集混合上采用分阶段课程进行预训练,最终训练使用 DeepSeek 的 FP8 配方(张量为 E4M3,128×128 量化块,1×128 激活块),前四层与后四层线性层保持 BF16,优化器状态使用 FP32。
方法
作者为 Nemotron-Nano-12B-v2-Base 模型采用混合 Mamba-Transformer 架构,结合 Mamba-2 层、自注意力层与前馈网络(FFN)层,以平衡效率与推理能力。该模型共 62 层,其中 28 层为 Mamba-2,6 层为自注意力,28 层为 FFN。自注意力层在模型中战略性分布,如框架图所示,约占总层数的 8%。该配置旨在维持长上下文建模能力的同时,提升推理任务的推理速度。模型隐藏维度为 5120,FFN 隐藏维度为 20480,采用分组查询注意力(Grouped-Query Attention),设 40 个查询头与 8 个键值头。Mamba-2 层的架构参数为:8 个组、状态维度 128、头维度 64、扩展因子 2、卷积窗口大小 4。FFN 层使用平方 ReLU 激活函数,模型不使用位置嵌入、Dropout 或线性层偏置,而是依赖 RMSNorm 进行归一化。整体层结构与关键架构细节总结于框架图中。
Nemotron-Nano-12B-v2-Base 模型的对齐过程采用多阶段训练流水线,旨在提升指令遵循、工具调用与对话能力。流程始于三个阶段的监督微调(SFT)。第一阶段使用综合数据集,其中包含部分提示与去除推理痕迹的输出样本,使模型能在“推理关闭”模式下生成直接答案。为提升效率并保留长上下文学习能力,样本被拼接为约 128k token 的序列。第二阶段聚焦工具调用,不进行拼接以避免破坏工具调用模式的学习。第三阶段通过引入长上下文数据与突然截断推理痕迹的增强样本,强化长上下文能力,提升在不同推理时思考预算下的鲁棒性。SFT 之后,模型通过多种强化学习技术进行优化。IFEval RL 通过基于规则的验证器评分,提升指令遵循度;DPO 用于强化工具调用能力,使用 WorkBench 环境生成策略数据以支持迭代训练;RLHF 用于提升整体帮助性与聊天能力,采用 GRPO 与来自 HelpSteer3 的纯英文上下文,结合 Qwen 基础奖励模型。对齐流程如以下图表所示。
模型压缩策略扩展了 Minitron 框架,实现单个 NVIDIA A10G GPU 上超过 128k token 的推理。该过程包括重要性估计与轻量级神经架构搜索。重要性估计计算模型组件的敏感度得分,以指导剪枝决策。层重要性通过迭代移除每层并测量原始模型与剪枝模型 logits 之间的均方误差(MSE)来确定,影响最小的层优先移除。对于 FFN 与嵌入通道,重要性通过在校准数据集上对神经元与嵌入通道输出进行均值与 12-范数聚合评估。Mamba 头重要性采用嵌套激活评分策略,聚合 Wx 投影的激活得分,并在每个 Mamba 组内对头进行排序,以保留结构约束。得分最低的头被剪枝,以移除不重要组件,同时保持选择性状态空间模型(SSM)块的完整性。压缩过程还包括轻量级神经架构搜索,在 19.66 GiB 内存预算内探索多轴搜索空间,考虑深度缩减、嵌入通道宽度剪枝、FFN 维度与 Mamba 头的调整,以寻找最优架构候选。
实验
- 基础推理(FR)SFT 风格数据的消融研究显示,在持续预训练中引入 5% 的 FR-SFT 数据,使 MMLU-Pro 准确率从 44.24 提升至 56.36,平均 MATH 分数提升约 2 分,且未损害常识推理或代码基准性能。
- Nemotron-Nano-12B-v2-Base 在 20T token 范围内训练,序列长度 8192,全局批量大小 768,采用 WSD 学习率调度(稳定值:4.5×10⁻⁴,最小值:4.5×10⁻⁶),在数学推理、代码与通用推理基准上表现优异。
- 在多样化任务上的评估表明,12B 模型在 MATH-500、AIME-2024、GPQA-DIAMOND、LIVECodeBench 与 HUMANITY'S LAST EXAM 上均表现卓越,指令遵循(IFEVAL)、工具调用(BFCL v3)、长上下文(RULER)与聊天能力(ARENAHARD)均取得优异结果。
- 架构搜索识别出 56 层深度为最优,FFN 与嵌入维度的宽度剪枝足以实现压缩;候选 2(56 层,剪枝 FFN 与嵌入)在准确率与吞吐量之间取得最佳平衡。
- 知识蒸馏与分阶段训练(包括 DPO、GRPO、RLHF 与模型合并)在剪枝后恢复了准确率,最终的 Nemotron-Nano-9B-v2 模型在 A10G GPU 上相比 Qwen3-8B 实现 3×–6× 的吞吐量提升,同时在准确率上超越 Qwen3-8B,并在多数基准上与 12B 教师模型持平。
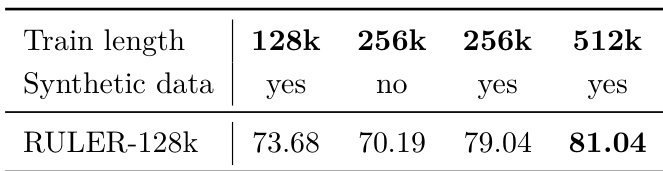
结果表明,将训练序列长度从 128k 提升至 512k,使 RULER-128k 得分从 73.68 提升至 81.04,当在 256k 与 512k 长度使用合成数据时表现最佳。在 256k 长度使用合成数据相比不使用时得分更高,表明更长上下文与合成数据均有助于提升长上下文性能。
作者通过消融研究评估了不同比例基础推理 SFT 风格数据对模型性能的影响。结果显示,将推理-SFT 数据比例从 50% 提升至 70%,平均准确率从 57.5 提升至 58.5;但进一步提升至 90% 时,准确率下降至 57.2,表明 70% 为最优比例。

作者以 12B 模型为基础,通过深度与宽度剪枝开发出压缩后的 9B 变体,显著提升推理吞吐量。剪枝模型保留 56 层,降低 FFN 与嵌入维度,实现更高吞吐量,同时保持与更大模型相当的准确率。

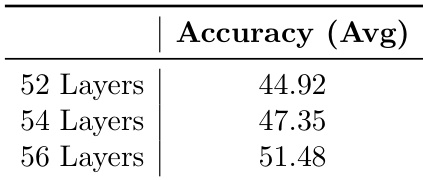
作者通过深度剪枝实验评估模型深度对推理准确率的影响,训练了三个 12B 模型变体,分别具有 52、54 与 56 层。结果表明,准确率随深度增加而提升,56 层模型达到 51.48,显著高于 52 层模型的 44.92,表明更深模型在推理任务中表现更优。
作者将 Nemotron-Nano-v2-12B 模型与 Qwen3-8B 和 Qwen3-14B 在多个推理与通用能力基准上进行对比。结果显示,Nemotron-Nano-v2-12B 在大多数任务(包括 AIME-2024、MATH-500 与 IFEval)上得分高于 Qwen3-8B,同时在与更大规模的 Qwen3-14B 模型竞争中保持竞争力。