Command Palette
Search for a command to run...
OmniGen2:从探索到先进的多模态生成
OmniGen2:从探索到先进的多模态生成
摘要
在本工作中,我们提出OmniGen2,一个多功能且开源的生成模型,旨在为多种生成任务提供统一解决方案,涵盖文本到图像生成、图像编辑以及上下文感知生成(in-context generation)。与OmniGen v1不同,OmniGen2为文本和图像模态分别设计了两条独立的解码路径,采用非共享参数结构并引入解耦的图像分词器(image tokenizer)。这一架构设计使OmniGen2能够在不重新适配VAE输入的前提下,基于现有的多模态理解模型进行构建,从而有效保留原始文本生成能力。为支持OmniGen2的训练,我们构建了完整的数据构造流水线,涵盖图像编辑与上下文感知生成任务所需的数据。此外,我们针对图像生成任务设计了一种独特的反思机制(reflection mechanism),并基于OmniGen2自身生成结果构建了一个专用的反思数据集。尽管参数规模相对较小,OmniGen2在多个任务基准测试中仍取得了具有竞争力的性能表现,涵盖文本到图像生成与图像编辑任务。为进一步评估上下文感知生成(亦称主体驱动任务)的能力,我们提出了一个新的基准测试集——OmniContext。在该基准上,OmniGen2在开源模型中展现出当前最优的一致性表现。我们计划公开发布模型权重、训练代码、数据集以及数据构造流水线,以推动该领域的后续研究。 项目主页:https://vectorspacelab.github.io/OmniGen2GitHub链接:https://github.com/VectorSpaceLab/OmniGen2
一句话总结
来自北京人工智能研究院及合作机构的作者提出 OmniGen2,一个轻量级开源生成模型,采用解耦的文本与图像解码路径及非共享参数,实现保留文本生成能力并提升多模态任务中的一致性;该模型引入了一种新颖的反思机制和 OmniContext 基准测试,在上下文生成与图像编辑的开源基准测试中达到最先进性能。
主要贡献
-
OmniGen2 引入解耦架构,为文本与图像模态分别设计独立解码路径,使用非共享参数和专用图像分词器,使其能够利用预训练的多模态理解模型,无需重新适配 VAE 输入,同时保持强大的文本生成能力。
-
模型在从视频源构建的新颖高质量数据集上进行训练,用于图像编辑与上下文生成,并引入专为迭代图像优化设计的反思机制,其支持数据集由 OmniGen2 自身生成并精心筛选。
-
OmniGen2 在新提出的 OmniContext 基准测试中,于开源模型中达到最先进性能,展现出卓越的一致性;尽管参数量相对较小,其在标准文本到图像生成与图像编辑基准测试中仍表现具有竞争力。
引言
作者在 OmniGen2 中采用解耦架构,实现文本到图像合成、图像编辑与上下文生成的统一多模态生成,解决了以往统一模型常牺牲文本生成质量或需大量重训练的局限。与早期依赖共享参数或端到端训练多模态组件的方法不同,OmniGen2 使用非共享解码器和专用图像分词器,通过基于预训练多模态理解模型构建,无需重新适配 VAE 输入,从而保留强大的文本生成能力。先前研究中缺乏高质量、任务特定数据以支持上下文生成与高级编辑的问题,通过新颖的数据构建流程及 OmniContext 基准测试得以缓解——该基准测试是面向主题驱动图像生成的综合性评估体系。作者进一步在模型中集成反思机制,实现图像输出的迭代优化,并发布完整模型、代码、数据集与训练基础设施,以推动多模态生成领域的开放研究。
数据集
-
数据集由开源与专有来源混合构建,包括 Recap-DataComp、SAM-LLaVA、ShareGPT4V、LAION-Aesthetic、ALLaVA-4V、DOCCI、DenseFusion、JourneyDB 和 BLIP3-o,总计约 1.4 亿张开源图像。此外,还包含 1000 万张专有图像,其合成标注由 Qwen2.5-VL-72B 生成。
-
针对上下文生成,使用视频数据创建训练对,确保在不同姿态、视角与光照下主体一致。从视频中提取关键帧,选定基准帧并使用 Qwen2.5-VL-7B-Instruct 识别主要主体。GroundingDINO 生成主体边界框,SAM2 实现跨帧分割与追踪。选择最后一个包含所有主体的有效帧以最大化外观变化。基于视觉语言模型(VLM)的过滤步骤确保主体一致性,FLUX.1-Fill-dev 用于将主体外扩至新背景。基于 DINO 的相似性过滤去除异常值,Qwen2.5-VL-7B-Instruct 评估语义质量与一致性。生成对象描述与标题,并整合为自然语言指令,形成训练三元组:指令、重绘图像(输入)、原始图像(输出)。
-
针对基于内补的编辑,从文本到图像数据中选取高质量图像,使用 FLUX.1-Fill-dev 进行内补,不输入指令,确保内容随机填充。内补图像作为输入,原始图像作为目标,保证高质量输出。随后由多模态大语言模型(MLLM,Qwen2.5-VL)生成编辑指令,利用其强大的指令遵循能力,生成准确且高保真的指令-图像对。
-
交错帧序列源自在场景切换处分割的视频片段。生成两类序列:同场景(within same scene)与跨场景(across different scenes),每类最长五帧。连续帧对使用 Qwen2.5-VL-7B-Instruct 生成描述性标题,捕捉物体动作、环境与外观的变化。共生成 80 万条交错数据样本,用于连续多模态序列的预训练。
-
OmniContext 基准测试是人工精心筛选的高质量数据集,旨在评估多种上下文类型下的图像生成。包含个人照片、开源图像、动画截图与 AI 生成图像,覆盖三类:角色(Character)、物体(Object)与场景(Scene)。支持三种任务类型——SINGLE、MULTIPLE 与 SCENE,每类含八个子任务(每个子任务 50 个样本)。图像-提示对通过混合方法生成:先由 MLLM 初步筛选,再由人工基于主体清晰度、美学质量与多样性进行精修。提示由 GPT-4o 生成,并由标注者进一步优化以增强语义与句法多样性。
-
OmniContext 的评估使用 GPT-4.1,采用三项指标:提示遵循度(PF)、主体一致性(SC)与综合得分(PF 与 SC 的几何平均值),均在 0–10 分制下评分,并附详细推理。相比传统图像级指标(如 CLIP-I 或 DINO),该方法显著提升可解释性与准确性。
方法
作者为 OmniGen2 设计模块化架构,旨在解耦文本与图像生成路径,同时保持强大的多模态理解能力。核心框架如图所示,由自回归 Transformer 与扩散 Transformer 组成,分别处理不同模态。自回归 Transformer(初始化为 Qwen2.5-VL-3B)处理文本与视觉输入。文本生成采用自回归语言头,图像生成由特殊标记 <limg> 触发,该标记通知扩散解码器合成图像。自回归 Transformer 的隐藏状态作为条件输入传递给扩散解码器。为增强解码器的视觉保真度,模型引入对输入图像应用变分自编码器(VAE)提取的特征。该设计使 MLLM 能在无需复杂架构修改或重新训练的情况下,保留其多模态理解能力。
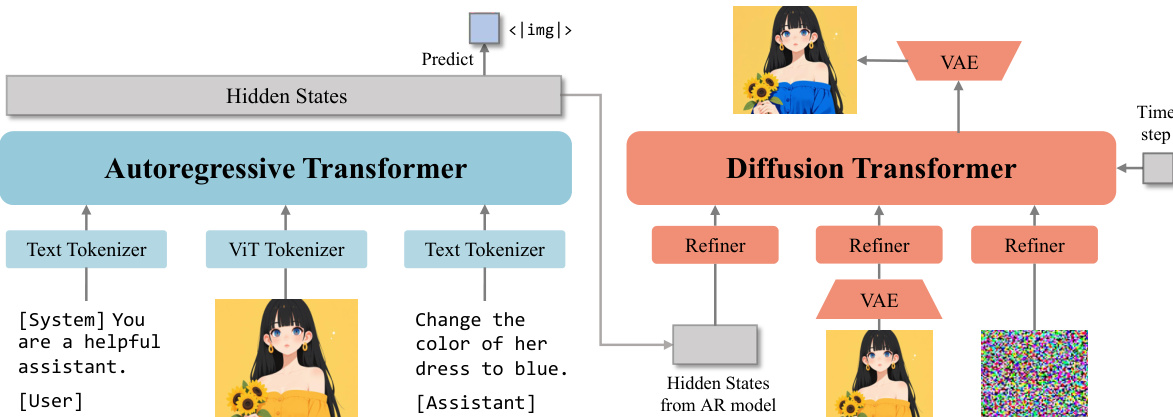
扩散 Transformer 如图所示,采用简单架构,直接拼接来自 MLLM、VAE 与噪声的特征,实现对多模态的联合注意力。为确保多输入条件对齐,引入一个精炼网络在输入传递至 Transformer 层前进行处理。扩散解码器由 32 层组成,隐藏层大小为 2520,总参数量约 40 亿。为降低计算开销,模型丢弃 MLLM 中与图像相关的隐藏状态,仅保留与文本标记相关的状态,因显式引入 VAE 特征后,MLLM 的图像相关状态已非关键。扩散 Transformer 采用 3D 旋转位置编码(3D rotary position embedding),为 Qwen mRoPE 的改进版本,专为应对多模态任务中复杂的定位需求而设计。

作者提出一种新颖的多模态旋转位置编码——Omni-RoPE,以应对多样化复杂任务中的位置编码挑战。如图所示,Omni-RoPE 将位置信息分解为三个部分。第一部分为序列与模态标识符(idseq),在单张图像内所有标记中保持恒定,将其视为语义单元,不同图像间唯一。对于文本标记,该 ID 作为标准 1D 位置索引。第二与第三部分为 2D 空间高度(h)与宽度(w)坐标,从每张图像实体的 (0,0) 点局部归一化计算。该双重机制使模型能通过唯一 idseq 明确区分不同图像,同时共享局部空间坐标增强图像编辑等任务的一致性。对于非图像标记,空间坐标 (h,w) 均设为零,使该设计可无缝退化为纯文本输入的标准 1D 位置编码。
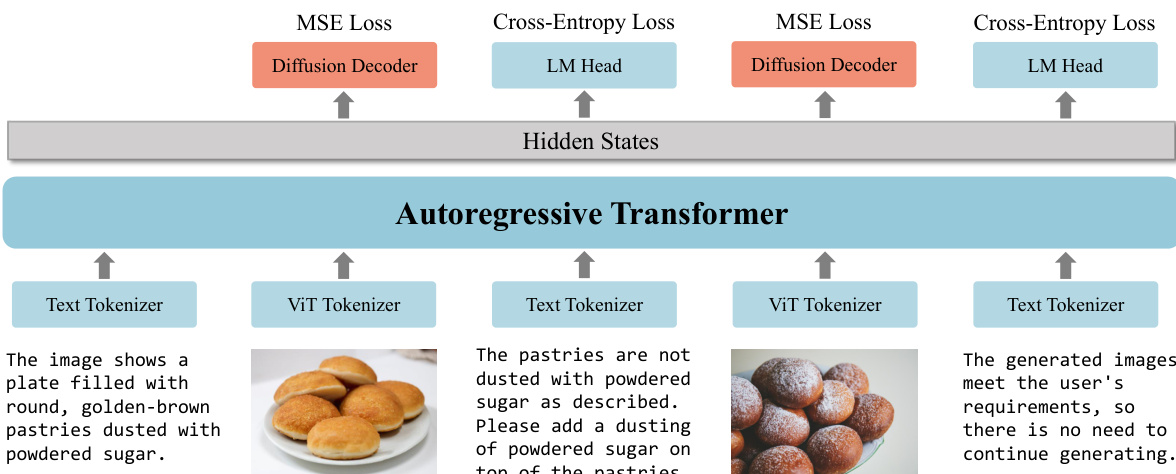
OmniGen2 的训练策略旨在保留 MLLM 强大的视觉理解能力的同时,高效训练扩散模块。MLLM 初始化为 Qwen2.5-VL,训练过程中其大部分参数保持冻结,仅更新新引入的特殊标记“”。该方法确保模型原生多模态理解能力完全保留。扩散模型从零开始训练,先在文本到图像(T2I)生成任务上训练,随后采用混合任务训练策略以支持多目标。在反思训练阶段,所有模型参数解冻,使模型能够生成反思性文本描述并迭代优化图像输出。训练过程包含多种损失函数,包括扩散解码器的 MSE 损失与语言模型头的交叉熵损失,如图所示。模型在文本到图像与上下文生成数据组合上训练,扩散解码器学习基于 MLLM 隐藏状态与 VAE 特征生成图像。
实验
- OmniGen2 在视觉理解、文本到图像生成、图像编辑与上下文生成方面表现出统一性能,实现良好平衡,并在上下文生成任务中表现突出。
- 在 GenEval 上,OmniGen2 搭配 LLM 重写器取得 0.86 的综合得分,超越 UniWorld-V1(0.84),接近 BAGEL(0.88),仅使用 40 亿可训练参数与 1500 万 T2I 对。
- 在 DPG-Bench 上,OmniGen2 得分为 83.57,优于 UniWorld-V1(81.38),接近 SD3-medium(84.08),证实其强大的长提示遵循能力。
- 在 Emu-Edit 上,OmniGen2 取得最高 CLIP-Out 得分(0.309)与第二高 CLIP-I(0.876)与 DINO(0.822),表明其编辑准确率与图像保留能力卓越。
- 在 GEdit-Bench 上,OmniGen2 综合得分为 6.41,SC 得分高达 7.16,但在人像美化(5.608)与文本修改(5.141)任务上表现较低,表明数据存在局限。
- 在 ImgEdit-Bench 上,OmniGen2 在开源模型中创下新纪录,各项任务表现均强劲。
- 在提出的 OmniContext 基准测试中,OmniGen2 综合得分为 7.18,超越所有开源基线模型,在单图、多图与场景任务中均在提示遵循与主体一致性上表现领先。
- 反思能力使 OmniGen2 能纠正初始图像缺陷,尤其在颜色、数量与形状方面,但因感知能力与训练数据有限,存在过度反思或未能纠正的情况。
- 局限包括中英文提示性能差异、人体形态修改困难、对输入图像质量敏感、多图像输入歧义以及上下文生成中对象再现不完美。
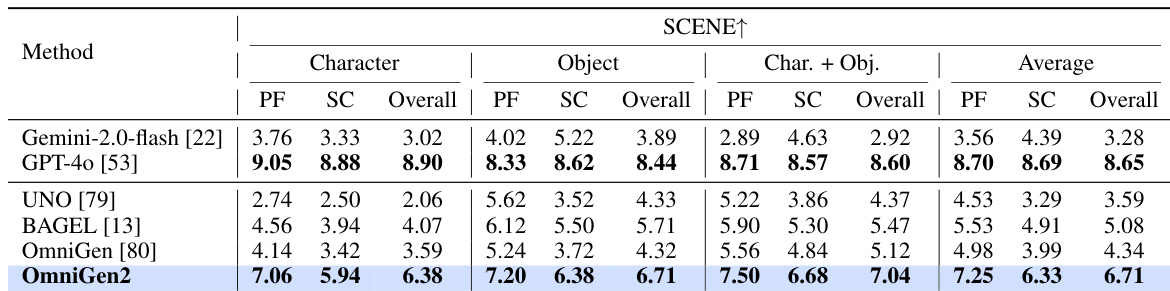
结果显示,OmniGen2 在 OmniContext 基准测试的 SCENE 任务中取得最高综合得分 6.71,超越所有对比模型在所有子任务上的表现。其在提示遵循与主体一致性方面表现强劲,尤其在角色(7.25)与物体(7.20)类别中表现突出。
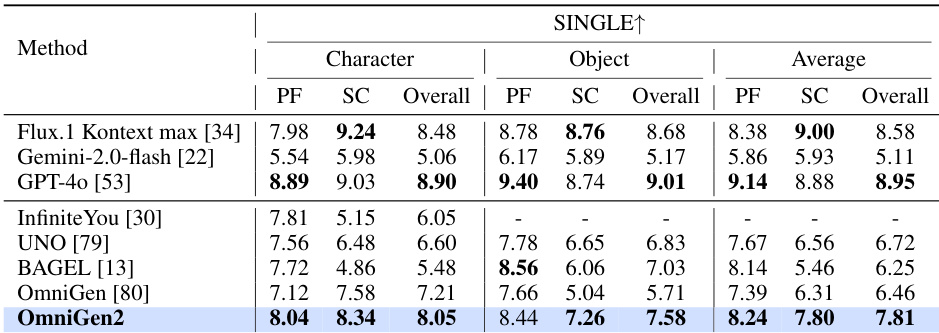
作者使用 OmniContext 基准测试评估上下文生成能力,结果显示 OmniGen2 综合得分为 7.18,超越所有开源模型在所有子任务上的表现,展现出强大的提示遵循能力与主体一致性。其相比现有模型有显著提升,尤其在单图与多图输入处理上,尽管闭源模型如 GPT-4o 与 Flux.1 Kontext 在特定指标上得分更高。
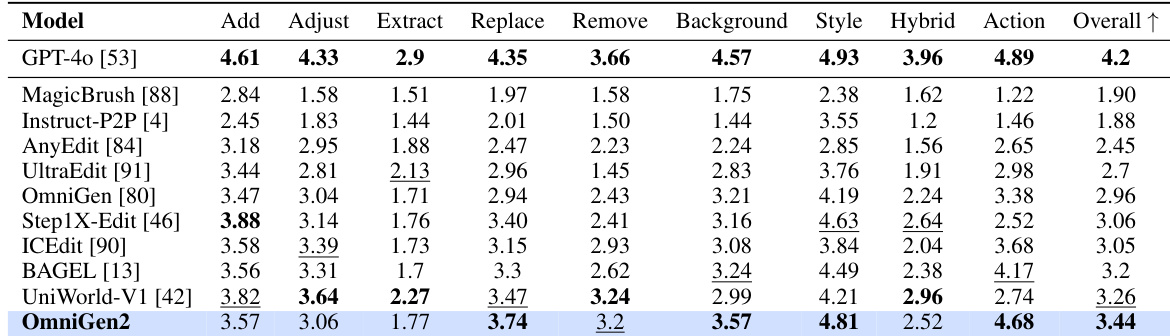
结果显示,OmniGen2 在 OmniContext 基准测试的 MULTIPLE 任务类型中各项指标均取得最高分,超越开源与闭源模型。作者使用此表展示 OmniGen2 在涉及多图像的上下文生成任务中卓越的提示遵循能力与主体一致性。
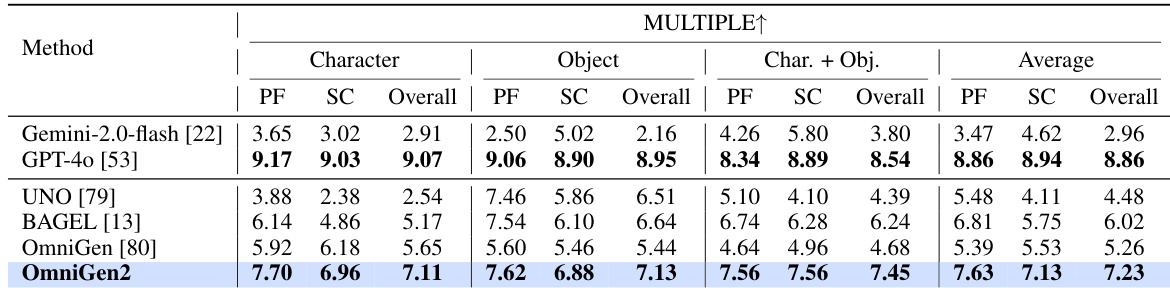
作者使用表格对比 OmniGen2 与现有模型在多个任务上的表现,显示 OmniGen2 在上下文生成任务中表现强劲,尤其在 Single 与 Multiple 任务类型中得分分别为 7.81 与 7.23。结果显示,OmniGen2 在图像生成与编辑任务中也表现具有竞争力,在 GenEval 与 DPG-Bench 上得分较高,并在 Emu-Edit 与 ImgEdit-Bench 等图像编辑任务中超越其他模型。
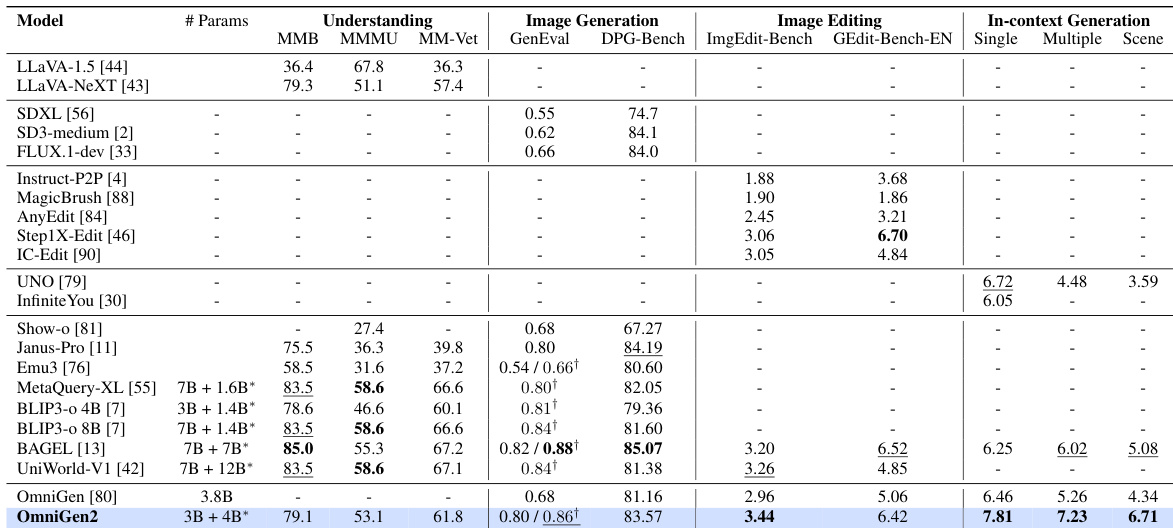
结果显示,OmniGen2 在 OmniContext 基准测试中各项评估指标均表现优异,尤其在提示遵循与主体一致性方面表现突出。其超越所有开源模型,整体排名位居前列,展现出卓越的上下文生成能力。