Command Palette
Search for a command to run...
GLM-4.1V-Thinking:面向可扩展强化学习的通用多模态推理
GLM-4.1V-Thinking:面向可扩展强化学习的通用多模态推理
摘要
我们推出了GLM-4.1V-Thinking与GLM-4.5V,这是一系列面向通用多模态理解与推理的视觉语言模型(Vision-Language Models, VLMs)。在本报告中,我们分享了在构建以推理为核心训练框架过程中的关键发现。首先,我们通过大规模预训练构建了一个具备强大能力的视觉基础模型,其性能上限为最终表现设定了基准。随后,我们提出了一种基于课程采样机制的强化学习方法——课程采样强化学习(Reinforcement Learning with Curriculum Sampling, RLCS),充分释放了该模型的潜力,显著提升了其在多种任务上的综合能力,涵盖STEM问题求解、视频理解、内容识别、编程、视觉定位(grounding)、基于GUI的智能体(GUI-based agents)以及长文档解析等。在涵盖42个公开基准的全面评估中,GLM-4.5V在同类规模开源模型中几乎在所有任务上均达到当前最优水平,并在诸如编程与GUI智能体等高难度任务上,表现与闭源模型Gemini-2.5-Flash相当甚至更优。与此同时,较小规模的GLM-4.1V-9B-Thinking同样表现出色,在29个基准测试中超越了参数量远大于它的Qwen2.5-VL-72B模型。我们已将GLM-4.1V-9B-Thinking与GLM-4.5V全部开源,相关代码、模型及详细信息已发布于GitHub:https://github.com/zai-org/GLM-V。
一句话总结
智谱AI与清华大学GLM-V团队提出GLM-4.1V-Thinking和GLM-4.5V,两款基于以推理为中心的训练框架(融合课程采样强化学习)增强的视觉语言模型,在42个公开基准上实现开源模型的最先进性能,超越Qwen2.5-VL-72B等更大模型,并在编程、GUI代理和长文档理解任务中媲美Gemini-2.5-Flash等闭源模型。
主要贡献
-
本文提出GLM-4.1V-Thinking和GLM-4.5V,一类旨在提升通用多模态推理能力的视觉语言模型,重点突破以往模型仅在特定领域表现优异或缺乏可扩展推理能力的局限。
-
作者提出课程采样强化学习(Reinforcement Learning with Curriculum Sampling, RLCS),一种多领域强化学习框架,根据模型能力动态选择任务,实现高效且稳定的训练,显著提升在STEM推理、编程、GUI代理和长文档理解等多样化任务上的性能。
-
在42个公开基准的评估中,GLM-4.5V在同规模开源模型中达到最先进水平,性能可与Gemini-2.5-Flash等闭源模型比肩;而更小的GLM-4.1V-9B-Thinking在29个基准上超越了Qwen2.5-VL-72B等更大模型。
引言
视觉语言模型(VLMs)对于能够同时理解视觉与文本信息的智能系统至关重要,其在科学问题求解、自主代理开发和复杂文档理解等多样化任务中对高级推理能力的需求日益增长。以往提升VLM推理能力的方法往往局限于特定领域,或难以有效扩展,开源社区长期缺乏一种能持续超越同规模非推理基线的通用多模态推理模型。本文提出GLM-4.1V-Thinking和GLM-4.5V,一类通过统一的可扩展强化学习训练框架实现多功能、通用推理的新一代VLM。其核心创新在于课程采样强化学习(RLCS),一种基于模型能力动态选择任务的多领域强化学习策略,显著提升训练效率与跨领域泛化能力。模型在多样化、知识密集型的多模态数据集上训练,并通过结构化推理提示进行微调,最终在42个基准上实现最先进性能,超越Qwen-2.5-VL-72B等更大模型,媲美甚至超越Gemini-2.5-Flash等闭源模型。作者开源了多个变体,包括9B参数的思考型模型和总参数106B(激活参数12B)的模型,以及预训练基础模型和领域特定奖励系统,推动多模态推理领域的更广泛研究与开发。
数据集
-
数据集由五个核心模态的多个高质量、精心筛选的数据源构成:图像描述、图文交错、OCR、视觉定位、视频以及指令微调数据。
-
图像描述数据源自超过100亿张图像-文本对,整合自LAION、DataComp、DFN、Wukong及网络搜索引擎。数据经过四阶段精炼:启发式过滤(分辨率、色彩、长度、去重)、基于CLIP的相关性过滤(得分 > 0.3)、概念平衡重采样以缓解长尾分布问题,以及通过迭代模型进行以事实为中心的重描述以提升描述质量。最终数据集以固定比例合并原始与重描述数据。
-
图文交错数据来自网络来源(MINT、MMC4、OmniCorpus)和数字化学术书籍。网络数据通过CLIP-Score阈值、启发式规则及自定义图像分类器清洗,去除广告与二维码。高知识密度分类器识别信息丰富的图像(如图表、示意图)。学术书籍按STEM相关性筛选,并使用PDF工具解析提取结构化图像-文本对。
-
OCR数据包含来自三个来源的2.2亿张图像:合成文档图像(在LAION背景上渲染文本)、自然场景文本(Paddle-OCR结合边界框过滤)以及学术文档(arXiv论文经LaTeX2XML、HTML解析并栅格化为配对的PDF渲染图与标记)。
-
定位数据包含来自LAION-115M的4000万张自然图像标注,使用GLIPv2预测名词短语的边界框(保留至少包含两个框的样本),以及通过Playwright驱动的网页交互生成的超过1.4亿个GUI特定QA对,捕捉DOM元素与Referring Expression任务所需的精确边界框。
-
视频数据来自学术、网络及专有来源,经细粒度人工标注动作、场景内文本、摄像机运动与镜头构图。采用基于多模态嵌入的去重策略,移除语义冗余对,确保数据纯净。
-
指令微调数据包含5000万样本,涵盖视觉感知、多模态推理(如STEM)、文档理解、GUI操作与UI编程。数据通过细粒度分类体系多样化,复杂场景(如GUI交互)通过合成数据增强,并严格检查是否污染自公开基准。
-
为监督微调,构建了5000万样本的推理数据集,采用标准化响应格式: </tool_call> {think_content} </tool_call> {answer_content} 。可验证任务要求最终答案置于 <begin_of_box> 与 <end_of_box> 之间。为解析添加特殊标记至分词器。数据集经清洗以强制格式规范,移除多语言内容,并消除噪声推理模式。
-
数据准备遵循结构化流程:任务识别(如时间定位 vs 开放式描述)、数据整理(将多选题转为填空题)、质量验证(pass@k评估与人工难度分级),以及初步强化学习实验以确认数据效用与模型提升潜力。
-
最终训练混合采用这些数据集的均衡组合,特定比例经调优以优化模型性能。处理包括裁剪策略(如聚焦信息丰富的图像区域)、元数据构建(如结构化DOM与边界框标注),并通过将高质量强化学习生成样本迭代融入冷启动数据集实现持续增强。
方法
作者为GLM-4.1V-Thinking和GLM-4.5V设计了模块化架构,以处理包括图像、视频和文本在内的多样化多模态输入。该框架包含三个主要组件:视觉编码器、MLP投影器和大语言模型(LLM)解码器。视觉编码器基于视觉Transformer(ViT),处理视觉输入,并以AIMv2-Huge初始化。为支持任意图像分辨率与宽高比,模型在ViT的自注意力层中集成2D-RoPE,有效处理极端宽高比与高分辨率图像。此外,模型保留原始可学习的绝对位置嵌入,并通过双三次插值动态适应可变分辨率输入。该适应过程将补丁坐标归一化至覆盖 [−1,1] 的连续网格,然后使用双三次插值函数从原始位置嵌入表中采样,生成每个补丁的最终适配嵌入。

对于视频输入,模型采用两倍的时间下采样策略,方法类似Qwen2-VL,将原始2D卷积替换为3D卷积,从而高效处理视频序列。为增强时间理解能力,在每帧令牌后插入时间索引令牌,时间索引以表示帧时间戳的字符串形式编码。该设计明确告知模型真实世界的时间戳与帧间时间距离,从而提升其时间定位能力。MLP投影器将ViT编码器提取的视觉特征对齐至文本令牌空间,实现视觉与文本信息的融合。LLM解码器作为语言模型,处理多模态令牌并生成令牌补全。作者将RoPE扩展至3D-RoPE,进一步增强语言侧的空间感知能力,在保持原始模型文本相关能力的同时,为多模态上下文提供更优的空间理解。
实验
-
采用32,768令牌序列长度与全局批量大小32进行全参数微调,使用跨多个领域(数学、多轮对话、代理规划、指令遵循)的多样化长文本推理数据。通过特殊标记 /nothink 实现思维与非思维模式混合,非思维模式使用思维示例中的 内容进行训练,性能优于精心筛选的子集。
-
在所有多模态领域(STEM、OCR、视频理解、GUI代理、逻辑推理)中均采用可验证奖励强化学习(RLVR)与人类反馈强化学习(RLHF),以增强模型能力。
-
识别出强化学习中的关键稳定性因素:高质量的冷启动SFT数据至关重要;移除熵损失以防止输出混乱;采用 top-p = 1 以实现稳定滚动;采用样本级损失计算以提升训练稳定性;强调在SFT阶段学习输出格式,而非依赖RL。
-
在8个类别共42个公开基准上评估GLM-4.5V:通用VQA、STEM、OCR与文档、视觉定位、空间推理、GUI代理、编程、视频理解,使用vLLM与SGLang进行推理,输出限制为8,192令牌,采用框式答案提取。
-
在所有基准上,GLM-4.5V在开源模型中达到最先进水平,显著超越Qwen-VL、Kimi-VL、Gemma-3等模型,尤其在STEM(MMMU、AI2D)、OCR与文档(ChartQAPro、MMLongBench-Doc)、GUI代理和视频理解(VideoMME、MMVU)方面表现突出。
-
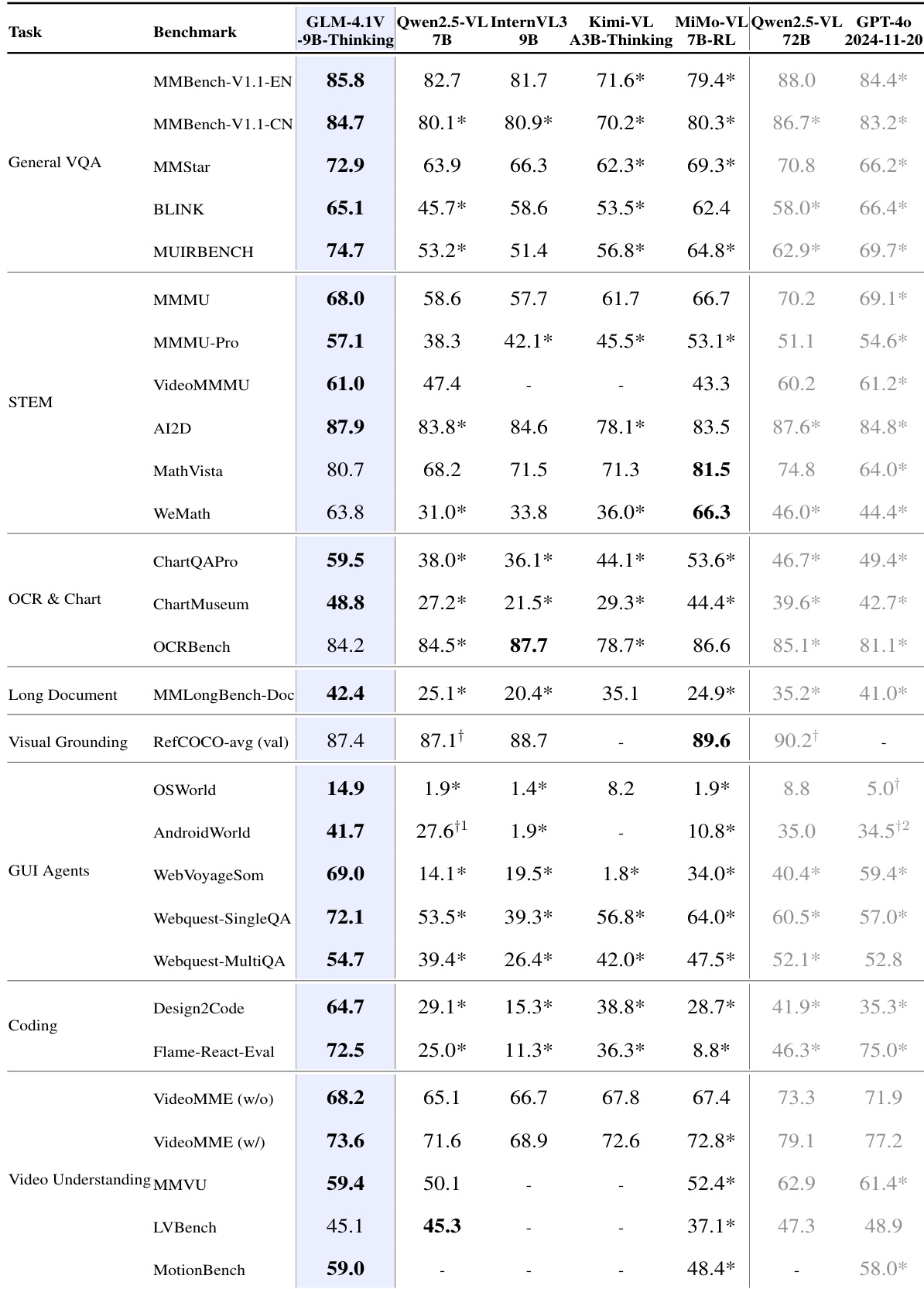
GLM-4.1V-9B-Thinking在42个基准中的29个上超越更大模型Qwen2.5-VL-72B,包括MMMU Pro和ChartMuseum等挑战性任务,展现出卓越的效率与性能。
-
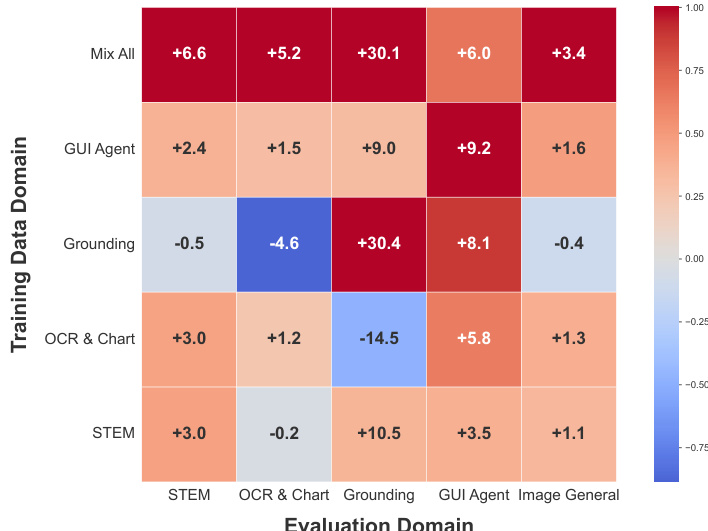
跨领域强化学习实验揭示强互促效应:在一个领域(如STEM、OCR与图表、GUI代理)训练可提升其他领域表现,其中GUI代理强化学习显著提升所有领域,表明存在共享底层能力。在所有领域联合训练在STEM、OCR与图表及通用VQA上取得最高增益,但定位与GUI代理性能未提升,提示需采用专门策略。
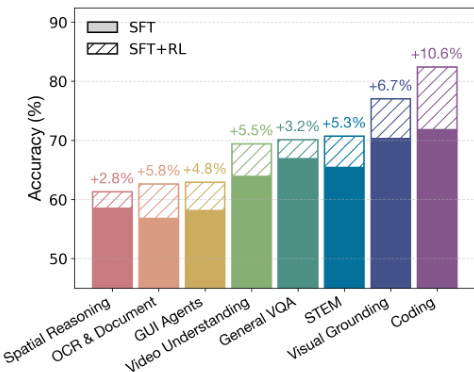
作者使用柱状图展示GLM-4.5V在强化学习(RL)后于多个多模态领域中的性能提升。结果显示,SFT+RL阶段在所有领域均持续提升准确率,其中编程(+10.6%)、视觉定位(+6.7%)和STEM(+5.3%)提升最为显著。各领域性能提升表明,RL有效增强了模型在推理、感知与跨模态理解方面的能力。
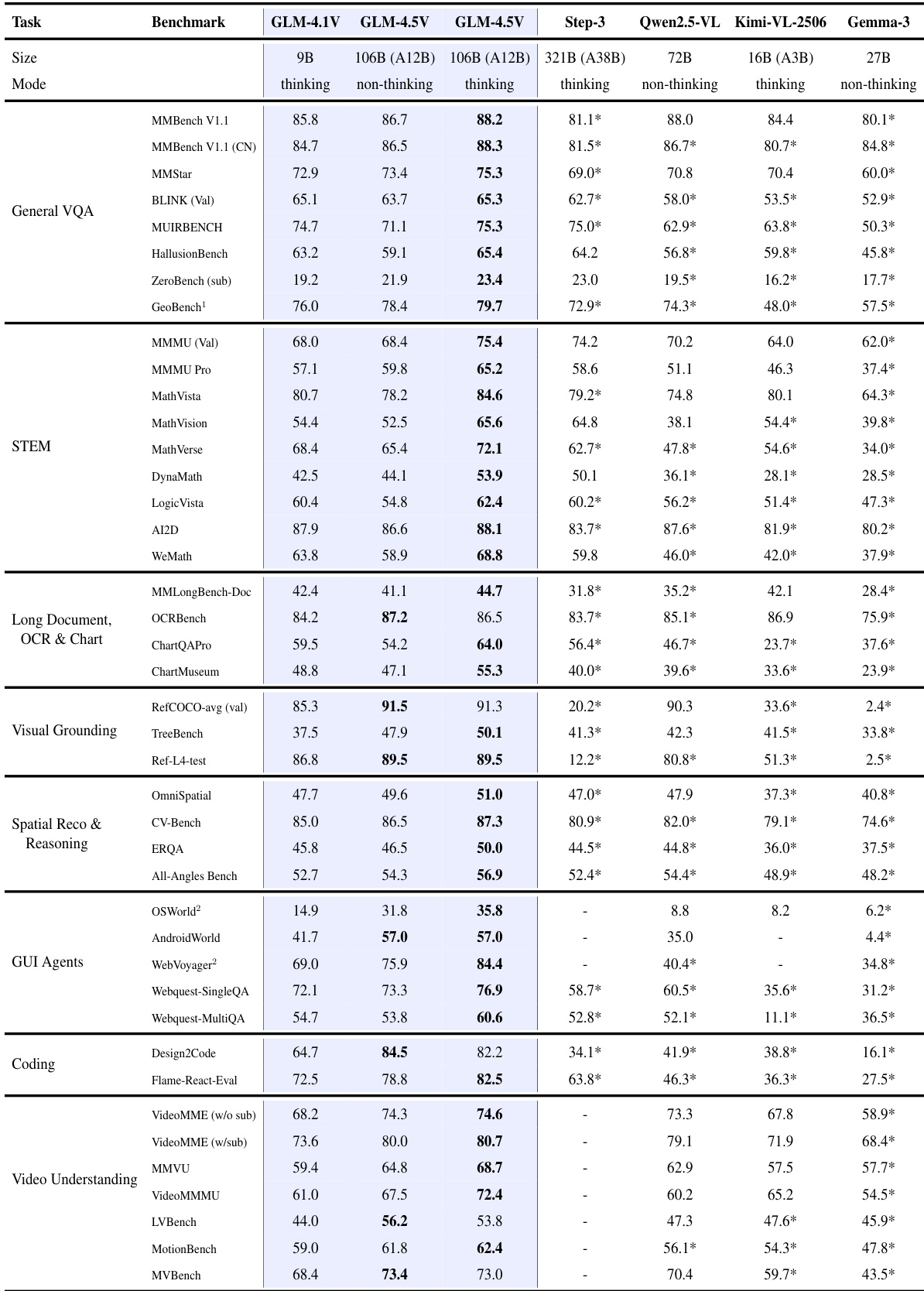
作者使用涵盖八个类别的42个综合基准评估GLM-4.5V与GLM-4.1V-Thinking,并与多个开源模型进行对比。结果表明,GLM-4.5V在所有基准上均达到最先进水平,展现出在多模态推理方面的持续优势,尤其在STEM、OCR与文档理解以及GUI代理任务中表现突出。
作者使用涵盖八个类别的42个综合基准评估GLM-4.5V与GLM-4.1V-Thinking,并与多个开源模型进行对比。结果表明,GLM-4.5V在所有基准上均达到最先进水平,展现出强大的多模态推理与泛化能力。
作者采用多领域强化学习设置评估GLM-4.1V-9B-Thinking的跨领域泛化能力,分别在单个领域训练模型并评估其在所有领域上的表现。结果表明,单一领域训练可提升其他领域性能,“Mix All”配置在STEM、OCR与图表及通用VQA上取得最高增益,表明各领域间存在强互促关系。